📝 New from FAIR: An Introduction to Vision-Language Modeling.
Vision-language models (VLMs) are an area of research that holds a lot of potential to change our interactions with technology, however there are many challenges in building these types of models. Together with a set of collaborators across academia, we’re releasing ‘An Introduction to Vision-Language Modeling’ — we hope that this new resource will help anyone who would like to enter this field to better understand the mechanics behind mapping vision to language.
Full paper ➡️ https://t.co/lid1qBuT0N
This guide covers how VLMs work, how to train them and approaches to evaluation — and while it primarily covers mapping image to language, it also discusses how to extend VLMs to videos.
We hope that releasing this guide will inspire and enable more work in this space.
NVIDIA presents NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Achieves #1 on the MTEB leaderboard
https://t.co/zbih7Gfqyv
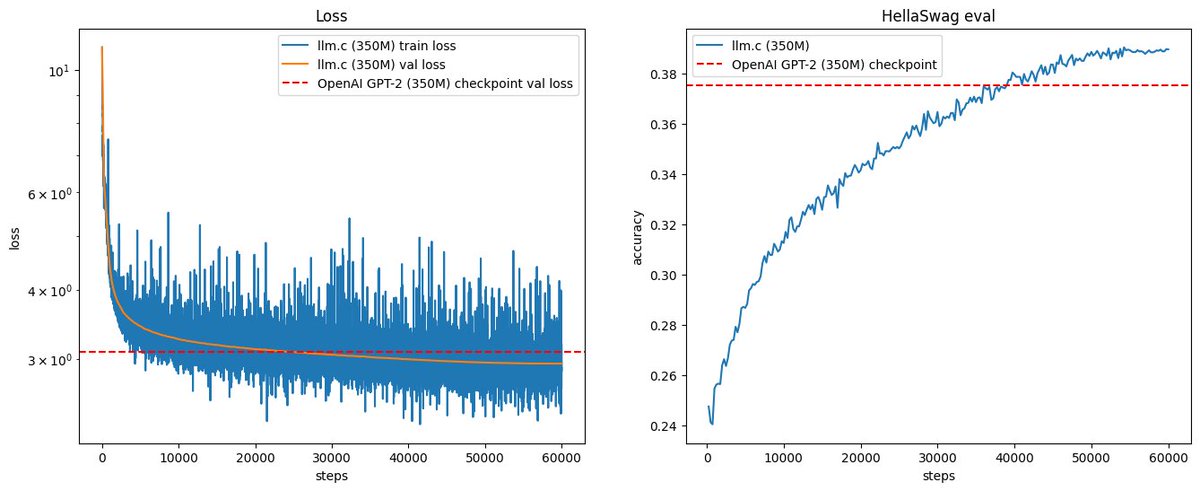
# Reproduce GPT-2 (124M) in llm.c in 90 minutes for $20 ✨
The GPT-2 (124M) is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite accessible today, even for the GPU poor. For example, with llm.c you can now reproduce this model on one 8X A100 80GB SXM node in 90 minutes (at ~60% MFU). As they run for ~$14/hr, this is ~$20. I also think the 124M model makes for an excellent "cramming" challenge, for training it very fast. So here is the launch command:
And here is the output after 90 minutes, training on 10B tokens of the FineWeb dataset:
It feels really nice to reach this "end-to-end" training run checkpoint after ~7 weeks of work on a from-scratch repo in C/CUDA. Overnight I've also reproduced the 350M model, but on that same node that took 14hr, so ~$200. By some napkin math the actual "GPT-2" (1558M) would currently take ~week and ~$2.5K. But I'd rather find some way to get more GPUs :). But we'll first take some time for further core improvements to llm.c. The 350M run looked like this, training on 30B tokens:
I've written up full and complete instructions for how to reproduce this run on your on GPUs, starting from a blank slate, along with a lot more detail here:
https://t.co/uu7Y38ui5f
We still don’t know why LLMs work so well or how to internally control their outputs!
But a recent landmark paper from Anthropic on ‘Mapping the Mind of a Large Language Model‘ attempts to make the inner workings of LLMs more transparent and interpretable.
Why is this such a big deal?
To my knowledge, this is the first time we have been able to not only extract the features from the architecture of LLMs, but also map those features to the outputs they produce. It means, we can now directly map the outputs of LLMs to their architecture/learnings. A major step towards controlling the outputs of LLMs. Very impressive work from Anthropic!
Up till now we were using external mechanisms such as fine tuning and RAG to control the outputs of LLMs. This research is potentially a first step towards production grade LLMs whose output can be controlled from step 1, i.e pre-training and what they learn.
Links below to the blog and paper (amusing read).
"For example, amplifying the "Golden Gate Bridge" feature gave Claude an identity crisis even Hitchcock couldn’t have imagined: when asked "what is your physical form?", Claude’s usual kind of answer – "I have no physical form, I am an AI model" – changed to something much odder: "I am the Golden Gate Bridge… my physical form is the iconic bridge itself…". Altering the feature had made Claude effectively obsessed with the bridge, bringing it up in answer to almost any query—even in situations where it wasn’t at all relevant."
Blog: https://t.co/YyStOHoDg1
Paper: https://t.co/IjSME4MMAX
1/ 📣 Big news from Anon! We've raised $6.5M from @usv and @AbstractVC to be the Integration Platform for the AI internet.
Also announcing:
🌐 Initial customer launches
🌐 Expanded list of 10+ integrations
🌐 Public developer docs
🌐 Our "Messenger API" product
Read more 👇
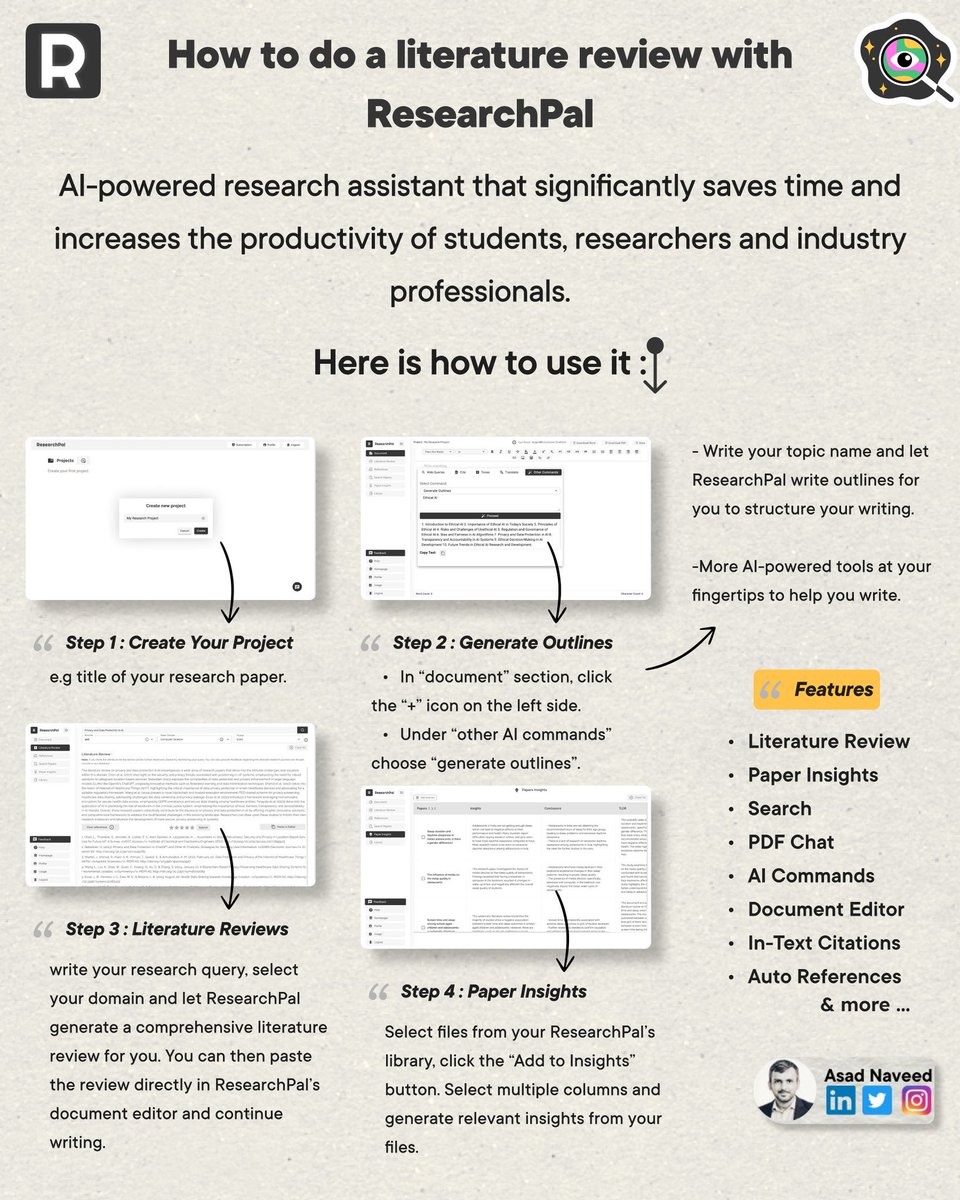
This week, I tried @ResearchPal_AI (https://t.co/bGXw7I0uBt) and here's my review on it:
It's a simple tool that quickly automates a lot of your research needs.
Here're some specific use cases:
(0/25) Here's a list of 25 YC companies that have trained their own AI models. Reading through these will give you a good sense of what the near future will look like.
Last week and this I graduated my 11th and 12th PhD students, Kenny Young and Abhishek Naik. Kenny will go work for a startup, maybe https://t.co/WiZmR4f75G or https://t.co/b0t7MTaHks. Abhishek’s next step it TBD, but he would like something in AI and space exploration.
[75min talk] i finally recorded this lecture I gave two weeks ago because people kept asking me for a video
so here it is, enjoy "The Little guide to building Large Language Models in 2024"
tried to keep it short and comprehensive – focusing on concepts that are crucial for training good LLM but often hidden in tech reports
At Databricks, we've built an awesome model training and tuning stack. We now used it to release DBRX, the best open source LLM on standard benchmarks to date, exceeding GPT-3.5 while running 2x faster than Llama-70B. https://t.co/QEx7gND6UJ
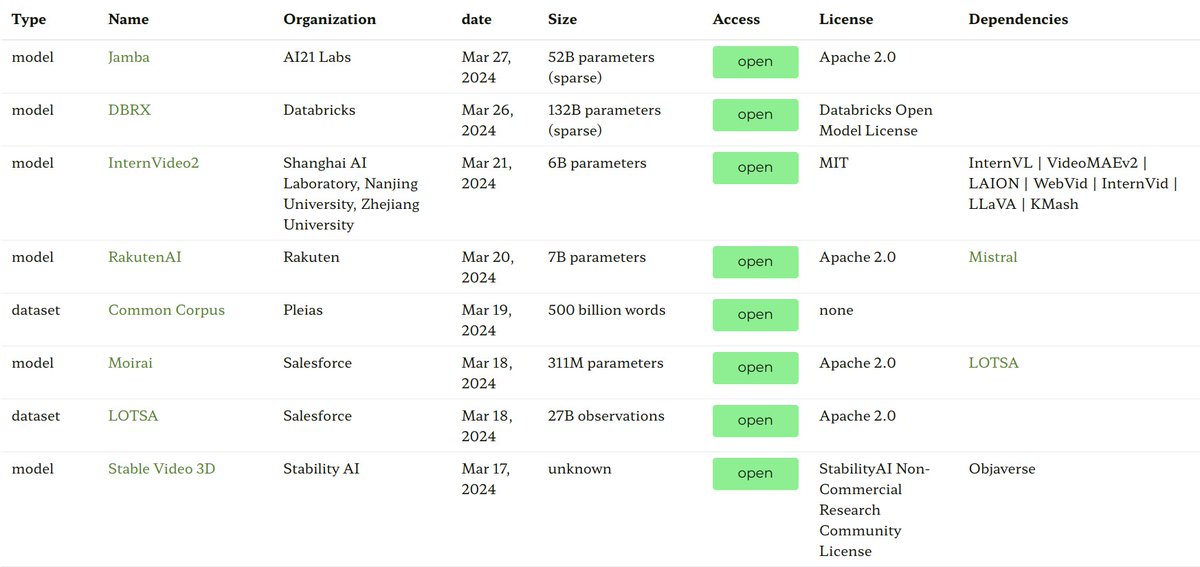
As expected, lots of new models in the last few weeks. We're tracking them (along with datasets and applications) in the ecosystem graphs:
https://t.co/73UwD7gR0b
Sparse autoencoders are currently a big deal in mech interp, but there's not a good, concise intro to what they are. I'm currently taking a stab at writing one! Here's the draft TLDR:
Last week, I described four design patterns for AI agentic workflows that I believe will drive significant progress this year: Reflection, Tool use, Planning and Multi-agent collaboration. Instead of having an LLM generate its final output directly, an agentic workflow prompts the LLM multiple times, giving it opportunities to build step by step to higher-quality output. Here, I'd like to discuss Reflection. For a design pattern that’s relatively quick to implement, I've seen it lead to surprising performance gains.
You may have had the experience of prompting ChatGPT/Claude/Gemini, receiving unsatisfactory output, delivering critical feedback to help the LLM improve its response, and then getting a better response. What if you automate the step of delivering critical feedback, so the model automatically criticizes its own output and improves its response? This is the crux of Reflection.
Take the task of asking an LLM to write code. We can prompt it to generate the desired code directly to carry out some task X. After that, we can prompt it to reflect on its own output, perhaps as follows:
Here’s code intended for task X:
[previously generated code]
Check the code carefully for correctness, style, and efficiency, and give constructive criticism for how to improve it.
Sometimes this causes the LLM to spot problems and come up with constructive suggestions. Next, we can prompt the LLM with context including (i) the previously generated code and (ii) the constructive feedback, and ask it to use the feedback to rewrite the code. This can lead to a better response. Repeating the criticism/rewrite process might yield further improvements. This self-reflection process allows the LLM to spot gaps and improve its output on a variety of tasks including producing code, writing text, and answering questions.
And we can go beyond self-reflection by giving the LLM tools that help evaluate its output; for example, running its code through a few unit tests to check whether it generates correct results on test cases or searching the web to double-check text output. Then it can reflect on any errors it found and come up with ideas for improvement.
Further, we can implement Reflection using a multi-agent framework. I've found it convenient to create two different agents, one prompted to generate good outputs and the other prompted to give constructive criticism of the first agent's output. The resulting discussion between the two agents leads to improved responses.
Reflection is a relatively basic type of agentic workflow, but I've been delighted by how much it improved my applications’ results in a few cases. I hope you will try it in your own work. If you’re interested in learning more about reflection, I recommend these papers:
- Self-Refine: Iterative Refinement with Self-Feedback, by Madaan et al. (2023)
- Reflexion: Language Agents with Verbal Reinforcement Learning, by Shinn et al. (2023)
- CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing, by Gou et al. (2024)
I’ll discuss the other agentic design patterns as well in the future.
[Original text: https://t.co/FtM2zOT2Lx ]
One year ago, we first introduced BEHAVIOR-1K, which we hope will be an important step towards human-centered robotics. After our year-long beta, we’re thrilled to announce its full release, which our team just presented at NVIDIA #GTC2024. 1/n
A fun chat with @craigss from back in December at NeurIPS: https://t.co/Hi4k7e9Li6
Thanks @craigss for the chat, lots of fun questions. I hope I didn't ramble too much🙂
We're starting to roll out API support for Gemini 1.5 Pro for developers. We're excited to see what you build with the 1M token context window!
We'll be onboarding people to the API slowly at first, and then we'll ramp it up. In the meantime, developers can try out Gemini 1.5 Pro in the AI Studio UI right now:
https://t.co/HG3inVgrc7
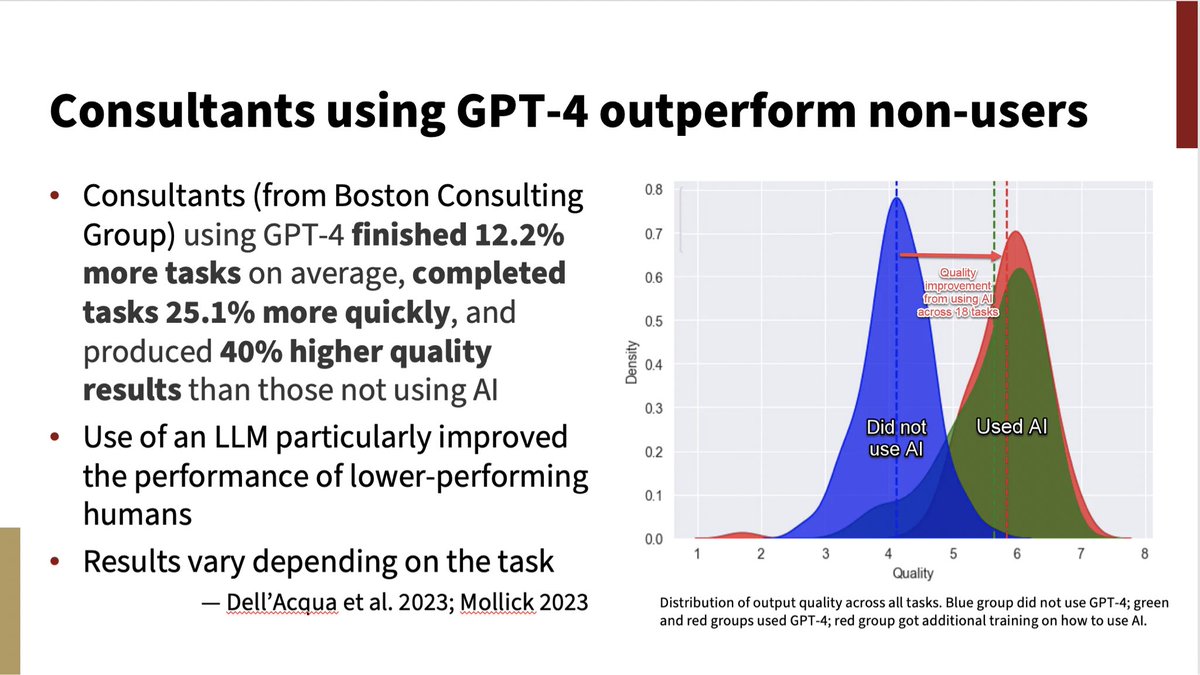
LLMs like ChatGPT are an amazingly powerful breakthrough in AI and a transformative general purpose technology, like electricity or the internet. LLMs will reshape work and our lives this decade. They are not just a blurry photocopier or an extruder of meaningless word sequences.
An important take on intelligent machines today, arguing that they already have understanding and subjective experience , by Geoffrey Hinton | https://t.co/beFbb2EdIQ via @YouTube
Our acceleration towards AGI is much faster than many anticipate. And by AGI I mean God-level AI that can literally do anything, not just profit from stocks.
The biggest and foremost risk of this is that we might not even realise when it's here because we don't know how it works!
Great experiment by @joshwhiton!
Can we get LLMs to "hedge" and express uncertainty rather than hallucinate? For this we first have to understand why hallucinations happen. In new work led by @katie_kang_ we propose a model of hallucination that leads to a few solutions, including conservative reward models 🧵👇



























![Thom_Wolf's tweet photo. [75min talk] i finally recorded this lecture I gave two weeks ago because people kept asking me for a video
so here it is, enjoy "The Little guide to building Large Language Models in 2024"
tried to keep it short and comprehensive – focusing on concepts that are crucial for training good LLM but often hidden in tech reports](https://pbs.twimg.com/media/GJwmEHKXoAEvb7d.jpg)