وشلون قدرت استخرج بيانات من الموقع الى الاكسل بضغطة زر وحدة!🤯
اسمها ال Web Scraping راح انشر كيف ان شاء الله
كثير ناس يبون يسحبون بيانات من المواقع بس ينقلونها حبه حبه وهذا متعب الشرح الليله بيكون بأداة رهيبه
بس ضغطة زر وحدة
هنا نقاش ممتع في مجتمع الذكاء الاصطناعي على منصة ريديت بدأه شخص بسؤال "هل أجلت قوقل بدء فقاعة الذكاء الاصطناعي؟".
صاحب الموضوع، كان عنده فرضية بسيطة لكن عميقة. يقول إنه في عام 2019، كان يعرف باحث في قوقل شغال على نموذج لغوي متقدم جداً اسمه "مينا" (Meena). قوقل وقتها نشرت عنه ورقة بحثية راح احط رابطها تحت، لكن ما حولته أبداً لمنتج يقدر يستخدمه الناس.
بعد ثلاث سنوات، في نهاية 2022، أطلقت شركة OpenAI نموذج ChatGPT اللي نعرفه كلنا، واللي فجر الثورة الحالية في الذكاء الاصطناعي. صاحب الموضوع يعتقد إن ChatGPT ما كان أفضل بكثير من "مينا"، ويتساءل لو قوقل نزلت "مينا" للناس في 2019، هل كان عالم الذكاء الاصطناعي اليوم متقدم ثلاث سنوات زيادة عن وضعه الحالي؟
النقاش اللي بعد طرح هذا السؤال كان ثري جداً، والناس حاولوا يجاوبون على السؤال من زوايا مختلفة. عجبتني طريقة تفكيرهم لأنها ما كانت سطحية، بل حاولت تحلل الأسباب الحقيقية وراء قرارات الشركات الكبيرة.
أغلب الردود اتفقت على نقطة محورية واحدة وهي أن قوقل كانت خايفة على مصدر رزقها الأساسي. التعليق الأعلى تقييماً، حكى قصة جميلة حصلت معه في 2009. يقول إنه كان في مؤتمر وسمع مهندسين من قوقل يعترفون إن الشركة وقتها كان عندها تقنيات تقدر تجاوب على الأسئلة مباشرة، بس قررت ما تطلقها. ليش؟ لأن 95% من دخل الشركة يأتي من الإعلانات اللي تظهر لما تبحث وتضغط على الروابط.
لو أعطتك الجواب مباشرة، ما راح تضغط على أي رابط، وبالتالي قوقل راح تخسر فلوس. وهذا الرد صراحةً كان جداً منطقي أن الشركة ما تبغى تضحي بمصدر دخلها على حساب أنها تريحك تبغاك تقعد أطول مدة في محرك بحثهم .
هنا ظهرت فكرة "معضلة المبتكر" (Innovator's Dilemma). وهي حالة تصبح فيها الشركات الكبيرة والناجحة تخاف تتبنى تقنيات جديدة ممكن تضر بنموذج عملها الحالي اللي يجيب لها أرباح ضخمة، حتى لو كانت هي اللي اخترعت هذي التقنية.
المشاركون في النقاش جابوا أمثلة لشركات مثل كوداك اللي اخترعت الكاميرا الرقمية وتجاهلتها، وزيروكس اللي ابتكرت واجهة المستخدم الرسومية وما استفادت منها، وبلاك بيري اللي كانت تضحك على الآيفون أول ما نزل. كلهم كانوا عمالقة في وقتهم، بس ترددهم في تبني الجديد هو اللي أنهاهم. ويبدو إن قوقل كانت تعيش نفس المعضلة بالضبط.
وهذا يطرح نقطة ثانية، وهي إن قوقل ما كانت راح تتحرك إلا لو فيه أحد أجبرها على الحركة. هنا يجي دور OpenAI. أحد المعلقين، قال إن مايكروسوفت لما استثمرت 10 مليار دولار في OpenAI، كان هدفها الأساسي هو "نكش الغوريلا الضخمة" (يقصد قوقل ) واجبارها تطلع التقنيات اللي مخبيتها وتدخل المنافسة. OpenAI، كشركة ناشئة وقتها، ما كان عندها شيء تخسره. بالعكس، كانت مغامرة محسوبة، ونجحت نجاح باهر في إجبار السوق كله على أنه يطلع آخر التقنيات اللي عنده في المجال.
فيه فريق ثاني من المعلقين كان عنده نظرة تقنية أكثر، وقالوا لحظة، المقارنة بين "مينا" وChatGPT ما هي دقيقة. صحيح إن قوقل هي اللي نشرت الورقة البحثية الأهم في هذا المجال كله في 2017 عن تقنية الـ Transformers اللي بُنيت عليها كل النماذج الحالية، بس الفروقات بين النماذج كانت كبيرة.
واحد من المعلقين وضح نقطة مهمة جداً. نموذج "مينا" كان حجمه 2.6 مليار معامل (Parameter)، بينما نموذج GPT-3 اللي سبق ChatGPT كان حجمه 175 مليار معامل . الفرق هائل، ويخلي "مينا" يبدو غبي جداً بالمقارنة.
هنا لازم نوضح التسلسل الزمني عشان الصورة تكون كاملة. في 2019، كان الموجود هو GPT-2. في بداية 2020، أعلنت قوقل عن "مينا". وبعدها بكم شهر في منتصف 2020، أطلقت OpenAI نموذج GPT-3 اللي كان قفزة حقيقية في القدرات.
بس حتى GPT-3 ما أحدث الضجة الكبيرة بين عامة الناس، لأنه كان متاح للمطورين بشكل أساسي. الانفجار الحقيقي صار في نهاية 2022 مع إطلاق ChatGPT، والسبب ما كان فقط قوة النموذج (اللي هو نسخة معدلة من GPT-3.5)، بل كان شيئين الأول واجهة الاستخدام السهلة اللي خلت أي شخص يقدر يدردش معه، و الثاني تقنية الضبط الدقيق اللي اسمها RLHF واللي خلت ردوده أكثر أماناً وإفادة وحولت النموذج من مجرد آلة تكمل الكلام إلى مساعد شخصي.
هذا يوضح إن المشكلة ما كانت بس تردد قوقل. حتى لو أطلقت "مينا" في 2020، غالباً ما كان راح يحدث نفس التأثير، لأن النموذج نفسه كان أصغر وأقل قدرة، وما كان مصقول بنفس الطريقة اللي صُقل فيها ChatGPT. قوقل كانت تشوف مخاطر مثل "الهلوسة" - يعني إن النموذج يخترع معلومات من رأسه - كخطر كبير على سمعتها كأكبر محرك بحث في العالم. أما OpenAI، فكانت مستعدة تتحمل هذا الخطر.
النقاش هذا يوضح فكرة أساسية عن كيفية تطور التقنية. التقدم الحقيقي لا يأتي من اختراع واحد معزول، بل من سلسلة من الابتكارات والمنافسة الشرسة.
صحيح أن قوقل وضعت الأساس النظري بالـ Transformers، لكن OpenAI أخذت الفكرة وطبقتها على نطاق ضخم وجعلتها متاحة للجميع. المنافسة اللي خلقتها OpenAI أجبرت قوقل على إطلاق نماذجها (بارد ثم جيمناي) بسرعة، وهذا التنافس هو اللي قاعد يسرع التطور اللي نشوفه اليوم.
يمكن لو قوقل أطلقت "مينا" مبكراً، كان الوعي العام بالمجال بدأ بشكل مبكر، بس ما أظن كنا راح نقفز ثلاث سنوات للمستقبل، لأن السوق والبنية التحتية والتقنيات المصاحبة ما كانت جاهزة وقتها.
رابط بحث قوقل :
https://t.co/BUfuphQfNV
ممكن توقفون تستخدمون ai
والله يا عالم انه بيخليكم اغبياء تعبت وانا انصح كيف يعني ما تقدرون تسوون اسايمنتز عادي بدون اعتماد عليه؟
It doesn’t make your life easier it just makes your brain lazier
ارفق لكم في حسابي في Kaggle بيانات الرحلات الداخلية و الدولية لمطار الملك خالد الدولي بالرياض و الذي يتضمن اكثر من 150 الف صف من شهر مارس الماضي حتى يوم الامس 10 اكتوبر في ملف بصيغة Parquet, تم سحب البيانات من اكثر من API و معالجتها و تخزينها باستخدام Python, البيانات جداً ممتازة للتحليل و بناء مشاريع ML كونها تتضمن معلومات تفصيلية عن الرحلات و كذلك تقدر انك تنظف الداتا اكثر و تعالجها بالطريقة اللي انت تبيها و تبني مشاريع بتقنيات عديدة.
رابط البيانات:-
https://t.co/UzPzQ3aD8A
من أكثر التحديات في الذكاء الاصطناعي اليوم هي تحويل المستندات العربية إلى نصوص وبيانات قابلة للمعالجة والاستخدام.
ورغم تقدم النماذج متعددة الوسائط في اللغات العالمية، إلا أن أداؤها في اللغة العربية ما زال محدوداً بسبب طبيعة الخط العربي، وتنوع الخطوط، والاتجاه من اليمين إلى اليسار.
في ورقة بحثية جديدة من شركة Misraj السعودية بعنوان بصير (Baseer)، تم تقديم أول نموذج رؤية-لغوي مخصص لـ التعرف البصري على المستندات العربية (OCR) وتحويلها إلى Markdown أو نصوص قابلة للمعالجة والاستخدام.
النموذج تم تدريبه على 500 ألف مستند (حقيقي وتوليدي) باستخدام نموذج Qwen2.5-VL-3B مع استراتيجية Decoder-only fine-tuning، وحقق WER = 0.25 منافسا نماذج مفتوحة ومغلقة مثل GPT-5 بناءً على بيانات التقييم الخاصة بهم.
كما قدم الباحثون مجموعة بيانات تقييم جديدة باسم Misraj-DocOCR، وهي معيار مفتوح لتقييم نماذج OCR العربية، تمت مراجعته يدوياً بجودة عالية.
الورقة مهمة للمهتمين بالذكاء الاصطناعي ومعالجة النصوص العربية وانصح بالاطلاع عليها للفائدة
رابط الورقة:
https://t.co/wlQaEQEC4X
قبل الذكاء الإصطناعي كان لا بد لك كمبرمج من البحث عن حلول لمشاكلك بنفسك ومصدرك الأول كان إجابات stackoverflow
بعد ظهور الذكاء الإصطناعي الموقع شبه مات .. والمحزن أن الكثير من مبرمجي الفايب كودينج اليوم والمستقبليين لن يعرفوا حتى ما هو!
@Rahma_Ameen00 ممكن تقرأ الكومنتات على البوستات دي، فيها طرق كتير
ومتنوعه، أنا شخصيًا جربت منها كذا طريقة وطلعت مفيدة جدا
https://t.co/0yWM3B1jOT
https://t.co/0yWM3B1jOT
https://t.co/FHSvogyoIL
شكرًا يا محمد إنك شاركت معلومة أنت شفتها كويسة.
لكن الكتاب دا يفضل تولع فيه وتدفى بيه في الشتا.
99.9٪ من النصايح اللي هتقرأها فيه عبثية إن لم تكن سيئة.
ال exceptions مكلفة جدًا جدًا وإنك ترجع null مش نهاية العالم بالعكس منطقي لإنه بيوصف state منطقية وهي غياب القيمة
المشكلة فين؟
مع كثرة التطورات السريعة وانتشار الابحاث في الذكاء الاصطناعي، خصوصا في التعلم التعزيزي (RL)، اصبح من الصعب تتبع كل شي أو استيعاب جميع الابحاث والتطورات وادوارها او وش قاعد يصير فعلا
وجت ورقة بحثية ضخمة من باحثين في جامعة تسينغهوا ومختبرات صينية شهيرة، تلخص كل شيء تقريبًا من مفاهيم الى استخدام RL في تدريب النماذج اللغوية الكبيرة
اسم الورقة:
A Survey of Reinforcement Learning for Large Reasoning Models
ورقة ضخمة (أكثر من 60 صفحة) تلخص كل التطورات في المجال وخصوصا:
- أهم الأساليب والخوارزميات المستخدمة حاليًا
- التحديات في الحوسبة، البيانات، وتصميم الخوارزميات
- تطبيقات واقعية مثل DeepSeek
- مستقبل المجال وفرص البحث اللي ممكن توصل لفكرة مشروع أو ورقة بحثية جديدة
الورقة تختصر وقت وجهد كبير لكل مهتم، وتساعدك تربط بين التطورات السريعة والمفاهيم الحديثة. أنصح بالاطلاع عليها.
رابط البحث:
https://t.co/5bpKU5jjvK
على طاري ذا الموقع
مره قرأت هذا التساؤل
How do you know when to keep your goals and achievements private vs sharing them with others?
"كيف تعرف متى تخلي أهدافك وإنجازاتك لنفسك، ومتى تشاركها مع الآخرين؟"
ما ابالغ لكن ذي اعمق واحكم واذكى اجابة مرت علي
اقرأها.. مرتبه 👇🏽
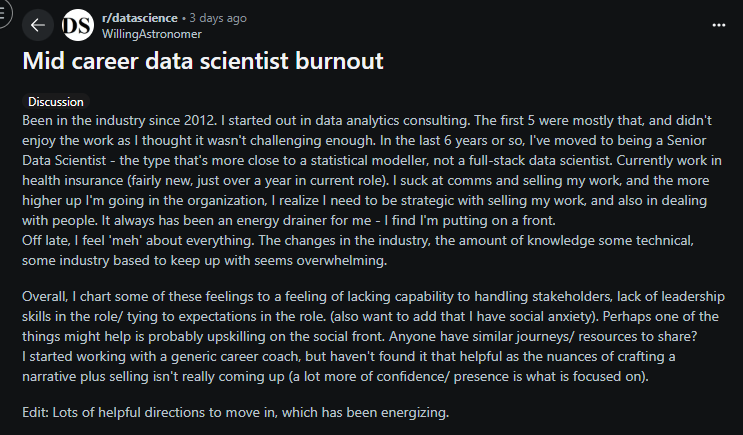
كثير من الناس اللي يشتغلون في المجالات التقنية يمرون بمرحلة يسمونها "احتراق منتصف المسيرة المهنية". هذي المشكلة ما لها علاقة بالتقنية نفسها والأدوات اللي تستخدمها، هي أعمق من كذا، مرتبطة بالإنسان نفسه، بمعنى عمله، وبالعلاقة اللي يكونها مع شغله.
هنا قصة عالم بيانات عنده خبرة طويلة، حوالي ١٢ سنة. وصل لمنصب "Senior Data Scientist"، وهذا يعتبر قمة في مجاله. الرجل ناجح ومتمكن، لكنه اكتشف أنه مع كل هذا ما يشعر لا بالرضا ولا بالإنجاز، بل بالعكس بدأ يحس بفراغ داخلي.
الموضوع مو أن شغله صعب تقنياً، بل لأن طبيعة العمل تغيرت. زمان كان النجاح يقاس بقدراته في بناء النماذج وحل المشكلات. لكن الآن صار النجاح يتوقف أكثر على قدرته يشرح شغله، يقنع أصحاب القرار، ويتعامل مع السياسات داخل الشركة.
المشكلة أنه شخص انطوائي ويعاني من القلق الاجتماعي، فصار يحس كأنه يلبس قناع كل يوم عشان ينجز. ومع الوقت، الشغف اللي كان يحركه اختفى. التعلم المستمر اللي كان يحمسه صار عبء، والمكانة الجديدة صارت تكشف ضعف مهاراته الاجتماعية والقيادية.
لما شارك مشكلته، التعليقات كانت مثل جلسة اعتراف جماعية. كثير كتبوا إنهم يمرون بنفس التجربة، وإنها مو حالة فردية.
أكثر فكرة تكررت هي أن "العمل مجرد عمل". كثير بدأوا حياتهم المهنية بحماس، لكن مع مرور الوقت تحولت الوظيفة إلى وسيلة للعيش فقط. ومع التقدم في العمر، الأولويات تتغير: وقت العائلة والهوايات تصير أهم من البقاء ساعات طويلة في المكتب. كثير من التعليقات أخبروه أنه مو لازم عملك يكون مصدر شغفك الأساسي. يكفي أنه وظيفة مقبولة وتوفّر لك حياة مستقرة، أما الشغف تقدر تلاقيه خارج أوقات العمل.
النقطة الثانية أن المهارات التقنية لها سقف. في المناصب العليا، نصف النجاح يعتمد على التقنية، والنصف الثاني على التواصل وبناء العلاقات. البعض سمّى هذا التحول "مسرح الشركات"، لأن الاجتماعات والعروض التقديمية صارت أهم من النتائج نفسها. وهذا شيء يرهق الناس اللي يحبون الإنجاز الملموس أكثر من الكلام.
النقطة الثالثة كانت عن بيئة العمل. كثير اشتكوا من السياسات السامة: تسريحات عشوائية، غياب التقدير، أو مشاريع شكلية هدفها اللحاق بالموضة. كل هذا يخلي العمل يفقد معناه.
لكن ما وقفوا عند المشكلة، بل طرحوا حلول. في ناس قالوا: تعامل مع المهارات الناعمة وكأنها مسألة تقنية. زي ما تحلل بيانات، تقدر تحلل علاقات العمل وتتعامل معها باستراتيجية. وفي ناس قالوا: وجود مدير يفهمك ويدعمك ممكن يغيّر كثير، لأنه يتبنى شغلك ويحميك من الضغط.
وفي حلول ثانية، بعضهم غيّر مجال عمله إلى شيء له معنى أكبر في حياته، حتى لو كان الدخل أقل. وبعضهم اختار يترك الشركات ويشتغل مستقل، عشان يركز على الشغل نفسه بعيد عن المسرح.
الخلاصة أنك إذا حسيت بهذي المشاعر فهذا طبيعي جداً، وما يعني إنك الوحيد. كثير ناس مستمرين في وظائفهم لأنها مصدر رزق، مو لأنها الوظيفة المثالية أو لأن حياتهم وردية. عشان كذا، إذا كنت تكره وظيفتك لكن ما عندك بديل أو مصدر دخل آخر، لا تتسرع وتتركها بدون خطة. والأهم إنك تبدأ توازن حياتك دور على شغفك أو متعتك خارج ساعات العمل، وطور مهاراتك الاجتماعية والإنسانية زي ما تهتم بمهاراتك التقنية. ومع الوقت، إما تلاقي طريقة تتعايش مع وظيفتك بشكل أريح، أو تجهز نفسك لانتقال واعي لبيئة تناسبك أكثر.
Training with large minibatches is bad for your health.
More importantly, it's bad for your test error.
Friends dont let friends use minibatches larger than 32. https://t.co/hxx2rGhIG1