We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
Solid 1M Context: A solid 1M-token context that stably sustains long-horizon work
Advanced Coding with Flexible Effort: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
Improved Architecture: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
Pure Open: An MIT open-source license — no regional limits, technical access without borders
Supporting long-horizon tasks starts with making long context engineering-usable: the model must maintain quality across long, messy coding-agent trajectories, not just accept more tokens. A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure. To this end, we substantially expanded 1M-context training for coding-agent scenarios, covering large-scale implementation, automated research, performance optimization, and complex debugging. The result is a long-context system that is not only wide in scope, but solid in execution: a practical substrate for sustained engineering work.
This capability is reflected in GLM-5.2's performance on three long-horizon coding benchmarks. FrontierSWE measures whether an agent can complete open-ended technical projects at the scale of hours to tens of hours, spanning systems optimization, large-scale code construction, and applied ML research. On this benchmark, GLM-5.2 trails Opus 4.8 by only 1%, while edging out GPT-5.5 by 1% and Opus 4.7 by 11%. On PostTrainBench, where each agent is given an H100 GPU and evaluated by how much it can improve small models through post-training, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8. On SWE-Marathon, an ultra-long-horizon software engineering benchmark covering tasks such as building compilers, optimizing kernels, and developing production-grade services, GLM-5.2 still has room to grow, trailing Opus 4.8 by 13% while remaining second only to the Opus series. Across all three benchmarks, GLM-5.2 is the highest-ranked open-source model, showing that its 1M context has translated into practical long-horizon delivery capability.
Exciting news: GLM-5.2 (Max) ranks #2 in Code Arena: Frontend, with +29pt over Claude Opus 4.7 (Thinking) and only behind Fable 5! GLM-5.2 is the best open model vs Kimi-K2.6 and Minimax-M3 by a large margin.
- #2 React and #4 HTML sub-leaderboards
- Ranks as the top model in nearly all sub categories: Brand & Marketing, Reference-Based Design, Data & Analytics, Consumer Product, Gaming, and Simulations.
Congrats @Zai_org for the incredible milestone!
🤯 GLM-5.2 is here — built for long-horizon coding and agentic tasks, now with a solid 1M-token context.
The strongest open-source coding model yet!
Available now on Ollama's cloud, hosted in the US on the latest @NVIDIAAI Blackwell datacenter GPUs. Privacy policy and zero data retention apply, as always.
Try it 👇
Claude Code:
ollama launch claude --model glm-5.2:cloud
Codex App:
ollama launch codex-app --model glm-5.2:cloud
Hermes Agent:
ollama launch hermes --model glm-5.2:cloud
Chat:
ollama run glm-5.2:cloud
More integrations and information in the model page 🧵
BREAKING: GLM-5.2 is now 1st on Design Arena.
With an Elo of 1360, GLM-5.2 has jumped ahead of the now unavailable Claude Fable 5.
And it's open weights.
This is an improvement of 4 positions and 27 Elo points to achieve one of the highest Elo scores in our code categories since Design Arena started.
Huge congratulations to the @Zai_org on the release!
Pour que vous vous rendiez compte du retard de la classe politique française sur l’IA, j’ai récupéré tous les tweets parlant d’IA de plus de 600 politiques français.
Voici la courbe sur 5 ans.
Ils ont découvert le sujet à partir de 2023. Et nous atteignons un ATH depuis ce week-end avec l’affaire Mythos.
Ne vous étonnez pas si nous avons pris du retard.
Les faits parlent d’eux-mêmes.
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
BOUM 💥 Nouvelle vidéo consacrée à l'analyse technique des rééditions rétro-modernes de l'ordinateur COMMODORE 64 (Ultimate) et de la console de jeux vidéo Neo-Geo AES (AES+), avec en bonus une analyse de la puce de silicium du synthétiseur SID du C64 🪛
https://t.co/P5lYeiLRar
@DFintelligence And électron under those ofc, that most (often the same ppl) tend to forget. Without there’s simply nothing on top.
Tho, same conclusion 🫣
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
[A partager] Vous en avez marre de lire « c’est normal, c’est l’été » (un argument claqué au sol car nous sommes au printemps !) ?
Nous avons une réponse simple : désormais, TOUTES les grandes métriques du changement climatique en France métropolitaine sont publiques, gratuites, téléchargeables et partageables
Dès aujourd’hui, @infoclimat et Data For Good lancent l’un des portails les plus complets jamais réalisés en France sur l’évolution du climat : https://t.co/6sDfa8kzXC
➡️Notre objectif ? Combattre la désinformation climatique par la science et par les faits.
➡️Notre devise ? Les faits, rien que les faits.
Journalistes, enseignants, associations, créateurs de contenus, citoyens : appropriez-vous les données. Analysez-les. Partagez-les. Vérifiez les affirmations par vous-mêmes.
Températures, vagues de chaleur, indicateurs climatiques, déséquilibre des records, tendances de fond : ON A BESOIN DE TOUT LE MONDE. Partagez le lien autour de vous.
🟢Infoclimat présente https://t.co/JLX5OVgiIU !
A l'occasion du 4eme Meet-up Météo, l'association présente son nouvel outil de "datavisualisation" destiné à objectiver les données observées par rapport aux milliards de données climatologiques accumulées depuis + de 20 ans.
1/ We are sharing additional details regarding our investigation into unauthorized access to GitHub's internal repositories.
Yesterday we detected and contained a compromise of an employee device involving a poisoned VS Code extension. We removed the malicious extension version, isolated the endpoint, and began incident response immediately.
People freaking out over my AI spend. What nobody sees: Part of what excites me so much about working on OpenClaw is that I'm trying to answer the question:
How would we build software in the future if tokens don't matter?
We constant run ~100 codex in the cloud, reviewing every PR, every issue. If a fix on main lands, @clawsweeper will eventually find that 6 month old issue and close it with an exact reference.
We run codex on every commit to review for security issues (as it's far too easy to miss).
We run codex to de-duplicate issues and find clusters and send reports for the most pressing issues.
We have agents that can recreate complex setups, spin up ephemeral https://t.co/Q1NRXLemEy machines, log into e.g. Telegram, make a video and post before/after fix on the PR.
There's codex that watch new issues and - if it fits our documented vision well, automatically create a PR of it. (that then another codex reviews)
We have codex running that scans comments for spam and blocks people.
We have codex instances running that verify performance benchmarks and report regressions into Discord.
We have agents that listen on our meetings and proactively start work, e.g. create PRs when we discuss new features while we discuss them.
We build https://t.co/bmA1XnoB7P to split all our projects into functional units to review and find bugs and regresssions.
We do the same split for security with Vercel's deepsec and Codex Security to find regressions and vulnerabilities.
All that automation allows us to run this project extremely lean.
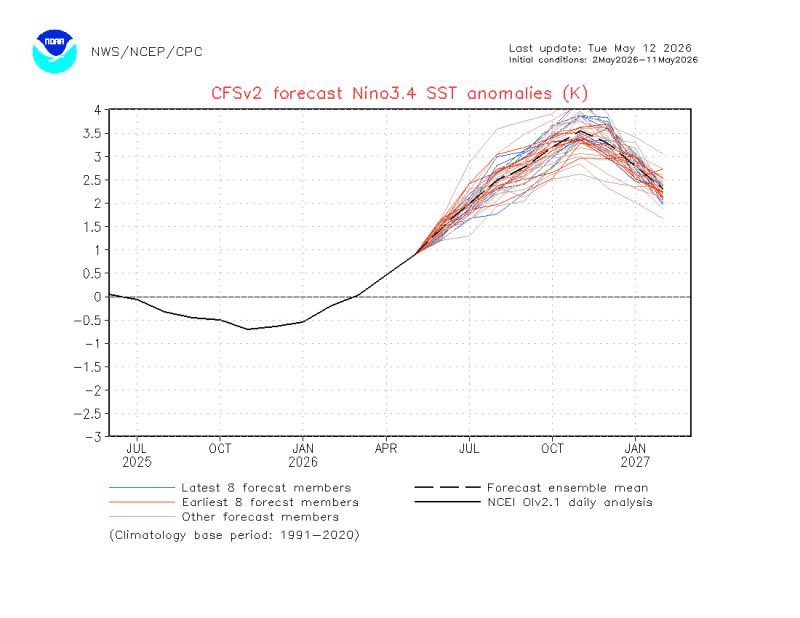
🧵 THREAD - El Niño Godzilla 2026 : ce qui arrive pourrait être le pire événement climatique depuis 150 ans. Un fil pour comprendre pourquoi. 🌊🔥
🔁 RT si tu veux que les gens comprennent ce qui se prépare.
Le #CERN rend open-source sa librairie de composants électroniques pour le logiciel KiCAD. Disponible via Gitlab, elle contient des données pour plus de 17000 composants électroniques, y compris des symboles schématiques et des empreintes de circuits.
https://t.co/BJvm3mtp7O















![SergeZaka's tweet photo. [A partager] Vous en avez marre de lire « c’est normal, c’est l’été » (un argument claqué au sol car nous sommes au printemps !) ?
Nous avons une réponse simple : désormais, TOUTES les grandes métriques du changement climatique en France métropolitaine sont publiques, gratuites, téléchargeables et partageables
Dès aujourd’hui, @infoclimat et Data For Good lancent l’un des portails les plus complets jamais réalisés en France sur l’évolution du climat : https://t.co/6sDfa8kzXC
➡️Notre objectif ? Combattre la désinformation climatique par la science et par les faits.
➡️Notre devise ? Les faits, rien que les faits.
Journalistes, enseignants, associations, créateurs de contenus, citoyens : appropriez-vous les données. Analysez-les. Partagez-les. Vérifiez les affirmations par vous-mêmes.
Températures, vagues de chaleur, indicateurs climatiques, déséquilibre des records, tendances de fond : ON A BESOIN DE TOUT LE MONDE. Partagez le lien autour de vous.](https://pbs.twimg.com/media/HJAMGtEWUAEBi2W.jpg)
![SergeZaka's tweet photo. [A partager] Vous en avez marre de lire « c’est normal, c’est l’été » (un argument claqué au sol car nous sommes au printemps !) ?
Nous avons une réponse simple : désormais, TOUTES les grandes métriques du changement climatique en France métropolitaine sont publiques, gratuites, téléchargeables et partageables
Dès aujourd’hui, @infoclimat et Data For Good lancent l’un des portails les plus complets jamais réalisés en France sur l’évolution du climat : https://t.co/6sDfa8kzXC
➡️Notre objectif ? Combattre la désinformation climatique par la science et par les faits.
➡️Notre devise ? Les faits, rien que les faits.
Journalistes, enseignants, associations, créateurs de contenus, citoyens : appropriez-vous les données. Analysez-les. Partagez-les. Vérifiez les affirmations par vous-mêmes.
Températures, vagues de chaleur, indicateurs climatiques, déséquilibre des records, tendances de fond : ON A BESOIN DE TOUT LE MONDE. Partagez le lien autour de vous.](https://pbs.twimg.com/media/HJAMGtAXoAAMXI1.jpg)
![SergeZaka's tweet photo. [A partager] Vous en avez marre de lire « c’est normal, c’est l’été » (un argument claqué au sol car nous sommes au printemps !) ?
Nous avons une réponse simple : désormais, TOUTES les grandes métriques du changement climatique en France métropolitaine sont publiques, gratuites, téléchargeables et partageables
Dès aujourd’hui, @infoclimat et Data For Good lancent l’un des portails les plus complets jamais réalisés en France sur l’évolution du climat : https://t.co/6sDfa8kzXC
➡️Notre objectif ? Combattre la désinformation climatique par la science et par les faits.
➡️Notre devise ? Les faits, rien que les faits.
Journalistes, enseignants, associations, créateurs de contenus, citoyens : appropriez-vous les données. Analysez-les. Partagez-les. Vérifiez les affirmations par vous-mêmes.
Températures, vagues de chaleur, indicateurs climatiques, déséquilibre des records, tendances de fond : ON A BESOIN DE TOUT LE MONDE. Partagez le lien autour de vous.](https://pbs.twimg.com/media/HJAMGs8WMAAsM-8.png)




















![SergeZaka's tweet photo. [A partager] Vous en avez marre de lire « c’est normal, c’est l’été » (un argument claqué au sol car nous sommes au printemps !) ?
Nous avons une réponse simple : désormais, TOUTES les grandes métriques du changement climatique en France métropolitaine sont publiques, gratuites, téléchargeables et partageables
Dès aujourd’hui, @infoclimat et Data For Good lancent l’un des portails les plus complets jamais réalisés en France sur l’évolution du climat : https://t.co/6sDfa8kzXC
➡️Notre objectif ? Combattre la désinformation climatique par la science et par les faits.
➡️Notre devise ? Les faits, rien que les faits.
Journalistes, enseignants, associations, créateurs de contenus, citoyens : appropriez-vous les données. Analysez-les. Partagez-les. Vérifiez les affirmations par vous-mêmes.
Températures, vagues de chaleur, indicateurs climatiques, déséquilibre des records, tendances de fond : ON A BESOIN DE TOUT LE MONDE. Partagez le lien autour de vous.](https://pbs.twimg.com/media/HJAM1xhWcAAORnC.jpg)