Despite theoretically handling long contexts, existing recurrent models still fall short: they may fail to generalize past the training length. We show a simple and general fix which enables length generalization in up to 256k sequences, with no need to change the architectures!
Luck can build a great model once. Deep understanding is what lets you do it again and again.
One week after hitting #1 in Text to Speech, we're now #1 in Automatic Speech Recognition too!
Cartesia Ink-2 debuts as #1 for accuracy on the brand-new streaming speech-to-text leaderboard from @ArtificialAnlys! We designed Ink-2 from the ground up for voice agents - with low latency, eager transcripts, and semantic endpointing.
When you meet with your friends, you don't type - you talk to them. Still, we prefer to type to ChatGPT.
We have fixed this at Cartesia. Sonic 3.5, is both the most expressive and fast model out there!
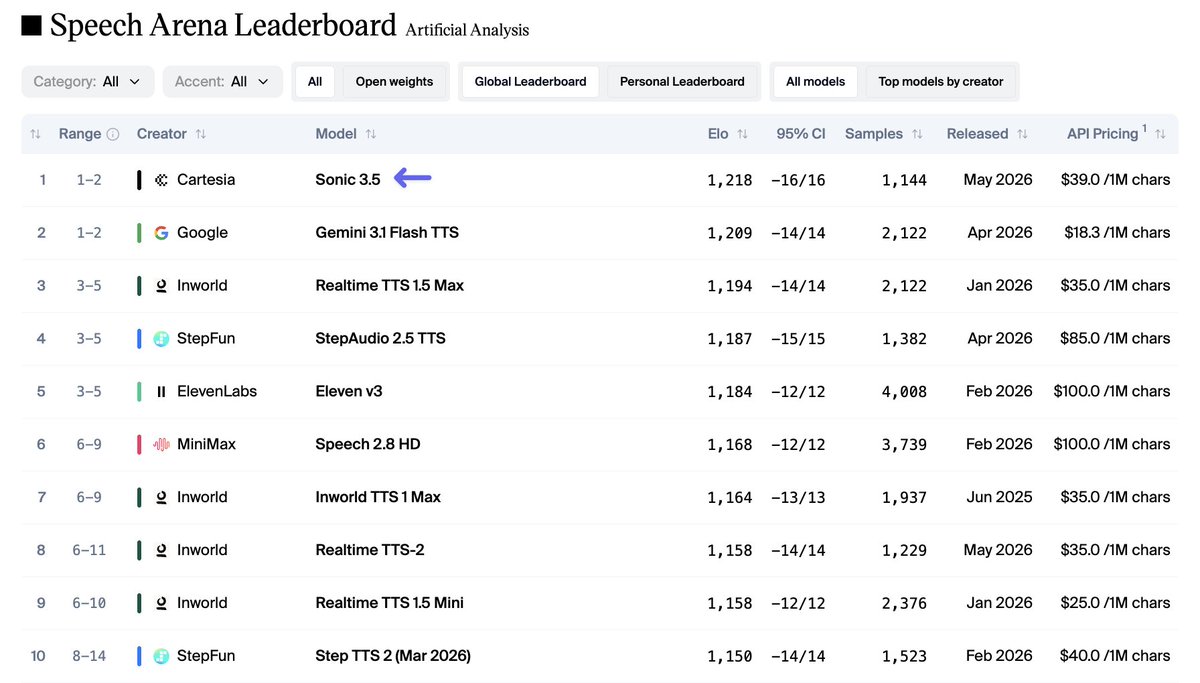
Cartesia’s Sonic-3.5 takes the #1 spot on the Artificial Analysis Speech Arena Leaderboard, surpassing Inworld Realtime TTS 1.5 Max and Google’s Gemini 3.1 Flash TTS
Sonic-3.5 is the latest TTS model from @cartesia . It supports 42 languages, including 9 Indian languages, with 500+ voices available out of the box. The model has been highly preferred among voters in the TTS Arena, with its demonstrated naturalness and accurate transcript following.
Key takeaways:
➤ Quality: Sonic-3.5 has an Elo score of 1,218 (+16/-16) based on 1,144 arena appearances, placing it ahead of Inworld Realtime TTS 1.5 Max at 1,194 and Gemini 3.1 Flash TTS at 1,209
➤ Pricing: Sonic-3.5 is priced at $39/1M characters, a premium compared to Gemini 3.1 Flash TTS at $18.3/1M characters, and Inworld Realtime TTS 1.5 Max at $35/1M characters
➤ Speed: 105.5 characters per second, compared to 205 characters per second for Inworld Realtime TTS 1.5 Max and 26.3 characters per second for Gemini 3.1 Flash TTS
See more details and listen to samples below 🧵
SSMs fail on recall tasks they have the capacity to solve. The two dominant approaches today, SSMs and sliding-window attention, both lack persistence: memory either decays over time or gets evicted.
We built Raven to fix this, surpassing all prior linear models even at 16× their training sequence length. 🧵🐦⬛
1/ SSMs struggle on recall benchmarks due to their fixed-size state. But are current models actually storing context “wisely”?
Introducing Raven 🐦⬛, the first SSM with selective memory allocation! Raven achieves SOTA performance on recall-heavy tasks with the highest length generalization, extending up to 16× beyond its training sequence length. Raven is a strict upgrade over SWA in the way it stores past context!
This is the most elegant model I’ve been involved in designing so far shoutout to @avivbick and @_albertgu for their trust and amazing work!
Check out how Raven bridges between SWA and SSM👇
We've raised $100M from Kleiner Perkins, Index Ventures, Lightspeed, and NVIDIA.
Today we're introducing Sonic-3 - the state-of-the-art model for realtime conversation.
What makes Sonic-3 great:
- Breakthrough naturalness - laughter and full emotional range
- Lightning fast -
Tokenization has been the final barrier to truly end-to-end language models.
We developed the H-Net: a hierarchical network that replaces tokenization with a dynamic chunking process directly inside the model, automatically discovering and operating over meaningful units of data
I converted one of my favorite talks I've given over the past year into a blog post.
"On the Tradeoffs of SSMs and Transformers"
(or: tokens are bullshit)
In a few days, we'll release what I believe is the next major advance for architectures.
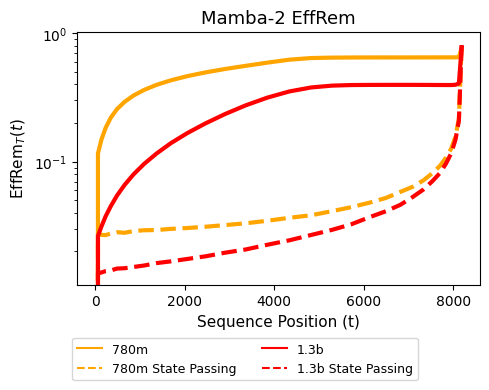
Lastly, we introduce Effective Remembrance as a quantitative metric to ascertain how much models "effectively remember" previous parts of the context. Existing models are disrupted by early tokens and can't prioritize the recent context, yet State Passing fixes this behavior.
Despite theoretically handling long contexts, existing recurrent models still fall short: they may fail to generalize past the training length. We show a simple and general fix which enables length generalization in up to 256k sequences, with no need to change the architectures!
Beyond just being robust to length, the intervened models have actual *extrapolation* past the training length, with significantly improved performance on complex long context tasks such as BABILong and passkey retrieval.
Today, we're excited to share Cartesia Narrations, in public beta. Narrations is a creator tool for narrating long-form content using Sonic 2.0.
You can use it to create audiobooks and podcasts, narrate your Substack posts, and more.
Some highlights🧵