How long does it take to predict ligand binding sites for all 220k proteins in the PDB? P2Rank 2.5 does it in 3 hours on a single CPU (16-core amd 5950x)—2x faster than the previous version 🚀.
The SwissProt subset of AlphaFoldDB (540k proteins) takes even less: under 2 hours (proteins are smaller on average).
But does prediction speed matter? 🤔 It depends. In most cases, probably not that much. After all, if you have only a few structures, it’s worth waiting for more accurate predictions.
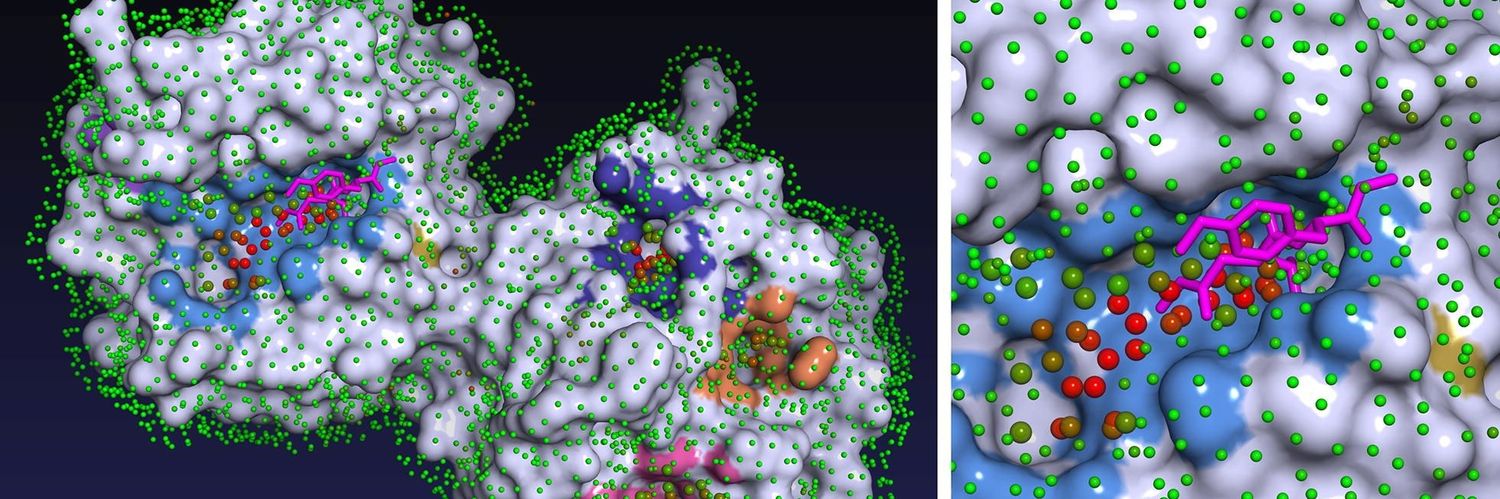
So, are slower methods more accurate? Not necessarily. A recent independent benchmark shows that P2Rank outperforms (in prediction success rate) newer, much slower Deep Learning based methods. (1/n)
🎨 Část areálu Ústavu organické chemie a biochemie AV ČR ve Stavitelské ulici lemuje šedá zeď a rádi bychom jí dali novou podobu. Proto vypisujeme veřejnou výzvu na návrh a realizaci murálu, který připomene 90. výročí narození chemika Antonína Holého – jedné z nejvýznamnějších osobností české vědy.
Více na ► https://t.co/IpbOYl5ztn 📲
#UOCHB #IOCB #IOCBPrague #AVCR #AkademievedCR #ceskaveda #chemie #popularizace
+1
This time, we updated the AlphaFind to allow quick structural search over AlphaFoldDB - this time with domains (TED and multi) and structure quality filtering
https://t.co/FoTFvPKnKZ
Try it out!
https://t.co/cRTyGvwlU1
We’ve built the world’s first Chemical Sequencer, but unlocking nature’s chemistry still requires more data and better ways to understand it. That’s why we’re deepening our collaboration with @tomas_pluskal and his lab at @IOCBPrague, a global leader in natural product chemistry and plant #metabolomics.
We’re proud to support the PhD work of Filip Jozefov, whose research combines machine learning and mass spectrometry. Filip is developing new machine learning approaches using a rich dataset generated in the lab. These approaches improve the accuracy of molecular structure prediction, which is an essential step toward decoding nature’s chemistry at scale.
Our ongoing collaboration supports our commitment towards advancing cutting-edge science, pushing the boundaries of what’s possible in structure prediction, and helping to shape the future direction of the field.🚀
#MachineLearning #MassSpectrometry #DrugDiscovery #Biotech
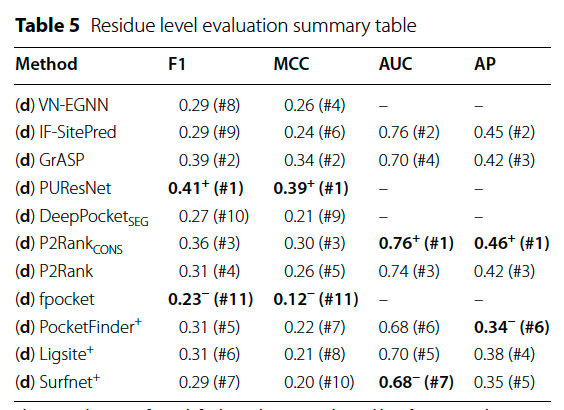
@gklambauer@IsomorphicLabs Also, despite being 8 years old, #P2Rank is still #SOTA, particularly when using conservation as an extra feature.
Outperforming P2Rank+Cons would further highlight #IsoDDE's already impressive capabilities, @IsomorphicLabs!
For more details, check: https://t.co/8qYIBK3JF0!
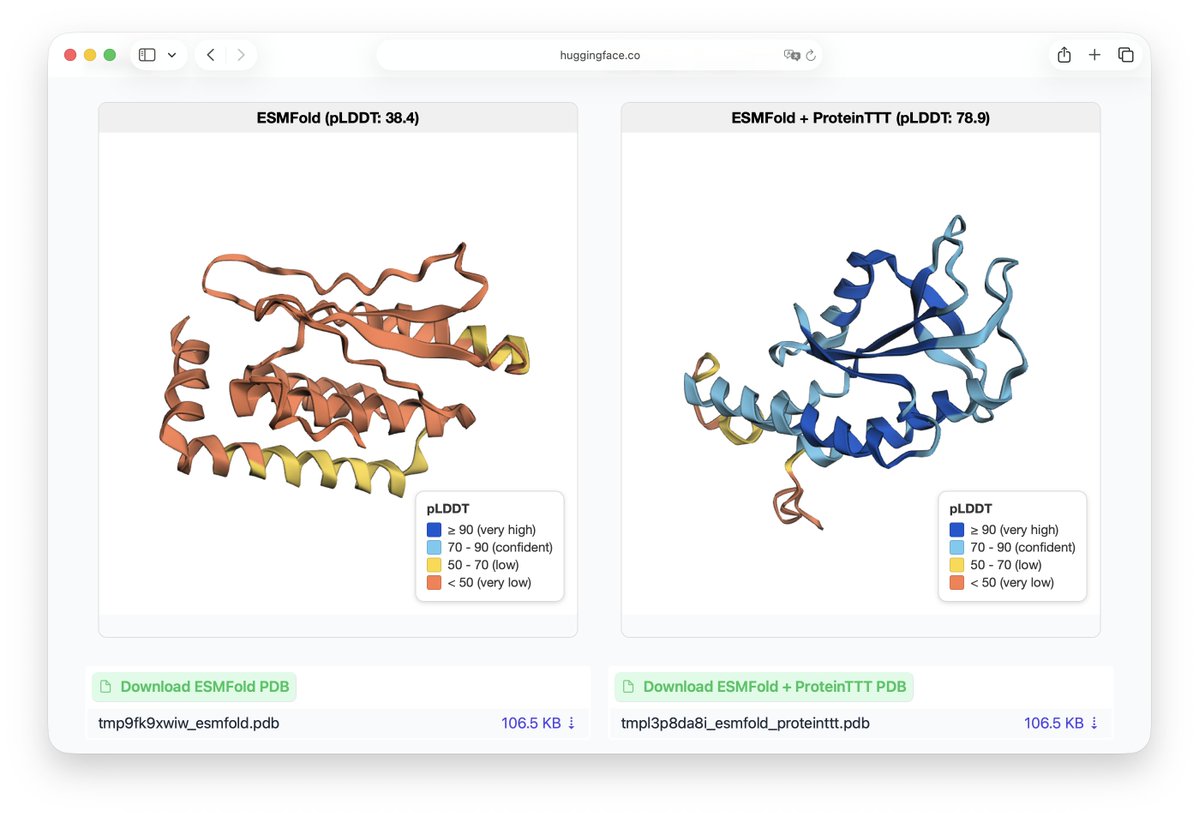
ProteinTTT is now easy to run on Hugging Face Spaces and Google Colab. We’ll also be presenting the paper at ICLR 2026 🇧🇷
🤗 Hugging Face Space: https://t.co/tq4lWuTqVJ
⚙️ Google Colab: https://t.co/nUSN6dEd5o
🧵👇
Built a tool for myself to easily trim/view/search/download/renumber protein structures for binder design tasks (even on the phone!)
wanted to share in case its helpful to anyone else
https://t.co/PDqSqrksxI
Missed our webinar on AI-powered chemoinformatics workflows?
The recording is now live https://t.co/ZhSHTZ2AjQ
We covered practical use cases around molecular embeddings, CADD workflows, and cloud/local deployment options. #Cheminformatics#DrugDiscovery#CADD#AIinDrugDiscovery
We won the 9ADD DYRK1B Virtual Screening Challenge! 🏆 (Team from Deep MedChem with @miroslavlzicar, Kryštof Škach, Alexander Korolyov)
Our Presentation: https://t.co/KYjEA08N8r
This is how CellARC looks: @arcprize style tasks, but generated using cellular automata (and with tunable complexity). Leaderboard: https://t.co/JKFC7gKyxJ
Very happy @roman_bushuiev and I joined the amazing team led by @HannesStaerk to work on BoltzGen, a generative model for binder design based on Boltz-2. Excited what it will enable!