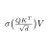Every time GitHub has an outage our team is paged. Incidents at Vercel get automatically filed by anomaly detection systems.
We just detected an outage 16 minutes before their status page changed. Deployments suddenly dipped and surged.
Despite all the chatter about coding AGI, the reality is that software infrastructure remains an extremely hard problem.
I have no doubt the GitHub team is highly competent, and there's no shortage of models and agents available to them. Don't forget this is the company that brought us Copilot, the first major breakthrough product in AI coding. Yet clearly the prompt "/goal scale GitHub, make everything extremely fast, make no mistakes" is not enough.
The hard parts of software remain very hard, especially under unprecedented demand, as more people join in on the fun of building new things.
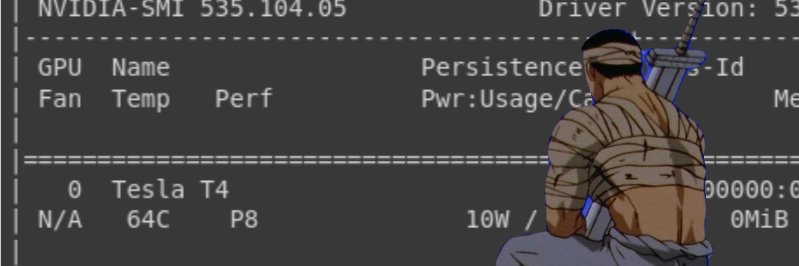
SynthID has already watermarked over 100 billion pieces of content, but transparency is a team sport.
That’s why we’re partnering with @OpenAI, @ElevenLabs and Kakao to add SynthID watermarking to their models – accelerating the industry-wide momentum we started with @NVIDIA.
We’re training models wrong and it’s due to chatGPT. Even the modern coding agents used daily still use message-based exchanges: They send messages to users, to themselves (CoT) and to tools, and receive messages in turn.
This bottlenecks even very intelligent agents to a single stream. The models cannot read while writing, cannot act while thinking and cannot think while processing information.
In our new paper, see below, we discuss LLMs with parallel streams. We show that multi-stream LLMs can …
🔵Be created by instruction-tuning for the stream format
🔵Simplify user and tool use UX removing many pain points with agents and chat models (such as having to interrupt the model to get a word in)
🔵Multi-Stream LLMs are fast, they can predict+read tokens in all streams in parallel in each forward pass, improving latency
🔵 LLMs with multiple streams have an easier time encoding a separation of concerns, improving security
🔵 LLMs with many internal streams provide a legible form of parallel/cont. reasoning. Even if the main CoT stream is accidentally pressured or too focused on a particular task to voice concerns, other internal streams can subvocalize concerns that would otherwise not be verbalized.
Does this sound related to a recent thinky post :) - Yes, but I don’t feel so bad about being outshipped with such a cool report on their side by 23 hours. I’ll link a 2nd thread below with a more direct comparison. I actually think both are complementary in interesting ways.
Twitter’s algorithm is optimized for addiction, not for us. We deserve better.
We’re releasing Bouncer today so you can take back control of your feed. Describe what you don't want, and Bouncer removes it.
It’s free, doesn’t collect your data, and will be open source soon.
If you find Claude Code with local models to be 90% slower, it's because CC prepends some attribution headers, and this changes per message causing it to invalidate the entire prompt cache / KV cache.
So generation becomes O(N^2) not O(N) for LLMs.
i don't know what the future holds, but the following are still true today:
- if you don't outsource menial tasks to language models, ngmi
- if you outsource all of your thinking to language models, ngmi
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
There was a flippening in the last few months: you can run your own LLM inference with rates and performance that match or beat LLM inference APIs.
We wrote up the techniques to do so in a new guide, along with code samples.
https://t.co/vpNGPZ0vgM
oh you’re using claude code? everyone’s using open code. just kidding we’re all on amp code. we’re using cline, we’re using roo code. we just forked our own version of roo. were using kilo code. we were on coderabbit but their ceo yelled at us so now we’re using qorbit. apple just acquired them for $30bn so we just migrated our entire team to slash commands. one guy is still on aider. the PM is on loveable. he just shipped a new product on replit. the intern installed a slackbot that lets you chat with your spreadsheet. legal is still reviewing devin’s enterprise contract. we evaluated junie for three ukrainians using jetbrains. someone in slack just asked “has anyone tried amp?” we are using goose for scripts. next week we’re piloting augment code. the CTO heard good things about trae. our CEO is friends with the guy from conductor. our CFO resigned. our CISO said we’ve had fourteen supply chain attacks in the last week. we’re shipping the worlds most expensive todo app.
A good-faith question so I'll respond here...
So ChatGPT is pretty broad these days but basically it's a foundation model that is trained on lots of raw text+images+audio+etc. and can be used for a variety of downstream use-cases.
You can do something similar with medical data. There are so many ways to do this. For example, you can just build a direct ChatGPT-like model for medicine, which is Google is doing with MedGemini.
You can also train specific models for different medical domains. For example, I contributed to a project training a foundation model for radiology (CheXagent). Just like how you can upload pictures to ChatGPT and ask it questions, you could upload chest X-ray pictures to CheXagent, ask questions to it, get diagnosis, generate potential radiology reports, etc. and it's trained similar to how ChatGPT is trained for general-purpose use-cases.
But see how this is different from previous medical AI models. For example, the first radiology AI approved by FDA only did one thing specifically: detect in a head CT if there's a hemorrhage in the skull.
The training of specialist models for individual tasks ("is it cancer type x or not?") is the old way. The new way is training a model general foundation model for medicine that can do multiple tasks altogether ("what type of cancer is it?"). this approach is more efficient and scalable.
think about ChatGPT... before you used to have separate AI models to translation from one language to another, to summarize text, to fix grammar mistakes, etc. but now that's all done with one model. A similar sort of paradigm shift is underway in medicine now.