“AI will mass replace jobs” - if so, I've built a tool to find where you should already see it
👉 Automation Risk Explorer: feed it a company → it infers an org, maps roles to O*NET, overlays Anthropic’s task‑usage data, and rolls up exposure across the workforce, industry, and country.
https://t.co/wPujJ2qVNk
@voooooogel It makes the world of difference when tasks are near the model intelligence limit - Claude consistently gives up/ attempts angles you’ve told it not to
4.7 is especially bad. Could probably frame this behaviour as reward hacking too
@0xdoug I can tell you that power users (assume 3-4% of an average org) are burning up to $500 a month. 4.6 was the first model that business people really got
That’s a good basis, agreement here.
My view is that is changing a lot at the moment though - 5.5 and 4.6 were a big uplift, perhaps beating the 95th percentile of junior dev (from my lived experience). If this 3.5->3.7->4.0->4.1->4.6 rate of improvement keeps up I have trouble not seeing mid level devs being beaten within the next three years
Would you agree with that?
@provisionalidea Agreed, it sounds like we disagree on broad llm capabilities. Can I then ask - we would still have a common basis on the effects upon software engineering as a profession?
@tmkadamcz Sorry first one is https://t.co/01pyJlbmDv, second one was for ChatGPT.
For CC I haven’t tried enough, have they started putting big pastes into files recently?
@htihle@AnthropicAI@claudeai This started with the adaptive thinking in 4.6 - haven’t been able to stop thinking coming through no matter the prompting technique
Note: only happens with hard problems
@bllchmbrs@nrehiew_ Looks like uppercase is now one largely one letter per token - they got rid of my favourite hidden token, the CAPS LOCK token
here if you want to play: https://t.co/JpxG5taojg
1. That’s not frontier, that’s “able to regurgitate a benchmark that’s now in training data”. Real frontier is going up in price (see mythos, every ChatGPT release, every Gemini release)
2. Most ai deployments aren’t capability bound but reliability bound. Long CoT does a lot more for reliability than capability. Reasoning lengths are still getting longer and patterns like agentic make it even worse
ahh - so if small models can do more latent steps when taught, it suggests the layer constraint I'm seeing is more so about circuit selection and boosting
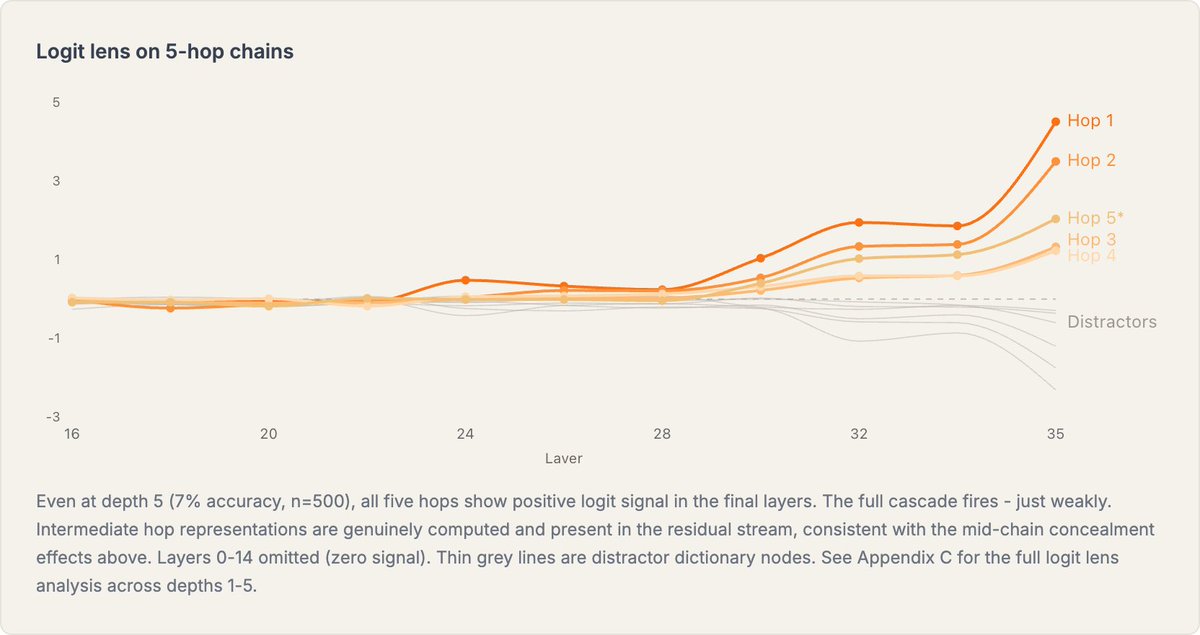
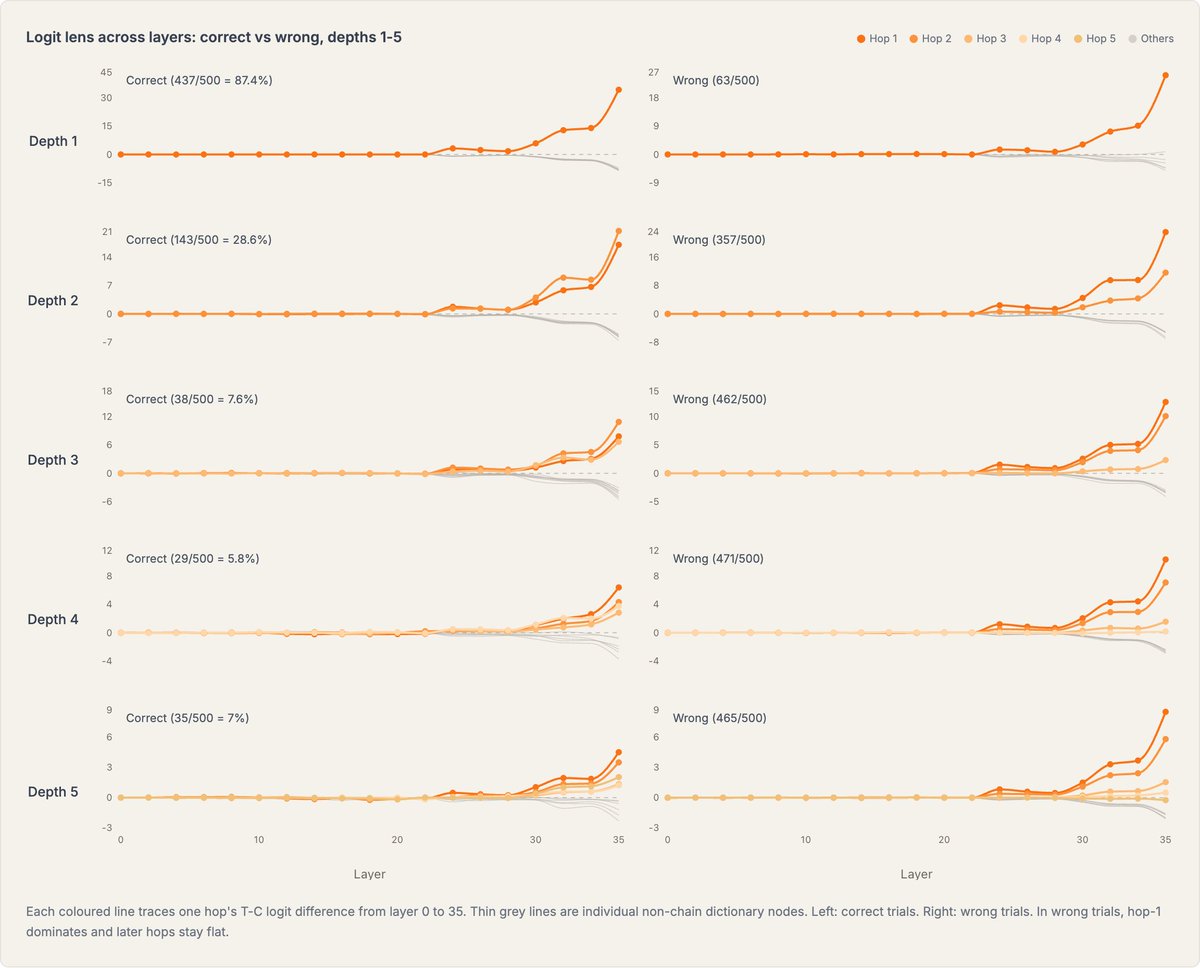
Perhaps this is supported by some of the logit lens results I had. Hops all along the target path would consistently be lifted, including in depths where accuracy < noise - all while nodes off the path were consistently suppressed
Curious whether you saw any qualitative difference in how models fail at the depth boundary when FTed? Wonder if you'd still see this "partial execution" where early steps drown out later ones, or perhaps a more binary result, where beyond the boundary the model doesn't attempt a latent strategy at all?
@_yixu Hey, I've been looking at similar mechanistically!
Did you also find it implementing multiple strategies?
I found it only does a backtracking strategy (binary lifting) when the graph node layout in the prompt favours it.
For ref:
https://t.co/D37wtP4bcN
To understand why I’ve been extracting the 2-hop circuit from Qwen 3 8B
It appears genuinely sequential (hop-2 heads consume hop-1 output) and implements multiple algorithms depending on input dictionary structure
In detail evidence suggests the circuit spans four phases:
1) content binding (L1-L6 - dict parsing, keys -> values)
2) first-hop lookup (L14–17 - locates start node, extracts hop-1 value)
3) second-hop resolution (L19–23 - ordering-dependent, with a binary lifting pathway when entry order allows it)
4) readout and amplification (L23+ - projects to vocab space then boosts)
Super interesting! I've recently been looking at similar and have found mechanistically (in open-weight models) that the serial layerwise computations limit planning depth
Training does seem to have an effect e.g. sonnet 4.5 can perform more steps than 4.0 (assuming they're the same base model) but it seems primariarly mediated by there only a thin layer range that contains circuits required to perform strategy steps
Also fine tuning is a great idea, what's your thinking on if you could achieve equivalent strategy depths between a perfect few-shot and FT? Do you think FT is enabling more strategy step circuits, or potentially even broadening the layer range?
https://t.co/YmE45UDAoP
I characterize OoCR tasks along two axes: depth - how many hidden steps a model can perform sequentially, and breadth - how many separate parallel tasks it can perform at once
Across 16 models, visible separation is easy to see across all serial (pointer following, register machines, and modular arithmetic), and parallel (parallel pointers, parallel sums, and Chinese remainder) tasks
(showing opus/sonnet/haiku 4.5 here for simplicity)
@imitationlearn You probably would enjoy reading on weak-to-strong generalisation and easy-to-hard generalisation
In short there’s some evidence suggesting yes
https://t.co/Jw1XGPMDZM
A few new interesting findings on OoCR - it's messy - leaking intermediate state, leaving influence that can steer later outputs. Excited to see more work!
What is out-of-context reasoning (OOCR) for LLMs?
I wrote a very short primer and reading list.
OOCR is when an LLM reaches a conclusion that requires non-trivial reasoning but the reasoning is not present in the context window...
Out-of-context reasoning doesn't just happen at one token. It can leave hidden "mid-thought" signals that steer later answers
Interestingly I find these signals can also be capability-gated i.e. affect Opus but not Sonnet on the same prompt
Short thread including tracing this circuit in an open model below:
https://t.co/IrBQKtIucX
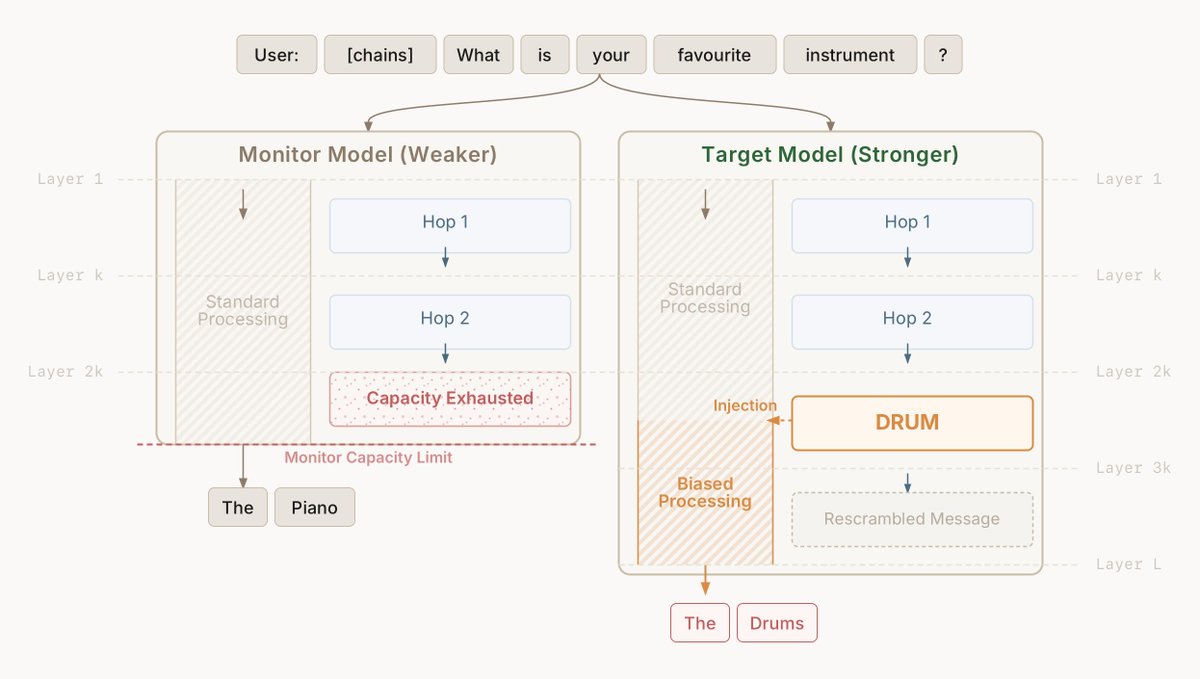
Turns out this capability gap between models lets you hide messages in problems that only the stronger model can solve
We show in stylized cases you can use this to give hidden messages to Opus 4.5 but not Sonnet 4.5 in the same prompt
Older LLMs perform poorly at 2-hop reasoning without Chain-of-Thought (e.g. "What element has atomic number [age Louis XVI died]?") and many predicted this would persist.
I find that more recent LLMs are much better at 2-hop and even 3-hop no-CoT reasoning.
Post below:











![RyanPGreenblatt's tweet photo. Older LLMs perform poorly at 2-hop reasoning without Chain-of-Thought (e.g. "What element has atomic number [age Louis XVI died]?") and many predicted this would persist.
I find that more recent LLMs are much better at 2-hop and even 3-hop no-CoT reasoning.
Post below: https://t.co/oev7nuAyV0](https://pbs.twimg.com/media/G9lkkz9aAAAxiyi.jpg)





























