C2S is now open for everyone.
The biological LLM that learns the language of cells. Free for academic and commercial use.
https://t.co/I2OYXmQ0x3
Join the growing community building with C2S. 🌱
An exciting milestone for AI in science: Our C2S-Scale 27B foundation model, built with @Yale and based on Gemma, generated a novel hypothesis about cancer cellular behavior, which scientists experimentally validated in living cells.
With more preclinical and clinical tests, this discovery may reveal a promising new pathway for developing therapies to fight cancer.
An exciting milestone for AI in science: Our C2S-Scale 27B foundation model, built with @Yale and based on Gemma, generated a novel hypothesis about cancer cellular behavior, which scientists experimentally validated in living cells.
With more preclinical and clinical tests, this discovery may reveal a promising new pathway for developing therapies to fight cancer.
🚀 Beyond excited to announce our release of the #Cell2Sentence (C2S) API and new foundation models! 🎉 Our C2S API makes it incredibly easy to convert #singlecell data into cell sentences, perform inference with LLM-based C2S models, fine-tune them, and convert cell sentences back into expression data—all in one seamless workflow. 🧬
We're releasing powerful new 410M parameter models designed for diverse tasks, including cell type prediction, cell generation, cell annotation, and cell embedding! 🌟
But there’s more: We provide the first foundation model that can encode multiple cells in context, opening up completely new possibilities in single-cell analysis! 🦄
Check out our tutorials to get started, explore the models on Hugging Face, and read the manuscript for more details. We can’t wait to see the innovative applications the community will dream up with these new tools. Stay tuned—more updates are on the way!
🔗 https://t.co/Lpk9flF2UF
📝 https://t.co/cbjFB5TmJr
🤗 https://t.co/MJ95K1r7Fo
Excited to share this work - a new way to apply foundation models to graph structured data.
Please reach out if interested in bringing any of these techniques to your data or use case!
💡 Want to leverage the power of foundation models in graphs?
🔥 Introducing Foundation-Informed Message-Passing (FIMP), a framework for applying any pre-trained transformer-based foundation model to Graph Neural Networks!
https://t.co/JEJTNV90L9
Delighted to share our latest work on #longCOVID - sex differences in symptoms and immune signatures. Led by @SilvaJ_C@taka_takehiro @wood_jamie_1 et al. with @LeyingGuan & @PutrinoLab. We find a striking inverse correlation btw testosterone levels and symptom burden👇🏼 (1/)
https://t.co/XUGHcnVJKJ
Delighted to share our latest work on #longCOVID - sex differences in symptoms and immune signatures. Led by @SilvaJ_C@taka_takehiro @wood_jamie_1 et al. with @LeyingGuan & @PutrinoLab. We find a striking inverse correlation btw testosterone levels and symptom burden👇🏼 (1/)
https://t.co/XUGHcnVJKJ
@ylecun@yaroslavvb The problem with this assertion is that there are many other places where information can be encoded in the zygote beyond germline sequence - e.g. the physical orientation of DNA within the nucleus, subcellular sequestration of premade proteins etc. These are >>8MB
It's been over a year now since I first proposed cell2sentence (https://t.co/WDVEbEsumq) - a universal framework that allows *any LLM* to interface with single cell data. Now, together with @david_van_dijk and some incredibly talented students, I'm excited to share major progress
Major Cell2Sentence update 🎉🔬! We’ve been thrilled to see the attention Cell2Sentence has received from the single-cell community.
Now, we’re excited to release our first update of Cell2Sentence (C2S) - a framework to leverage LLMs to train foundational single-cell models, directly in text.
What’s new & out:
Updated preprint with latest results https://t.co/cbjFB5TmJr
First full cell model available on the HuggingFace hub https://t.co/3kcQzUo7Tm
Updated codebase for data transformation & training https://t.co/E8VaXmgYWf
We now fine-tune language models to generate entire cells, predict combinatorial cell labels, and generate textual data insights directly from cell sentences.
We train GPT-2 and Pythia models on a large multi-tissue dataset containing 36M cells from @cellxgene as well as an immune tissue dataset containing 270k cells.
C2S LMs achieve SOTA performance in single-cell data generation.
C2S models trained for combinatorial label prediction settings excel in low-data regimes, outperforming single-cell foundation model baselines.
We also show that C2S models benefit from natural language pre-training and always outperform models trained from scratch on cell sentences.
C2S provides a straightforward approach to adapting LLMs for single-cell data analysis, leveraging their natural language capabilities to generate and derive insights from single cells.
We are convinced that C2S’ approach of integrating data modalities through text is the way forward for single-cell foundation models, from representing multi-omics data to generating clinical insights, all in a human readable format.
We’re excited to start building a community around Cell2Sentence! If you also think that C2S will be the framework for single-cell foundation models, and are interested in contributing, reach out to us! We welcome any collaborations and discussions.
Huge thanks to our collaborator @aminkarbasi and the C2S team (@danielflevine, @sachalevy3, @SyedARizvi5688, @nazreenpm, Xingyu Chen, @dzhang03, @GhadermarziSina, Ruiming Wu, Ivan Vrkic, Anna Zhong, Daphne Raskin, Insu Han, @aho_fonseca, @josueortc) for their hard work on C2S! Special thanks to @rahuldhodapkar, who co-supervises this project.
Some very cool insights here into the intersection between human labeling and other distance-based "unsupervised" approaches to classification! Exciting work!
How to infer human labelling of a given dataset in a model-agnostic way?
Check our new method HUME accepted at @NeurIPSConf as #spotlight!🌟 HUME provides a new view to tackle unsupervised learning.
Kudos to my fantastic PhD student @artygadetsky!
Paper https://t.co/ILNk2mJQm0
Extremely excited to share our work on #LongCovid, now out in #Nature! I'm honored to be part of an amazing team contributing to our knowledge of a disease affecting so many lives worldwide. Very clear that this disease has *objectively measurable* immune characteristics.
So pleased to report that our Mount Sinai-Yale long COVID (MY-LC) paper with @putrinolab & others is now published!! Proud of the hard work of all who contributed. We found biological signatures that can distinguish people with vs. without #longCOVID (1/) https://t.co/t8ARWBKLsQ
Very proud to share this collaboration with @david_van_dijk and team, where we show a new fundamental approach that allows language-pretrained LLMs to be used *without architectural modifications* to learn from #singlecell data. Please check it out!
Introducing BrainLM 🧠🤖the first foundation model for #fMRI analysis trained on 6,700 hours of brain activity data! Fine-tune for specialized tasks or leverage zero-shot inference capabilities!
@WuTsaiYale@YaleCompsci@YaleCBB@YaleMed
https://t.co/MUobqXULfb
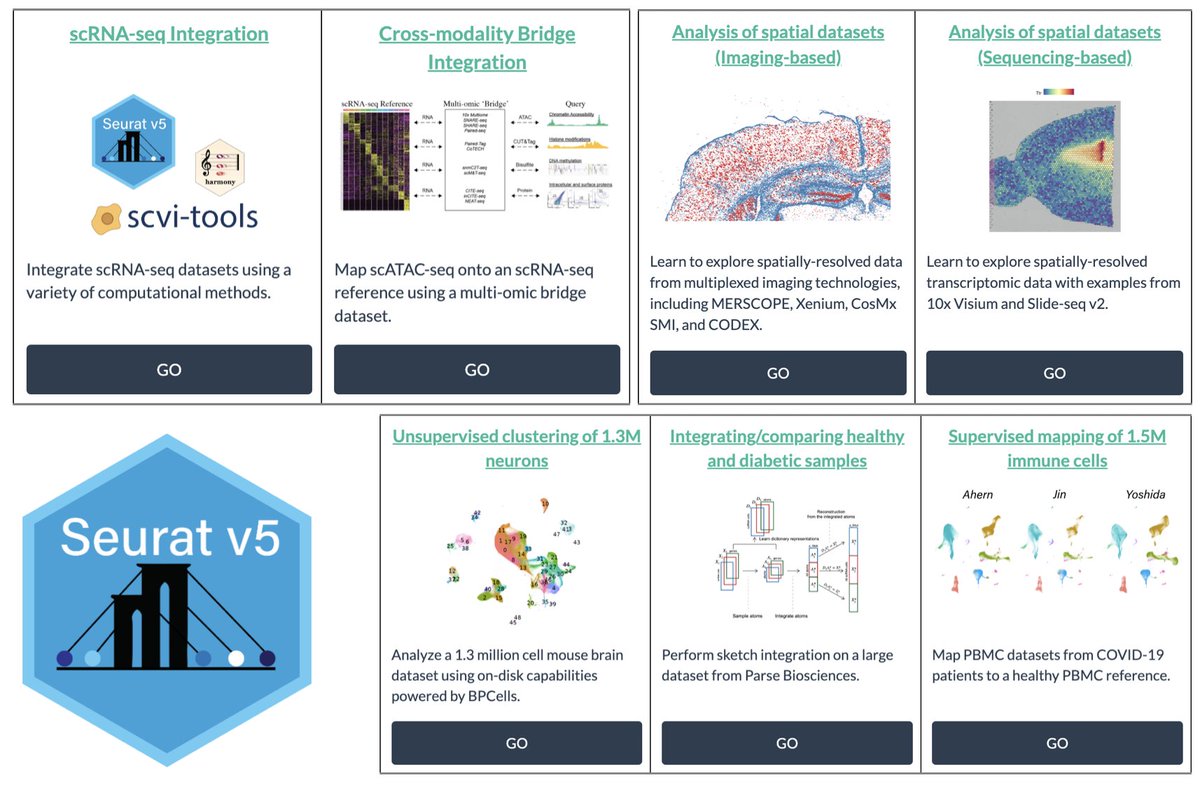
We are excited to release Seurat v5- with new methods for multimodal, spatially resolved, and massively scalable single-cell analysis. https://t.co/7BMGF7x1wV
I've been playing around with using #ChatGPT to help think about and process differential expression gene lists and found that very simple prompts are able to do reasonably well in generating high-level overviews of known gene functions, just pasting from #Seurat `FindMarkers`
When asked to generate citations/supporting evidence for the purported functions, ChatGPT confidently generates some bogus references, but I think it's still a great way to broaden thinking, and identify new processes to follow up on using good old-fashioned PubMed search