@ravihanda VC funds capital drawdowns happen over time and so do exits. So IRRs are substantially higher than simple CAGR numbers. In this scenario, real IRR could be anywhere in the high teens to low 20s range. Sharing as this isn't well understood to folks outside VC.
Anthropic’s last round was apparently a bloodbath behind the scenes. A GP at a prominent fund had dinner with Dario three times before their allocation was slashed to zero. At least four other tier-one funds got pulled at the last minute.
Their crime? Passing on the Series B, the hardest round Dario ever had to raise (led by Spark). In venture conviction is all that counts.
True:
“They gave stock to everyone. There are a bunch of highly skilled workers that we on X never think of, like Tube Benders, Orbital Tube Welders, Cleanroom Technicians, etc. that are going to make significant fortunes.”
On this day in 2024, we flew Mission - 01, a fully controlled flight from a completely new location within Sriharikota, with our vehicle - Agnibaan SOrTeD. As we recollect this, we would like to take a moment to thank everyone - the Government, our investors, vendors, and our incredibly hardworking crew for coming together to make this happen.
We also recognise that this Mission had a few "firsts".
🚀 World's first flight with a single-piece 3D-printed engine
🚀 India's first semi-cryogenic engine-powered flight
🚀 India's first flight powered by Linux OS and Ethernet architecture
and more...
We also remind ourselves that this was never a race though. This is about a very young team & their families, choosing to build completely new technology from India, for the world, and in that process help satellites get to orbit.
Here are some previously unseen photos from Mission - 01.
Super excited about Mission - 02.
#Agnibaan #RocketEngineCluster #ElectricPumpFedEngines #Agnilet #SinglePieceEngine #3dprinting #RocketEngineTest #AdditiveManufacturing #Agnikul #AgnikulCosmos #StartupIndia #MakeinIndia #madeinIndiaForTheWorld
@srinathr155@moin_spm@satchakra_iitm@iitmadras@iitmrp@IITMIC@tdbgoi@IndiaDST@ANRFIndia@TIDCO_1965@startupindia@TheStartupTN@Guidance_TN@startup_mission@SIPCOTTN
$8 million a month.
Nearly $200 million total.
All burned on a single technical problem no one was sure could be solved.
Here's how Cerebras became a $60 billion company:
1/ The impossible chip
Andrew Feldman and his co-founders were trying to package an AI chip 58 times larger than standard chips, drawing 40 times more power than anyone had ever attempted.
They destroyed an enormous number of chips through trial and error.
They invented a custom machine to bolt 40 screws simultaneously because one misaligned screw would crack the wafer.
2/ The bet they didn't have to make
This was the same team that built SeaMicro and sold it to AMD for $334 million in 2012.
They could have retired. Instead they bet everything on Cerebras.
3/ The breakthrough
In July 2019, the chip finally worked.
Feldman and the team stood in the lab and stared at it. He later called it one of the greatest moments of his life.
4/ The offers they turned down
OpenAI had tried to acquire Cerebras around 2017, but the deal collapsed. Several OpenAI founders are angel investors in Cerebras.
Instead of selling, the team kept building.
OpenAI later loaned Cerebras $1 billion secured by warrants granting about 33 million shares. At Friday's close of $279 per share, those warrants are worth over $9 billion.
Arm and SoftBank tried to buy Cerebras weeks before its IPO. The company said no.
5/ The IPO
In May 2026, Cerebras went public, selling 30 million shares in a deal raising roughly $4.8 billion. Ended the week worth about $60 billion.
Both co-founders became billionaires.
The company was valued at $8.1 billion just seven months earlier.
Same founding team. Two massive exits.
Feldman put it simply: "You can't go up against the 800-pound gorilla with modest effort."
The difference between an $8 billion company and a $60 billion one was the willingness to spend nearly $200 million on a single problem everyone else walked away from.
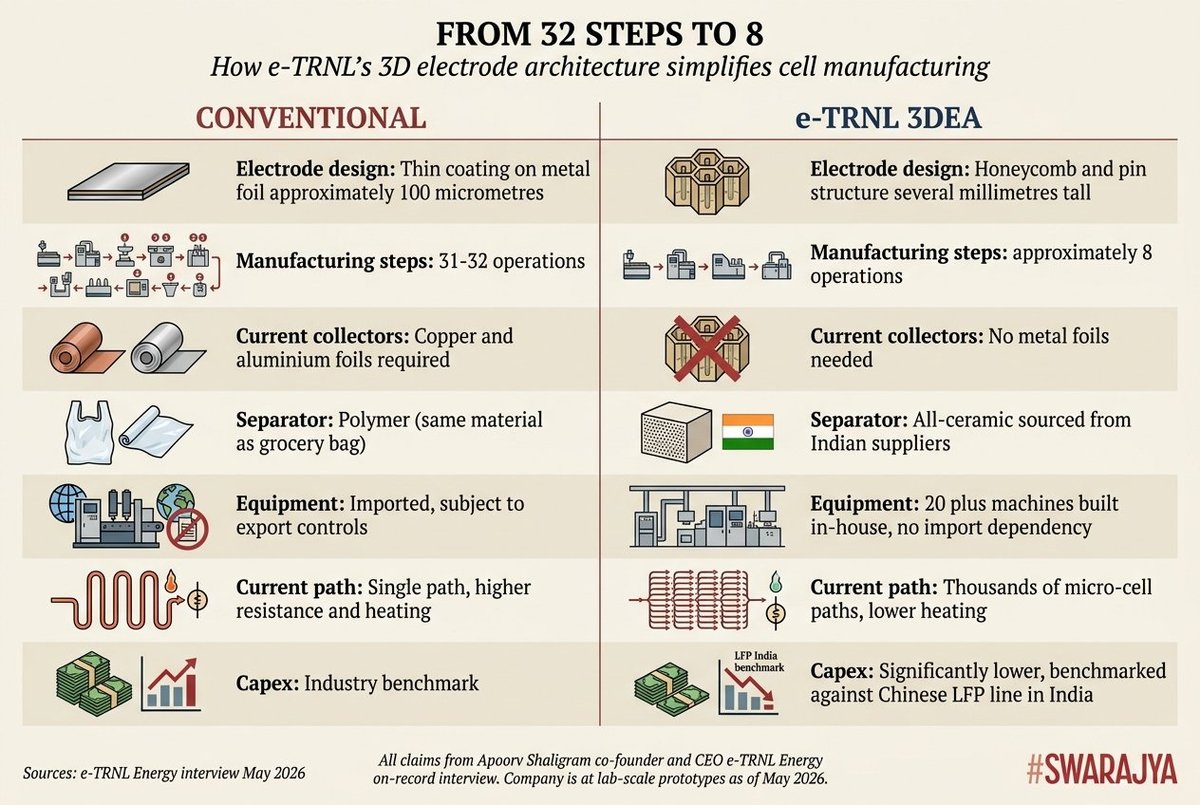
Lithium ion battery cells were never 'designed' for the applications they are running today... EVs, drones, backup for renewables...
Our first principles approach not only improves the energy efficiency of batteries, but also their manufacturing efficiency.
there are only two modes in fundraising: fully in. or not fundraising at all. no in between.
if you're in the process: meetings lined up. back to back. calendar density. all of it.
if you're not ready: stop saying you're fundraising. be interesting. build the relationship. activate it later.
founders who blur these two modes come across as desperate without urgency. raising without a process. asking without leverage.
worst of both worlds.
pick a mode. execute it completely.
Every EV, every phone, every power backup system runs on a small cylinder called a battery cell.
India uses millions of them but makes almost none. Nearly all are imported. Mostly from China.
Here's what's going on with India's battery problem 🧵
China banned battery equipment exports to India last year btw.
So every company that was dependent on Chinese machines is now in an UNCOMFORTABLE position.
e-TRNL's founder basically said: good thing we built our own.
Then there's this startup e-TRNL.
They decided that the basic battery design — which hasn't changed since Sony borrowed it from cassette tape manufacturing in the 90s — was the problem.
So they redesigned it, and built 20+ machines from scratch to manufacture it.
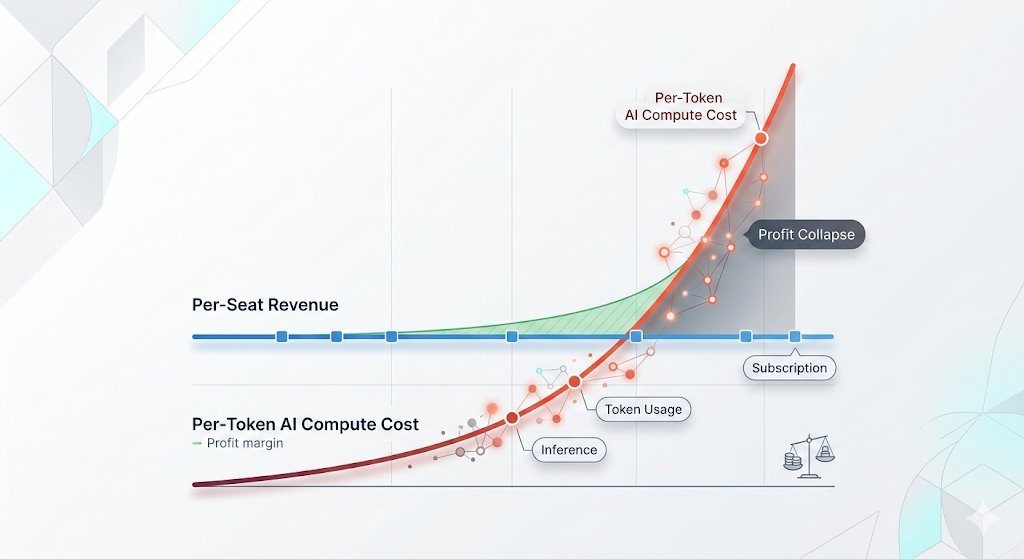
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
Humbled to share that we successfully test fired 4 semi-cryogenic rocket engines simultaneously, as a cluster.
All the 4 engines are 3d printed as single pieces of hardware - designed and manufactured in-house at AgniKul Cosmos Rocket Factory - 1. As with all our propulsion systems, these 4 engines are also powered by electric motor driven pumps.
This test involved calibrating 8 pumps, 8 motors and tuning 8 speed control algorithms to work together in perfect sync to achieve uniform startup, steady state and shutdown performance across the entire system. As with the last cluster test, to the best of our knowledge, this is the first time such a test has been performed in India with semi cryogenic engines.
We are extremely grateful to have the opportunity to be building world class, original space technology from India, for the world with the support of @iitmadras@isro and @INSPACeIND
From here on, the addition of engines to our clusters will likely increase non-linearly. #Agnibaan #RocketEngineCluster #ElectricPumpFedEngines #Agnilet #SinglePieceEngine #3dprinting #RocketEngineTest #AdditiveManufacturing #Agnikul #AgnikulCosmos #StartupIndia #MakeinIndia #madeinIndiaForTheWorld
@srinathr155@moin_spm@satchakra_iitm@iitmadras@iitmrp@IITMIC@tdbgoi@IndiaDST@ANRFIndia@TIDCO_1965@startupindia@TheStartupTN@Guidance_TN@startup_mission@SIPCOTTN
What model is the best at poker?
Benchmarks are great, but they're not fun, I wanted to put models in head-to-head competition
Background: a few weekends ago I built an agent poker engine and wanted to see which agent was better - Hermes or OpenClaw
Hermes won the first match, then I had them play 100 matches (not hands) of heads up Texas Hold'em
The result? Exactly 50-50, neither is decisively better out of the box
I used a variety of models across the 100 matches to mix it up and noticed some trends, so last night I ran a tournament to see which MODEL was best at poker
Here's how it worked:
> 8 models
> model vs model in heads up play
> best-of-7 series to determine winner
> each match played until either one model was bankrupt or 100 hands were played
After the first round:
> GPT-5.5 (#1 seed) beat Qwen 3.6 (#8 seed) 4-0
> Opus 4.7 (#2 seed) beat GLM-5.1 (#7 seed) 4-1
> Kimi K2.6 (#6 seed) beat Grok 4.3 (#3 seed) 4-3
> Gemini 3.1 (#4 seed) beat DeepSeek V4 (#5 seed) 4-2
No real surprises, and the one "upset" with Kimi beating Grok went the full 7 matches
Moving onto the semis today
“The Impossible” 1964 shot that reportedly left Martin Scorsese speechless.
This stunning sequence from the 1964 film I Am Cuba (Soy Cuba) is still regarded as one of the most technically daring shots ever captured on camera.
Long before CGI or stabilized drone systems existed, director Mikhail Kalatozov and cinematographer Sergey Urusevsky engineered the sequence using elaborate rigs of cables, pulleys, and custom-built camera setups. The camera begins at street level, ascends the exterior of a building, moves through a cigar factory, and then glides out over the city in a single continuous take, creating a fluid, gravity-defying movement that feels strikingly modern even by today’s standards.
The shot is also renowned for its surreal visual quality. Shot on specialized infrared film, the vegetation appears almost luminous white against a deep black sky, giving the image an otherworldly, dreamlike atmosphere. Initially overlooked as Cold War propaganda, the film was rediscovered decades later and restored in the 1990s, after filmmakers like Martin Scorsese and Francis Ford Coppola praised its extraordinary craftsmanship. Even now, it remains a benchmark for what’s possible in practical cinematography.
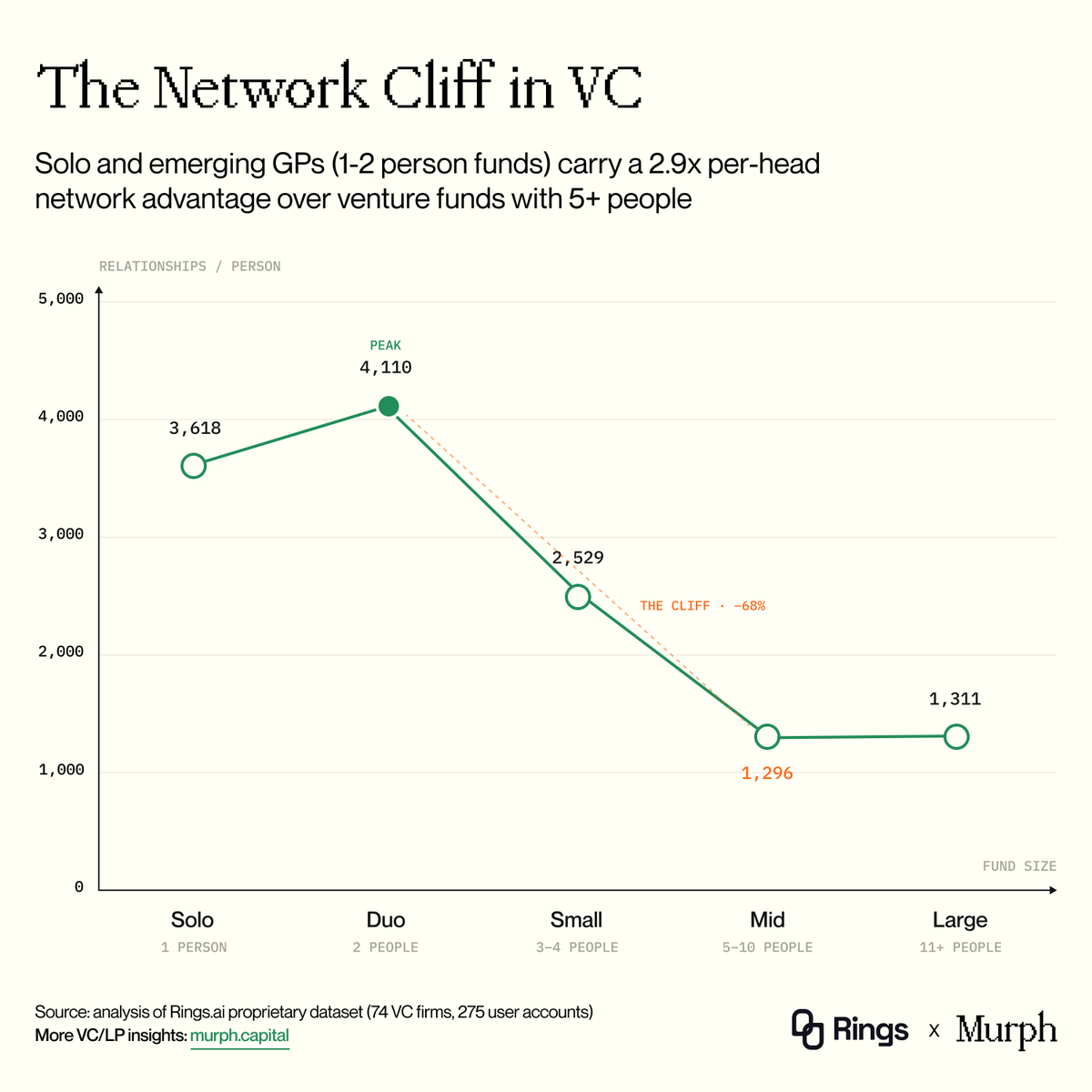
Do solo and emerging GPs actually have a network edge?
I've been speaking with a lot of emerging VCs lately, and every second one leads with the same narrative: "we have a broad, defensible network."
So I looked at the @RingsApp dataset (74 funds, 275 user accounts) to check whether that's actually true. And a few numbers stood out to me:
- Solo and duo GPs carry 2.9x more relationships per person than funds with 5+ people
- The peak is at 2 people – 4,110 relationships per person. Solo GPs sit at 3,618
- Cross into 3-4 people and you're already at 2,529
- At 5-10 people the median drops to 1,296. That's a 68% decline from peak
- Mid and large funds are essentially identical – 1,296 vs 1,311. Adding headcount at that point changes nothing
And yeah, it seems that the edge is real, but based on my experience talking to GPs across fund sizes, I don't think it's because solo GPs are unusually well-connected people.
I think it's structural and a few things explain it:
1/ Survival pressure. At a larger firm you can be an average networker and still get deal flow through the brand, through partners, through inbound. Solo GPs don't have that buffer. You build relationships or you don't see deals. That's an existential pressure, and it produces genuinely different behavior.
2/ Time allocation. Every growing firm pays "a scale tax" – internal meetings, team management, etc. Solo GPs don't pay it. Every hour a partner at a larger firm spends on internal alignment is an hour a solo GP spends on a call with a founder or LP.
3/ Relationship quality. When you're one person, you can't delegate relationships, so you do the intro yourself, the follow-up yourself, you remember the details. At larger firms relationships often become institutional (like "we know that founder!"), but nobody specifically knows them well. Solo GPs build connections that are personally held, which makes them informationally richer and harder to replicate.
4/ Signal clarity. At a big firm people come to you because of where you work. The brand amplifies deal flow – but it also distorts it. When someone calls a solo GP, it's because they know that specific person. I think this makes a real difference in the quality of the relationship, not just the quantity.
And the part I find most interesting (and maybe a bit uncomfortable for EMs to sit with) is that this advantage is time-limited by design.
Based on the data, it starts compressing not when you raise Fund III, but when you make your 3rd hire. The cliff happens between 2 and 5 people, not between 10 and 50.
I think the funds that preserve the edge are the ones that build infrastructure early enough to turn individual relationships into something the firm actually owns (automated CRM enrichment, shared context, real visibility into who knows whom), because without it the network doesn't belong to the firm, it belongs to a person.
For LPs this reframes the DD question, because team size is commonly used as a proxy for network breadth, but the data says it's almost the opposite — the right question isn't how big the network is, it's where it lives, who owns it, and what happens to it if the key person walks out the door.
In April 2016, I threatened to climb over @andrewdfeldman's fence to give him his first term sheet for @cerebras.
It was April Fool’s day, but I wasn’t fooling around.
The story started in October 2007, when Andrew and his co-founder Gary Lauterbach had just started SeaMicro.
Even then, Andrew was a force of nature. He was extremely intense and miswired in all the right ways. You could feel the sparks flying off him.
We didn't invest in SeaMicro, but we stayed in touch. Andrew and the team built SeaMicro then sold it to AMD in 2012.
When AMD acquired SeaMicro, I had a hunch Andrew wouldn't last long inside a big company. He has, as I've said many times, immense ambition and a heart full of disobedience. By early 2014, he was looking for an escape hatch.
Over the next year and a half, Andrew and I met 6 or 7 times. Sometimes in our office. Sometimes at a coffee shop in Portola Valley. Sometimes at our local tennis and swim club. We kept coming back to one thing: deep learning workloads were growing exponentially, and traditional compute architectures couldn't keep up.
GPUs had become the default for neural network training, mainly because researchers had accidentally discovered they were less terrible than CPUs. Andrew, Gary and Sean saw the GPU for what it was: a battlefield promotion of a chip optimized for graphics. Better than a CPU, but not what anyone would design starting from a blank sheet of paper.
Their key insight was that memory bandwidth, not raw compute, was the real constraint on what neural networks could achieve.
So Andrew, Sean Lie, Gary Lauterbach, Jean-Philippe Fricker and Michael James set out to do something nobody had pulled off in the 75-year history of semiconductors:
Build a wafer-scale chip the size of a dinner plate.
In April 2016, I asked Andrew if we could be his first term sheet. @ericvishria at Benchmark and I co-led the round along with Pierre Lamond from Eclipse.
Then the hard work began.
In the 75-year history of computing, no one had made wafer scale work. Which meant no one had ever had to solve the problems that came from trying.
How do you power a chip that large? How do you cool one? How do you maintain electrical continuity across tens of thousands of connection points on a single piece of silicon?
To get there, Cerebras had to invent in nearly every modern computing discipline at once: semiconductors, systems, data fabric, software, algorithms. Each was a startup in its own right.
Their first wafer self-destructed on initial power-up and Andrew and the team were back in the lab the next morning, identifying what didn’t work and coming up with approaches to solving it.
Yesterday, Cerebras went public.
19 years after our first meeting, 10 years after that April Fool's term sheet, they’ve built a generational AI company.
From a coffee shop in Portola Valley to ringing the bell at the NASDAQ. What a journey.
Proud to have been Andrew's first partner in Cerebras. Even prouder to call him my friend.
Based on the S-1 filing of Cerebras they raised over $800m before they added any revenue. What it takes to do deeptech…
Imagine it takes 9 years to convince investors what you have is a good market, company, real contracts. The founder definitely lost a lot of hair over that decade!