NVIDIA Nemotron 3 Ultra is now live!
Frontier accuracy, 5X greater speed, 30% lower cost.
Deploy however you need - on-premise, on the cloud, or at the edge.
Model is live on HuggingFace under the OpenMDW 1.1 license.
https://t.co/IOfAwv3jB6
Nemotron 3 Ultra is live!
Frontier-level accuracy, 5X speed and 30% lower cost among leading large open MoEs.
IMPORTANTLY, we open all SW, Data and Recipes! More details in the threads.
📜Tech report: https://t.co/L70DzNzYtK
More details in thread!
We're excited to join the NVIDIA Nemotron Coalition 💚
Frontier open models matter for the whole ecosystem.
We're bringing the RL infrastructure and environments we've built over the last year to help scale agentic capabilities.
https://t.co/bhrogG7lWH
NEMOTRON 3 ULTRA IS LIVE. OUR BEST MODEL YET. PUNCHING IN THE SAME BALLPARK AS THE OPEN FRONTIER BAYBEEEEE.
RECIPES? CHECK.
COOKBOOKS? CHECK.
TECH REPORT? CHECK.
DATA? CHECK.
ENVS? CHECK.
🚀 Introducing Nemotron-Cascade! 🚀
We’re thrilled to release Nemotron-Cascade, a family of general-purpose reasoning models trained with cascaded, domain-wise reinforcement learning (Cascade RL), delivering best-in-class performance across a wide range of benchmarks.
💻 Coding powerhouse
After RL, our 14B model:
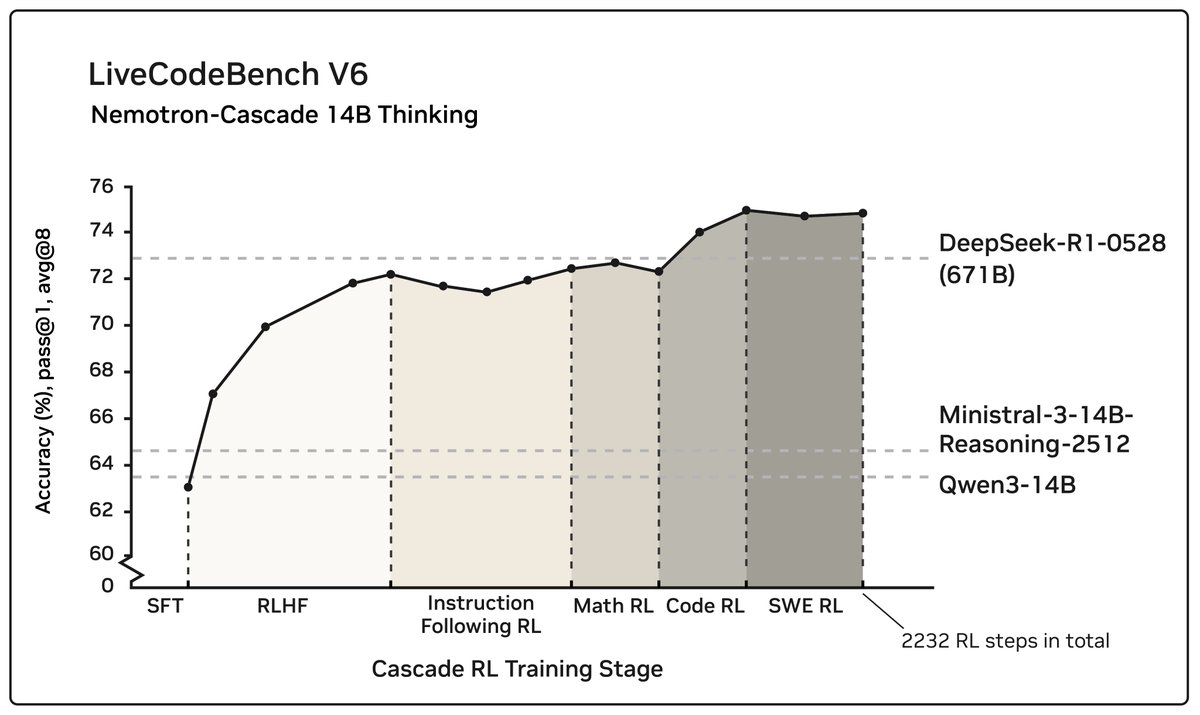
• Surpasses DeepSeek-R1-0528 (671B) on LiveCodeBench v5/v6/Pro.
• Achieves silver-medal performance at IOI 2025 🥈.
• Reaches a 43.1% pass@1 on SWE-Bench Verified, and 53.8% with test-time scaling.
🧠 What is Cascade RL?
Instead of mixing heterogeneous prompts across domains, Cascade RL trains sequentially, domain by domain, which reduces engineering complexity, mitigates heterogeneous verification latencies, and enables domain-specific curricula and tailored hyperparameter tuning.
✨ Key insight
Using RLHF for alignment as a pre-step dramatically boosts complex reasoning—far beyond preference optimization. Subsequent domain-wise RLVR stages rarely hurt the benchmark performance attained in earlier domains and may even improve it, as illustrated in the following figure.
🤗 Models & training data 🔥
👉 https://t.co/wfVcAaMocA
📄 Technical report with detailed training and data recipes
👉 https://t.co/FdMINvB4yM
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
NVIDIA releases Nemotron 3 Nano, a new 30B hybrid reasoning model! 🔥
Nemotron 3 has a 1M context window and the best in class performance for SWE-Bench, reasoning and chat.
Run the MoE model locally with 24GB RAM.
Guide: https://t.co/UAHCV8dMNC
GGUF: https://t.co/XdmG9ZSnNQ
We found a new way to get language models to reason. 🤯
No RL, no training, no verifiers, no prompting. ❌
With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.
We are excited to release Nvidia-Nemotron-Nano-V2 model! This is a 9B hybrid SSM model with open base model and training data. This model also supports runtime "thinking" budget control. HF collection with base and post trained models: https://t.co/n3M01d8lSm
We have been hard at work on improving hybrid models! Looking forward to see how mamba hybrid models shape the Reasoning LLM space. I’m Super excited to be a part of this effort.
We're excited to share leaderboard-topping 🏆 NVIDIA Nemotron Nano 2, a groundbreaking 9B parameter open, multilingual reasoning model that's redefining efficiency in AI and earned the leading spot on the @ArtificialAnlys Intelligence Index leaderboard among open models within the same parameter range.
It's built on a unique hybrid Transformer-Mamba architecture, a combination that delivers the same accuracy you expect, but with higher throughput. This enables it to achieve high performance/cost, making it perfect for real-world applications like customer service agents and chatbots.
🏗️ Hybrid Architecture: By combining the strengths of Transformer and Mamba architectures, achieves up to 6X faster throughput compared to other 8B open models and highest reasoning accuracy.
🏦 Thinking Budget: Reduces unnecessary token generation to cut costs by up to 60%, making it an ideal solution for balancing performance and total cost of ownership (TCO).
🔢 Open Datasets: The training datasets of this model are fully open, giving maximum transparency in using the model for enterprise applications.
🤗 Technical details on @HuggingFace ➡️ https://t.co/Dc87rpUGgj
🏆 Leaderboard ➡️ https://t.co/B9QulXU7iI
NVIDIA’s Graduate Fellowship Program is now accepting applications for the 2026–2027 academic year. Selected Ph.D. students receive tuition and stipend coverage up to $60K, plus mentorship and technical support from top NVIDIA researchers during an NVIDIA internship.
If you’re advancing work in AI, robotics, computer graphics, autonomous vehicles, healthcare, HPC, or related fields — this is your moment.
📅 Apply by Sept. 15, 2025: https://t.co/MnIJqxahUq
@abeirami +1 to all points made. I’d love to figure out ways to incentivize reviews (almost) as much as writing papers. Money? Credits if they are a student?
AI model post training is rapidly improving. The plot below (starting from the same base model) illustrates about 10 months of progress in the *open* post-training research.
I’m not convinced that closed research can move as fast.