@TheHumanoidHub Well in fact this is already reality, dont need to wait for the future. Figure 02 is already deployed IN PRODUCTION doing human work. Of course ir not perfect or at human level, but the speed now is exponential. Decades is too pessimist
@Teknium@Enscion25 The alternative is to solve real world problems, train to achieve that. Here robotics may contribute a lot to collect data, feedback the results, so they can train again and check if succeed
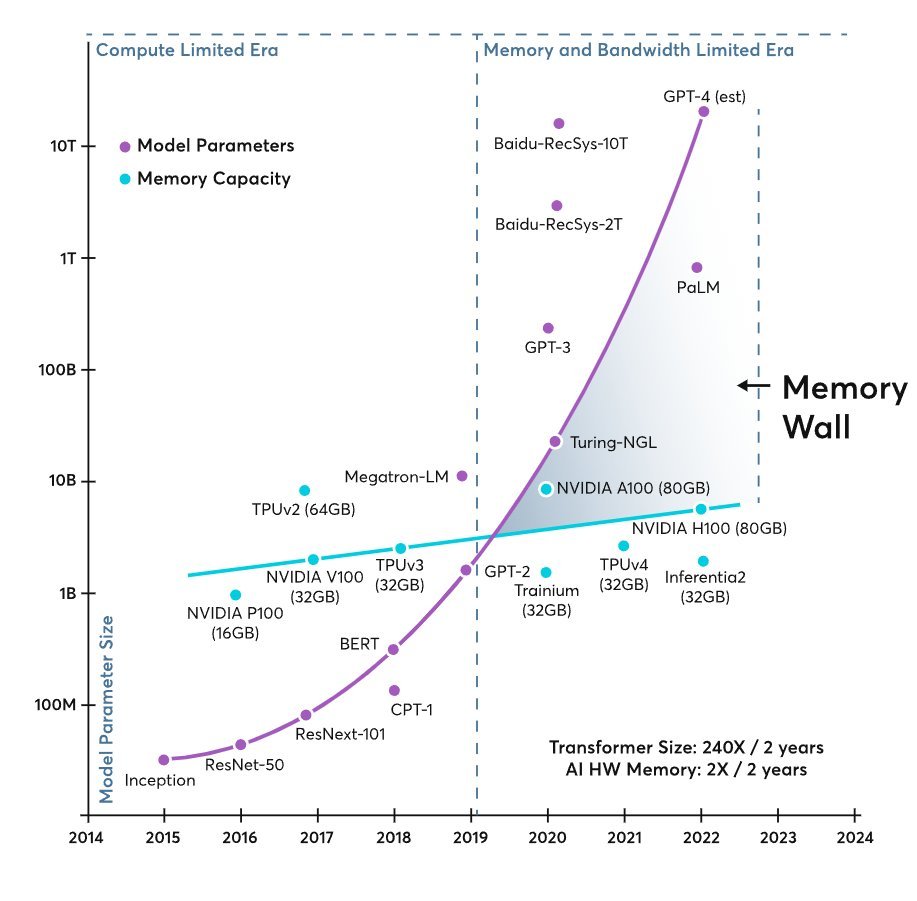
🏗️ Hardware Memory bandwidth is becoming the choke point slowing down GenAI.
During 2018–2022, transformer model size grew ~410× every 2 years, while memory per accelerator grew only about 2× every 2 years.
And that mismatch shoves us into a “Memory-Wall”
The "memory wall" is creating all the challenges in the datacenter and for edge AI applications.
In the datacenter, current technologies are primarily trying to solve this problem by applying more GPU compute power. And that's why HBM capacity and bandwidth scaling, KV offload, and prefill-decode disaggregation are central to accelerator roadmaps.
Still, at the edge, quite frankly, there are no good solutions.
🚫 Bandwidth is now the bottleneck (not just capacity).
Even when you can somehow fit the weights, the chips can’t feed data fast enough from memory to the compute units.
Over the last ~20 years, peak compute rose ~60,000×, but DRAM bandwidth only ~100× and interconnect bandwidth ~30×. Result: the processor sits idle waiting for data—the classic “memory wall.”
This hits decoder-style LLM inference the hardest.
Becasue decoder-style LLMs generate 1 token at a time, so each step reuses the same weights but must stream a growing KV cache from memory. That makes the arithmetic intensity low, since you move a lot of bytes per token relative to FLOPs.
As the context grows, the KV cache grows linearly with sequence length and layer count, so every new token has to read more KV tensors, hence the KV cache quickly dominates bytes moved.
And thats why so much of recent research focus on reducing or reorganizing KV movement rather than adding FLOPs.
Training often needs 3–4X more memory than just the parameters because you must hold parameters, gradients, optimizer states and activations.
Hence we have this huge bandwidth gap: Moving weights, activations, and KV-cache around chips/GPUs is slower than the raw compute can consume.
Together, these dominate runtime and cost for modern LLMs.
@pedroaccorsi_ Pode dar um exemplo real ? Quais outros movimentos de caixa vc usa ? A dívida vc cobsidera a variação total da dívida de curto (circulante) e longo (não circulante) ? Considera debentures tb ?
@nfalan777@rafaelgloves Código fonte não está disponível, somente os pesos dos parâmetros são abertos. Voce.pode rodar em qualquer lugar, mas não tem o código fonte