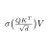Non-violence leads to the highest ethics, which is the goal of all evolution. Until we stop harming all other living beings, we are still savages. ~ T.A.Edison
Good morning! I just published a blog post about a KASLR bypass that works on modern Windows 11 versions. It leverages Intel CPU cache timings to exfiltrate the base address of ntoskrnl.exe. I hope you like it!
https://t.co/jXM3uXIcHR
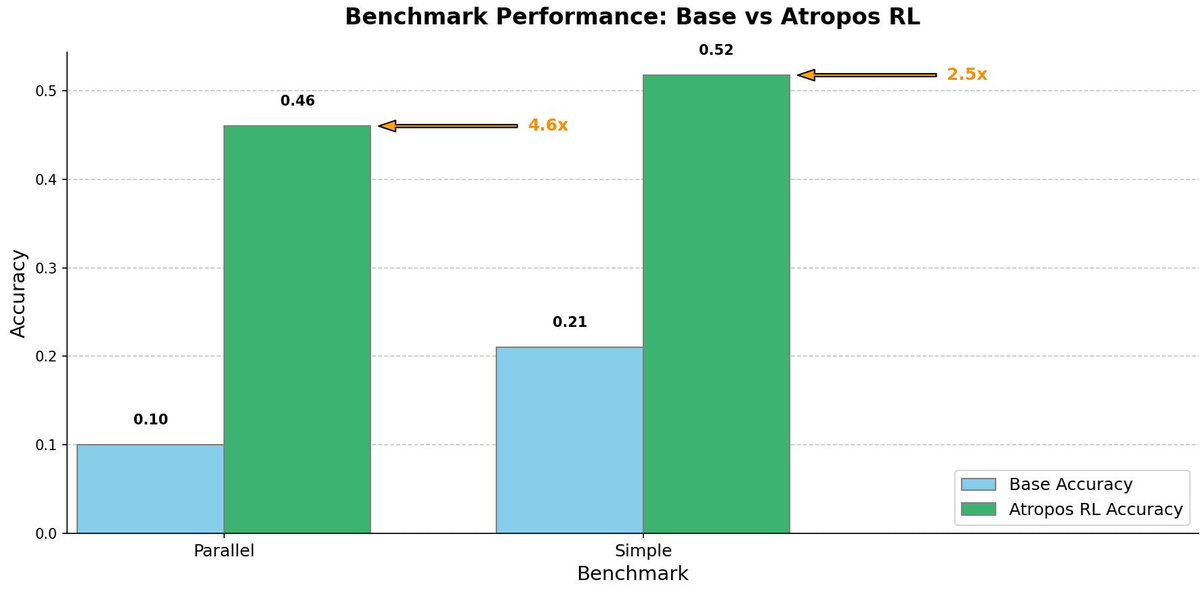
Today at Nous we released our RL Environments Gym - Atropos.
With it we've been able to train impressive models like our tool calling specialist that saw a 5x improvement on the @berkeley_ai function calling benchmark and several other models that we've released as artifacts on HF.
I hope that together we can build many more environments to broaden the targets of RL beyond math.
We will be having a hackathon in SF next month to encourage just that, with a huge prize pool too! So stay tuned.
🧵 Excited to announce ART (Agent Reinforcement Trainer), a new RL framework for easily training agents with GRPO!
Optimized for best-in-class efficiency and agentic, multi-turn interactions.
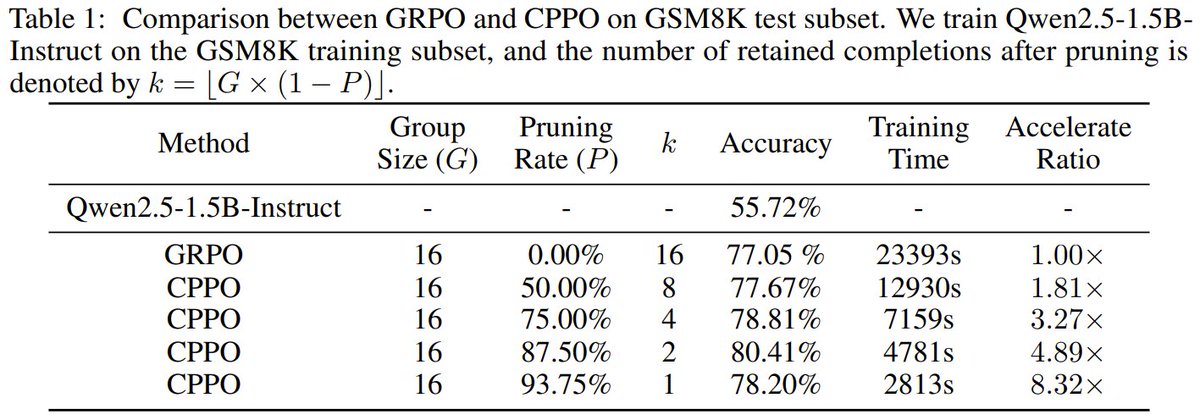
GRPO just got a speed boost! Xiamen University introduced Completion Pruning Policy Optimization (CPPO), which significantly reduces the number of gradient calculations and updates.
How fast? On GSM8K, it's 8.32× faster than GRPO, and on MATH, the speedup is 3.51×. 🚀🔥
I hear people are pretty into GRPO and RL these days, so I wrote up a pretty comprehensive research survey of recent papers I liked. Kimi 1.5, OpenReasonerZero, DAPO and Dr. GRPO.
+ discussion on if GRPO is special and further reading. https://t.co/AAkMjVTYuK
RL goes brrr in the latest TRL release!
🔥 Scale GRPO with multi-node training & vLLM's tensor parallelism
🚀 6x faster convergence with multi-step optimisation
📊 Support for domain specific rewards
Release notes 👇
https://t.co/JDlyqYYn2W
So it seems that "real CS" people got quite a huge result: anything that can be done in O(f(n)) compute can be done in O(sqrt(f(n))) memory. Wow.
https://t.co/PhSbvBA1o5
One of the simplest algorithms for sampling from a probability distribution is Random Walk Metropolis-Hastings.
It proposes new samples by taking Gaussian-distributed steps, accepting or rejecting them to maintain the target distribution.
I call this pdf the "fidget spinner".
Okay okay, spent my weekend gooning around learning GRPO math. Here's some takes.
Essentially, this is me yapping through a recap of smaller details on how GRPO is implemented, what Dr. GRPO changes, why, DAPO, connections to PPO, aggregating batches...
Reading list below.
The Climate Scam is Over..
Peer-reviewed AI analysis completely debunks all of the "man-made" claims.
Please click on the link to read or listen to the essay:
https://t.co/2rpa0ADk8C
Excited to finally share our progress in developing a reinforcement learning system to beat Pokémon Red. Our system successfully completes the game using a policy under 10M parameters, PPO, and a few novel techniques.
Blog posted below
Langevin Monte Carlo allows you to draw samples from a probability distribution using its log gradient ∇ log p(x).
By performing a sort of gradient ascent with noise you can navigate around the distribution.
Langevin MC is heavily related to modern diffusion models.
Here's part 1 of my blog series on hacking the Xbox 360 hypervisor. This covers the design of the hypervisor and hardware security features that back it. Consider it prerequisite material for part 2 which will be released next week (along with the exploit) https://t.co/FN3L2s45Rl
We made 5 challenges and if you score 47 points we'll offer you $500K/year + equity to join us at 🦥@UnslothAI!
No experience or PhD needed.
$400K - $500K/yr: Founding Engineer (47 points)
$250K - $300K/yr: ML Engineer (32 points)
Challenges:
1. Convert nf4 / BnB 4bit to Triton
2. Make FSDP2 work with QLoRA
3. Remove graph breaks in torch.compile
4. Help solve Unsloth issues!
5. Memory Efficient Backprop
If you have any questions about the challenges, please feel free to ask! We're looking for people to help push Unsloth forward - so come join us to democratize AI further!
Our past work includes:
1. 1.58bit DeepSeek R1 GGUFs: https://t.co/gALGkUg5Cg
2. GRPO with Llama 3.1 8B in a Colab: https://t.co/LFdkNxwAYg
3. Gemma bug fixes: https://t.co/7kX94PyKQR
4. Gradient accumulation bug fixes: https://t.co/Tq4c5Qwqyw
Details & submission guide: https://t.co/iXxRUTijWV
Reinforcement learning should be able to improve upon behaviors seen when training. In practice, RL agents often struggle to generalize to new long-horizon behaviors. Our new paper studies *horizon generalization*, the degree RL algorithms generalize to reaching distant goals. 1/
the TRL implementation of GRPO is technically correct if the number of gradient steps per batch is 1 because clipping never occurs.
That being said, I hope they add the clipping logic soon (is in open instruct, is in standard PPO implementations, they may have already added)
We're super stoked to publish this post. A huge shoutout to our former intern, @rainbowpigeon_ who poured his heart & soul into this 7-8 months ago. It took us a bit to polish it up but we're incredibly proud of him. Dive in & let us know what you think!
https://t.co/7YsHPq1EdL
Two new posts from @tiraniddo today:
https://t.co/StB2knG8FO on reviving a memory trapping primitive from his 2021 post.
https://t.co/sbKodaJMe9 where he shares a bug class and demonstrates how you can get a COM object trapped in a more privileged process.
Happy Reading! 📚