Met with @LisaSu today for 1.5 hours as we went through everything
She acknowledged the gaps in AMD software stack
She took our specific recommendations seriously
She asked her team and us a lot of questions
Many changes are in flight already!
Excited to see improvements coming
Thanks @dylan522p for the constructive conversation today. Feedback is a gift even when it’s critical. We have put a ton of work into customer and workload optimizations but there is lots more we can do to enable the broad ecosystem. I appreciate all the feedback and desire to engage with @AMD. We are committed to building a world-class open software stack. Lots planned for 2025. Happy holidays to all!
Excited to announce the next chapter in gaming greatness! The world’s best gaming processor, the @AMD Ryzen 7 9800X3D is here to power our community to new heights. Let’s level up together! 🚀🎮
Memory Matters for LLM.
While everyone is rushing to provide the serverless Llama3-405b model, I want to talk about one key choice that matters a lot, especially for dedicated enterprise deployments when traffic is not very high: memory.
- The normal deployment of a model the size of 405b takes 8xH100 GPUs with a total of 640G memory. You'll quantize the weights to int8 or fp8, leaving about 230G memory for KV cache and others. Doable with care.
- If you need to do fine-tuning (full fine-tuning, or Lora, or Medusa), memory size is going to be stressful. Your choices are probably (1) do quantized training with careful control of scale, (2) go distributed, both require extra care.
- @AMD MI-300 is a particularly interesting card for this scenario, as each card has 192G memory - 4 cards with a total of 768G memory will be very comfortably host the model, as well as giving you a good amount of remaining memory for KV cacheing / prompt cacheing and other tricks.
- Attached is a screenshot showing our runtime ("tuna") running the 405b model on 4xMI300 out of the box at @LeptonAI. Speed is good.
- We know there are a lot of claims out there saying one is faster than the other, but based on our experience, with reasonable quantization, continuous batching, chunked decoding and other known optimization techniques, MI300 and H100 exhibit on-par performance.
- We haven't thoroughly tested some of the optimization techniques, such as Medusa, on the 405b models. So it is hard to say for sure which GPU takes the lead.
- The upcoming Blackwell GPUs will have 192G memory as well, so we are definitely seeing appetite for larger models.
- Large memory definitely gives you opportunity to do more within one box: 1.536TB memory per machine means you can do almost whatever you want with the 405b sized models: fine-tune them, serve multiple models at once, hot swap Loras, etc.
It's exciting times for model, and also exciting times for infra.
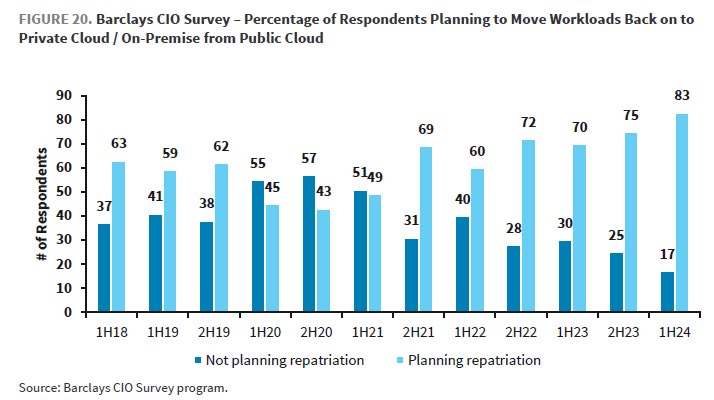
Multi cloud including on prem and collocation is the clear trend. Somewhat driven by the growth in AI inference and data gravity, 83% of enterprise CIOs in Barclays survey plan to repatriate at least some workloads in 2024, up from low point of 43% in 2020 H2.
Now @DellTech with President, GIS (DC and edge), Arthur Lewis:
-PowerEdge adding MI300X
-8 cards, some wild bandwidth
-Using Infinity Fabric too (interesting)
- 'focus on out of the box LM simplicity'
-'Open for business, taking orders now' (crowd cheers)
$DELL
@AMD and @Dell say that 83% of data today resides on prem. Makes sense. Dell will support the MI300X on its servers. We think the on-prem enterprise opportunity for AMD MI300 may be greater than the cloud.
Exciting news 🎉 Ultra Ethernet Consortium (UEC) opens doors to new member applications & new UEC memberships will begin on November 15, 2023! Read our newsletter for more info: https://t.co/YQ2TPSpPiJ #UltraEthernet
Given the other guys news….AMD has EPYC and Ryzen options…
#amd#epyc#ryzen#embedded#togetherweadvance
“Intel Exiting the PC Business as it Stops Investment in the Intel NUC”
https://t.co/MsZToxwcUk https://t.co/9KsWdPAFl1
Innovation continues, even in refrigerators!!!!
Love my new LG, it’s EPYC!!!!
Jay Boisseau Jay Kirkland Paul Perez @drjmetz Jaime Edwards Chuck Gilbert @SR_fellow#innovation#LG https://t.co/lxYHgnnLvD
With the release of PyTorch 2.0 and ROCm 5.4, we are excited to announce that LLM training works out of the box on AMD datacenter GPUs, with zero code changes, and at high performance (144 TFLOP/s/GPU)! We are thrilled to see promi…https://t.co/GNLN7yVEBa https://t.co/FV0lF15F6L
From Exascale (Frontier) to Exadata (Oracle X10M), AMD provides Exa-Results.
Up to 3X more transaction throughput, 3.6X faster analytics, and 50 percent more consolidation compared to previous generation
"Available now in both O…https://t.co/tu1kxJj0Yv https://t.co/Sh8VQhdz8R
Anyone remember the theoretical memory BW/Core chart from a few months ago. Well here is a measured version with interfering actors.
Showing the power of the EPYC Zen4 chiplet architecture in action. Incredible difference in the shape of the graphs.…https://t.co/rBN1D0rC9O
OCP Server Community –
On June 21st, the DC-MHS group will have a Public Meeting starting at 0800 Pacific Time.
https://t.co/UY4oBs4tdF
The meeting will be consist of two sections:
Between 0800 and 0830, there will be a recorded call for general updat…https://t.co/BaVuBghYqs
"The best defense is a good offense, and as it turns out, the best offense is also a good offense. So while AMD is all polite-like in its presentations, rest assured that with the ever enwidening and embiggening Epyc server chip li…https://t.co/JYbEUXDobF https://t.co/AvV4J4q1bl