Introducing Muse Spark, the first in the Muse family of models developed by Meta Superintelligence Labs.
Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
Muse Spark is available today at https://t.co/wHkMPH82ZH and the Meta AI app. We’re also making it available in private preview via API to select partners, and we hope to open-source future versions of the model.
Learn more: https://t.co/PloE9q5x96
We've been pretty quiet about what we're building. That changes now.
Our reasoning framework is currently beating every @OpenAI model on industry standard benchmarks. There are six models in development. SERV-nano just matched GPT-5.4 at 20x lower cost and 3x the speed. The research paper backing it is in peer review at a top-1% AI journal. The UAE government is running it in production, so are 10+ enterprises.
Nothing comes even close.
This goes far beyond any wrapper or prompt engineering gimmick, we've developed an entire AI reasoning layer from scratch: structured, bounded, deterministic using machine readable code instead of vague english prompts.
Any builder or enterprise swaps two lines of code and their agents get much cheaper and much smarter instantly. The self-serve API is about to open, in a multi-phase rollout.
More soon.
@SawyerMerritt Pretty incredible, generating $2B/mo, so $24B/year.
So 35x annual revenue multiple.
This is like a company doing $10M/year in ARR raising at a $350M valuation.
Which I think does happen quite a bit, so maybe nothing too unusual here right??
How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end
PSA: If you've been running out of Claude session quotas on Max tier, you're not alone. Read this.
Some insane Redditor reverse engineered the Claude binaries with MITM to find 2 bugs that could have caused cache-invalidation. Tokens that aren't cached are 10x-20x more expensive and are killing your quota.
If you're using your API keys with Claude this is even worse. This is also likely why this isn't uniform, while over 500 folks replied to me and said "me too", many (including me) didn't see this issue.
There are 2 issues that are compounded here (per Redditor, I haven't independently confirmed this) :
1s bug he found is a string replacement bug in bun that invalidates cache. Apparently this has to do with the custom @bunjavascript binary that ships with standalone Claude CLI.
The workaround there is to use Claude with `npx @anthropic-ai/claude-code`
2nd bug is worse, he claims that --resume always breaks cache. And there doesn't seem to be a workaround there, except pinning to a very old version (that will miss on tons of features)
This bug is also documented on Github and confirmed by other folks.
I won't entertain the conspiracy theories there that Anthropic "chooses" to ignore these bugs because it gets them more $$$, they are actively benefiting from everyone hitting as much cached tokens as possible, so this is absolutely a great find and it does align with my thoughts earlier.
The very sudden spike in reporting for this, the non-uniform nature (some folks are completely fine, some folks are hitting quotas after saying "hey") definitely points to a bug.
cc @trq212@bcherny@_catwu for visibility in case this helps all of us.
Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2 is a great model.
Just make sure you're looking at v2. This is the one everyone is fanatical about right now, and for good reason.
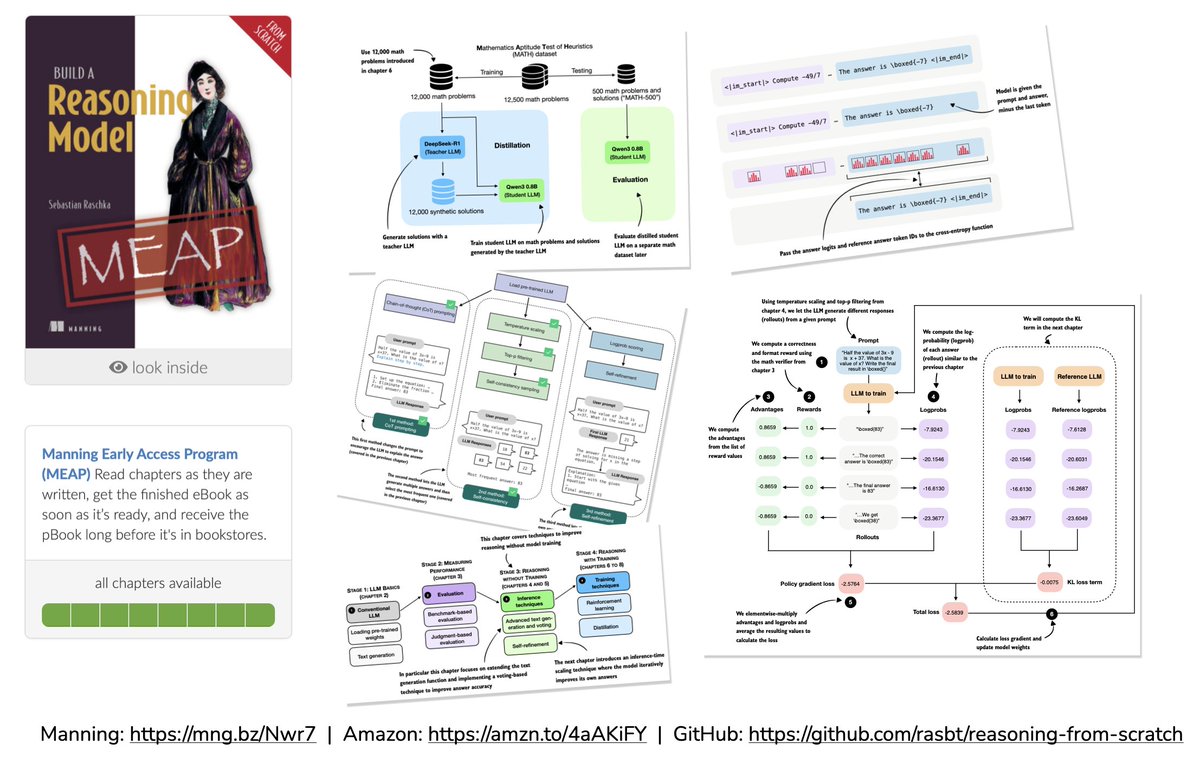
It’s done.
All chapters of Build A Reasoning Model (From Scratch) are now available in early access.
The book is currently in production and should be out in the next months, including full-color print and syntax highlighting.
There’s also a preorder up on Amazon.