Pondering: “[Roughly], causal inference tells us whether based on our causal beliefs, the association between two variables is bigger or smaller than their true casual relationship.”…and another sentence concerning beliefs about causal relationships affecting estimates
What is Causal Inference?
Causal Inference is a new science of causation. This field is nothing less than a revolution in how scientists understand data. Read on to learn more.
This is the first post in a series based on the Book of Why by Judea Pearl. I will be reading the book and sharing the big insights with my followers.
When I first started learning causal inference, I didn't have a clear idea of the problems that casual inference was trying to solve. My misconceptions made it harder to understand the material than it would have been otherwise.
So, before we get into the ideas of the book, I want to help you avoid these common misconceptions.
1. Causal Inference is NOT just regular science
All sciences strive to infer causes within their domain of expertise. Therefore, it might not be obvious to you what makes casual inference any different. This is the reason why I sometimes call this new field mathematical causal inference. This term emphasizes that what sets causal inference apart is the mathematical framework it uses to describe causation.
2. Causal Inference is NOT directly about inferring causes
Based on the name, new learners often think causal inference is solving the following problem:
Given a list of candidate variables, how can we select the ones that have a real causal effect on our outcome of interest?
This is not what causal inference does. Causal inference is solving a different problem:
Assuming our beliefs about the causal relationships between all the variables is accurate, what is the best estimate of the causal relationship between a particular candidate variable and the outcome of interest?
Very roughly speaking, causal inference tells us whether based on our causal beliefs, the association between two variables is bigger or smaller than their true casual relationship.
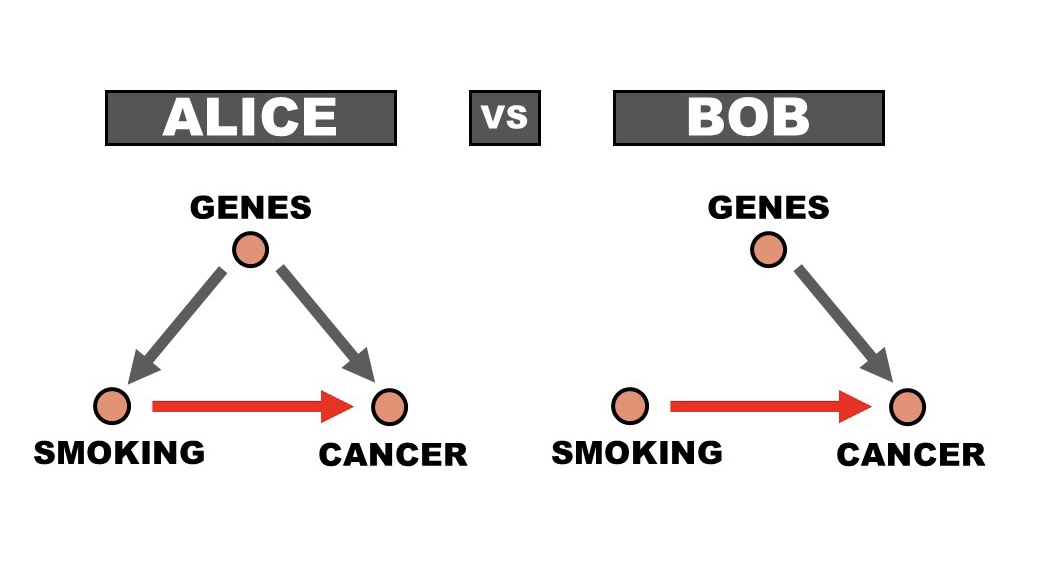
3. The Example of Alice and Bob
Alice thinks genes strongly affect addictive behaviors like smoking. She also thinks genes have an effect on who gets cancer. Bob agrees that genes very likely have an effect on cancer, but Bob thinks complicated social behaviors like addiction are completely due to social factors, not genes.
Causal inference allows us to evaluate the same data according to both Alice's and Bob's beliefs about the underlying causal relationships. This allows for various outcomes:
1. Avoiding unnecessary arguments. If Alice and Bob get very similar estimates for the causal relationship between genes and cancer, this implies that the disagreement about the relationship between genes and behavior is not that important. This allows scientists to move forward by focusing on the factors that really matter.
2. Agreeing to disagree. If the difference in estimates of the casual relationship between genes and cancer is large, causal inference allows both Alice and Bob to continue to explore the same data according to their very different assumptions about the causal relationships. This gives scientists and policy makers autonomy to pursue different interpretations of the same data.
4. Casual Inference builds doesn't replace statistics. It makes it more powerful.
Causal inference allows us to adjust our statistical estimates of the strength of particular casual relationships based on our beliefs about the casual relationships between the variables. This is why some experts in causal inference (like the epidemiologist @epiellie) prefer to use the term causal effect estimation to refer to the field causal inference.
That's it for now. My next post (coming soon!) will explore how causal inference creates a mathematical model of causation and what makes this approach so special. (You can find these posts using the hashtag #KareemReads)
Follow me (@kareem_carr) for more content like this. If you want to show support, like and retweet the thread.
Science Twitter is dying.
Good science content is getting harder to find on our timelines.
I think I know why.
Science content doesn't look like what the new Twitter algorithm wants to see. The algorithm wants long chains of comments. Real discussions. Discussions keep us engaged with the site. They're also a more effective place for Twitter to put their ads.
Great science content tends to generate plenty of likes and bookmarks, but very little real discussion. People say "Thanks!" and quickly move on.
If we want Twitter to surface more scientific content, science twitter needs to evolve.
We need to transition to having deeper more substantive discussions about science.
This isn't a bad change. If we were having deeper more engaging discussions about science on Twitter, we'd probably all learn more and enjoy Twitter more at same time.
This weekend I conducted an experiment.
I tweeted out a bunch of provocative claims. Not as "bait", as some people called it, but as a jumping off point for debate and discussion.
There were hundreds of comments. Three days later, it's still going. There was also quite a bit of negativity. Twitter has trained us to react badly to strong disagreement.
I learned a lot from this experiment.
I learned that discussions can work but we need to keep an eye on the negativity. Here is my call to action:
HELP ME SAVE SCIENCE TWITTER!
I'm a large account. I can be a platform for regular science discussions, but I can't do it by myself.
I NEED YOU.
I want to be a platform for "Question of the Day" discussions. Here's how it would work:
• I post a prompt for discussion
• You respond, interact with others, and have fun.
Please engage with this Tweet! Share potential discussion ideas in the comments!
Anything related to data analysis, math, statistics, machine learning, computer science, AI and philosophy science is fair game.
If a topic idea interests you, like the comment so I know what to focus on.
ChatGPT consistently gets this very basic question wrong.
Does that mean ChatGPT is useless? Not necessarily!
Using this as an example, let me show you how to take your prompts to the next level. 👇
The newest version of {gt} lets you create interactive web tables 🥳
And it's super easy to manage. Everything is funneled through one function opt_interactive() 👌 #rstats
matchingR - Computes matching algorithms quickly using Rcpp. Implements the Gale-Shapley Algorithm to compute the stable matching for two-sided markets, such as the stable marriage problem and the college-admissions problem. Implements Irving's ... #rstats https://t.co/OJqAAZK964
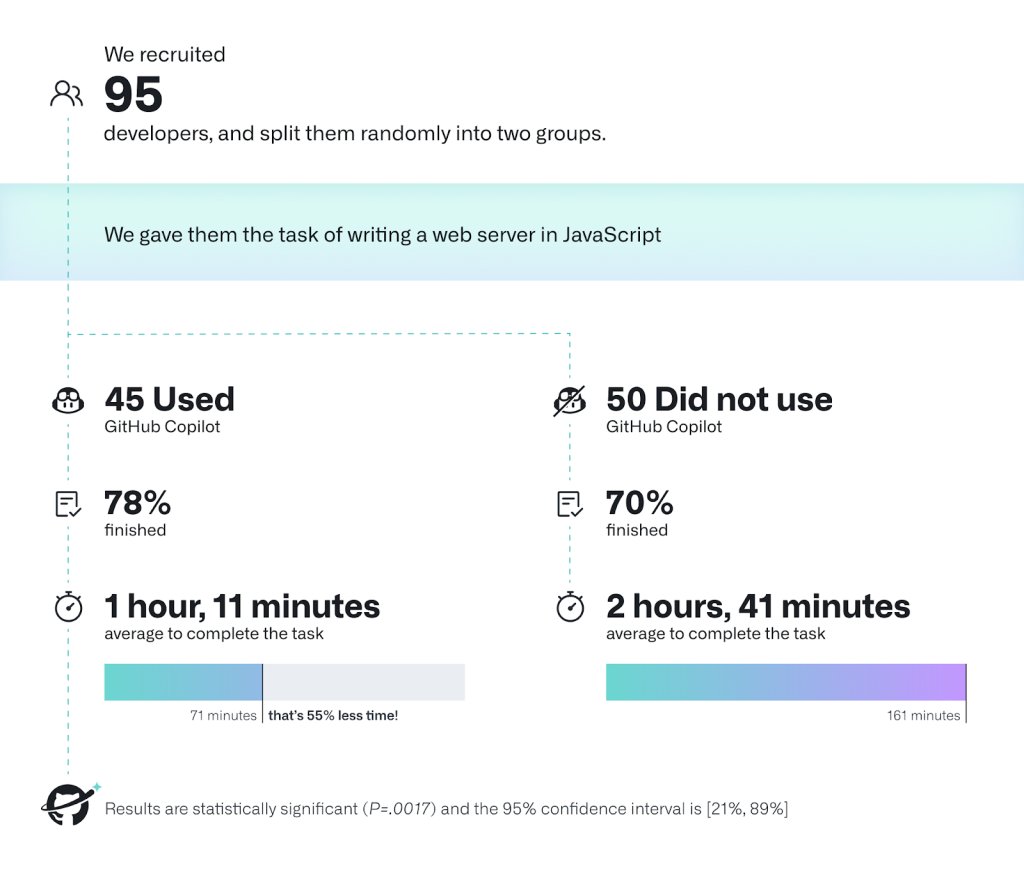
👀Two early papers find the effects of generative AI on knowledge work are completely unprecedented in modern history
Separate studies of both writers and programmers find 50% increases in productivity with AI, and higher performance and satisfaction. And this is just the start.
Did you miss my @UMSSDAN workshop on using 2021 American Community Survey @uscensusbureau data in #rstats a few weeks ago?
The workshop video is now posted, check it out!
https://t.co/Q293OESCzW
This month's #rstats meetup is on Tues Feb 28th w/ David Smith (@revodavid) who will be talking about Copilot!
💻 Fully VIRTUAL
🎫 Also we'll be giving away a FREE ticket to @DataCouncilAI Austin & D4 Conference (@d4con) to 2 lucky attendees!
RSVP now➡ https://t.co/b2imkKmKu5
Really happy to share this essay I wrote about career advocacy and its benefits.
I hope it debunks some myths and misconceptions that exist about mentoring.
#ds4a#datascience#datafam#datacareers
https://t.co/yvfu2sozuq
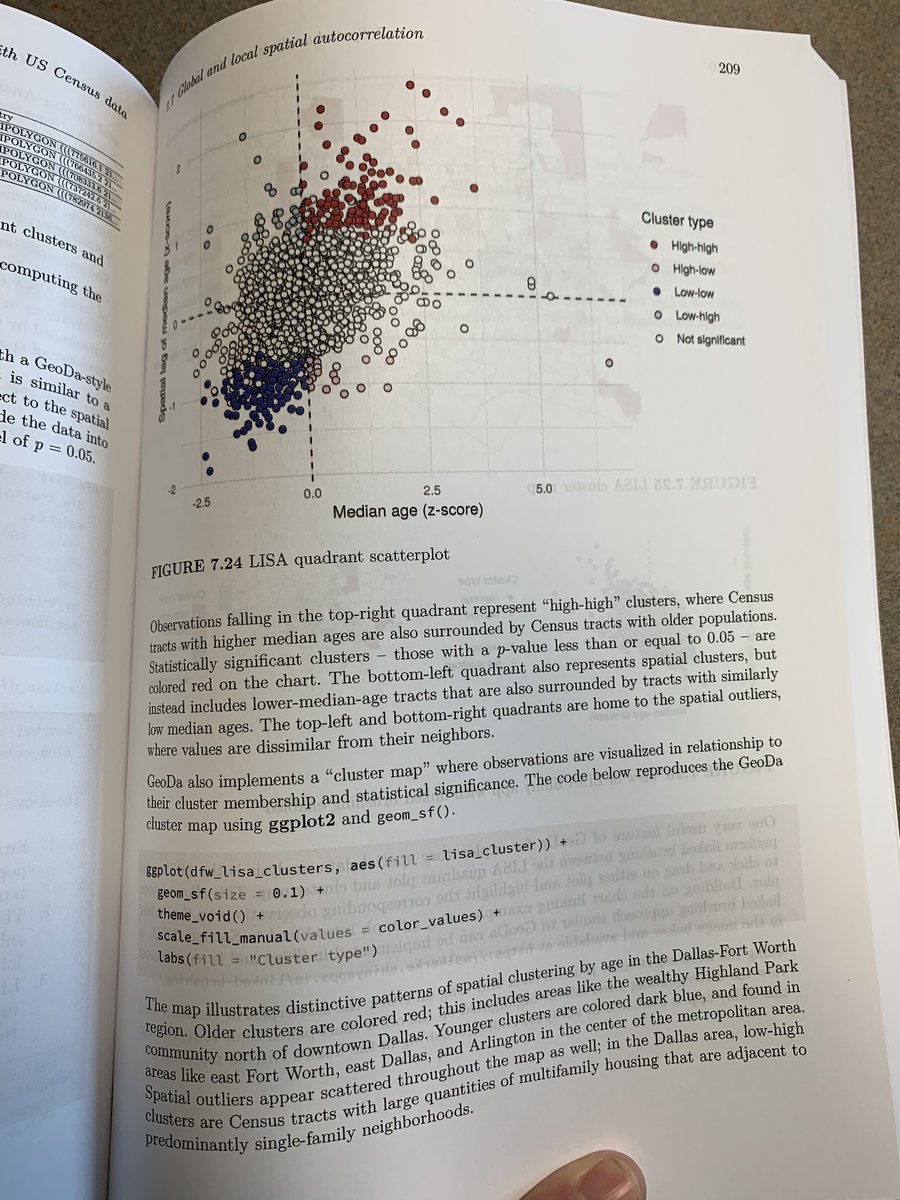
Writing a book... can take a long time, with years of chapter overhauls and revisions. Today is finally release day of "Analyzing US Census Data"!
You can buy a copy from Routledge (https://t.co/6F32TSm6IA) or Amazon (https://t.co/zdG0wmrkVy) - I appreciate it!
#rstats
My book Analyzing US Census Data is now in print! I’m really happy with how it turned out.
Thanks so much to @lara_crc and the @CRCPress team. You can order your copy today! https://t.co/6F32TSlyT2; https://t.co/zdG0wmqN60
#rstats
Join us at this Tuesday's upcoming @ONSSUG meeting with @rick_pack2 on "R and Python Uses of U.S. Census Data in Kaggle GoDaddy Forecasting Competition"
https://t.co/8nasjRCn1C
Do you want feedback on your #rstats code but are too 🙈 shy 🙈 to ask?
🤖 gpttools 📦 can now suggest code improvements and explains what it did 🤯! #ChatGPT
It's almost like a modern-day rubber 🦆 that talks back
https://t.co/9f54V4oiMs