@levelsio@cursor_ai@boltdotnew@heyglif@_MaxBlade For the #vibejam, I am working on an F1 race simulator :
✅(mostly done) Qualifying (solo) lap : nail the throttle, brakes, and gears to make the fastest lap
❌(coming up) Race (multiplayer) : overtakes, tyres management, slipstreams/dirty air, etc.
@levelsio@cursor_ai@boltdotnew@heyglif@_MaxBlade For the #vibejam, I am working on an F1 race simulator :
✅(mostly done) Qualifying (solo) lap : nail the throttle, brakes, and gears to make the fastest lap
❌(coming up) Race (multiplayer) : overtakes, tyres management, slipstreams/dirty air, etc.
Hey,
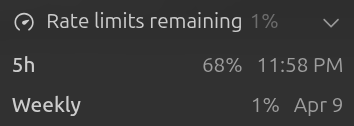
I’ve used Codex intensively over the past month and very rarely hit the token limit, but today I reached the daily token limit after just a few prompts.
Was the token limit reduced, or what happened?
I just started an AI study group. We plan to study theory and build real projects in machine learning, deep neural networks, LLMs, and agentic AI (RAG systems, agents, and more).
If someone is interested, DM me to join :)
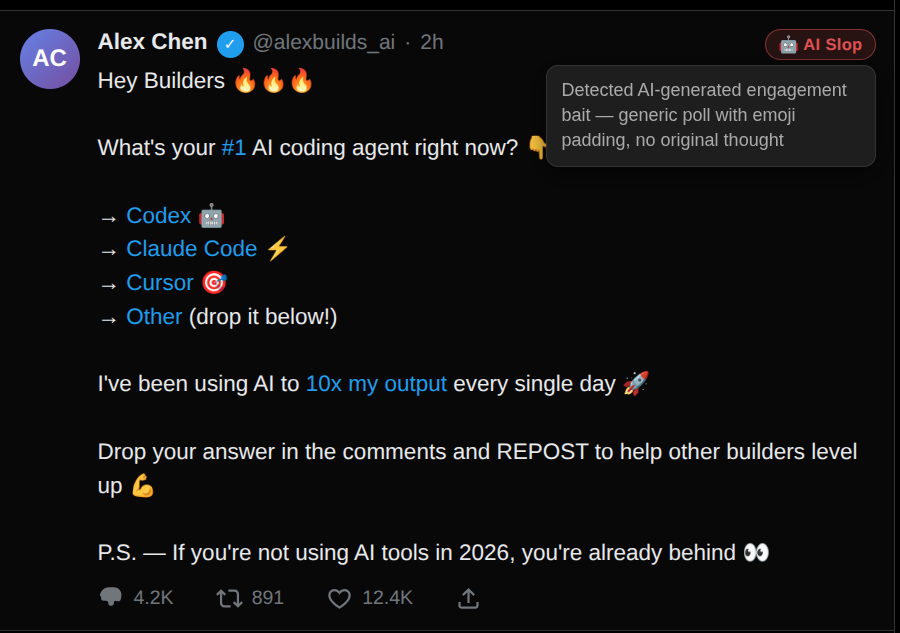
My X feed is full of AI slop, engagement bait, and replies that contribute absolutely nothing. Sound familiar?
I'm working on a browser extension that runs a local LLM to flag low-quality tweets (and replies) with a small badge (check the demo screenshot). Mostly a fun side project to mess around with LLMs.
The issue is that it (will likely) use a pretty small model (Phi, Gemma, Llama-3.2-1B, etc.), so I genuinely don't know how well it'll catch slop. And I have no clue whether it'll make my PC sound like a jet engine every time I open X.
I've been trying to make it fully self-contained as a Chrome Extension using WebLLM but it's turning into a debugging nightmare. Having to enable unsafe Chrome flags and experimental features just to (maybe) get it working doesn't sound right.
I am leaning toward spinning up a local Ollama server and having the extension call that instead.
Anyone have feedback on the idea or the approach?
I'm looking to put together a serious AI study group
The goal is simple: consistent weekly sessions where we actually build, learn, and push each other. Not a passive group, but one where people show up, contribute, and stay engaged.
Some directions we could take:
* Agentic AI (RAG systems, AI agents, LLMOps, etc.)
* Traditional ML and deep learning (feature engineering, models, theory)
* Project-based learning with real implementations
* Paper discussions and breakdowns.
I’m flexible on structure. We can decide together what works best, as long as the group stays active and committed.
If you're interested, reply (or DM) with what you want to focus on, how you'd like sessions to run, what direction to take, etc.
If enough motivated people join, I’ll organize the first session and set up the group.
I'm looking to put together a serious AI study group
The goal is simple: consistent weekly sessions where we actually build, learn, and push each other. Not a passive group, but one where people show up, contribute, and stay engaged.
Some directions we could take:
* Agentic AI (RAG systems, AI agents, LLMOps, etc.)
* Traditional ML and deep learning (feature engineering, models, theory)
* Project-based learning with real implementations
* Paper discussions and breakdowns.
I’m flexible on structure. We can decide together what works best, as long as the group stays active and committed.
If you're interested, reply (or DM) with what you want to focus on, how you'd like sessions to run, what direction to take, etc.
If enough motivated people join, I’ll organize the first session and set up the group.
My X feed is drowning in AI slop, engagement farmers, and replies that add zero value. Yours too?
I'm building a browser extension that runs a local LLM to flag low-quality tweets (and replies) with a small badge (see the demo screenshot). It is mostly for fun and to play with LLMs.
The issue is that it would run a very small model (Phi, Gemma, Llama-3.2-1B, etc.), so I'm not sure how well it'll actually detect slop. And I have no idea if it'll make my PC scream every time I open X 😅
I have been trying to make it fully self-contained as a Chrome Extension with WebLLM, but it is turning into a debugging nightmare. Activating unsafe Chrome flags and experimental features just to (try to) get it running doesn't feel... safe.
I'm thinking of spinning up a local Ollama server and having the extension call it instead.
Does anyone have feedback on the idea or the approach?