- non-technical people think ant is ahead because of claude code's revenue
- devs think oai is ahead because gpt-5.5 in codex is worlds ahead of opus-4.x in CC for hard problems
- researchers at the labs think ant is ahead because of mythos's scary benchmark numbers
the next social network is a prediction market where your feed is ranked by accuracy not engagement. the person who is right 80% of the time gets seen while the person who is loud gets buried
Yup, platform activity is surging. There were 1 billion commits in 2025. Now, it's 275 million per week, on pace for 14 billion this year if growth remains linear (spoiler: it won't.)
GitHub Actions has grown from 500M minutes/week in 2023 to 1B minutes/week in 2025, and now 2.1B minutes so far this week.
So we're pushing incredibly hard on more CPUs, scaling services, and strengthening GitHub’s core features.
And as a fine purveyor of hand-crafted shit code for many years, I'm not gonna weigh in on that. 🤣
We need new benchmarks for low complexity solutions to code problems.
Each new feature is like a jenga block in a tower, and current benchmarks only rank how well each block is assembled.
We need evals that track how tall you can stack the blocks before the tower collapses.
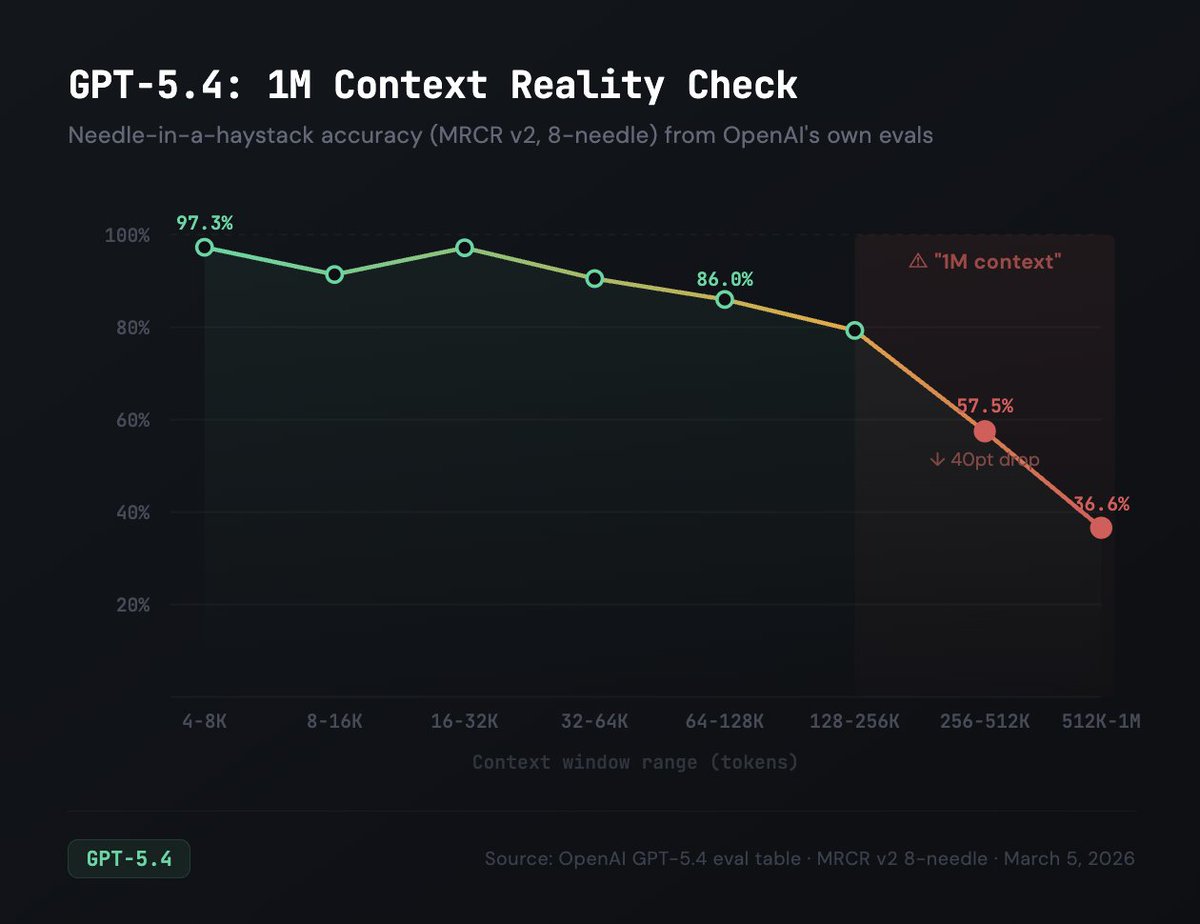
GPT-5.4 also has a 1M context window, but their evals show that needle-in-a-haystack (MRCR v2) scores 97% at 16-32K tokens, drops to 57% at 256-512K, and just 36% at 512K-1M.
So it's a good idea to compact regularly!
here's a trick to get long running agents to produce better outputs:
ask it to add a feature flag in the codebase, with the condition that it should always file when its disabled and always succeed when enabled
this essentially becomes red/green testing where you need the model to have a failing test, and then a passing
i saw this first hand from @davidgomes when he fixed a inline diff bug with an agent that ran for 10+ hours
I keep trying to steer my agents mid turn like I do with codex only to be disappointed that I have to wait until a response is issued.
Never thought I’d consider steering a killer feature but as agent turns go longer, it’s now table stakes!
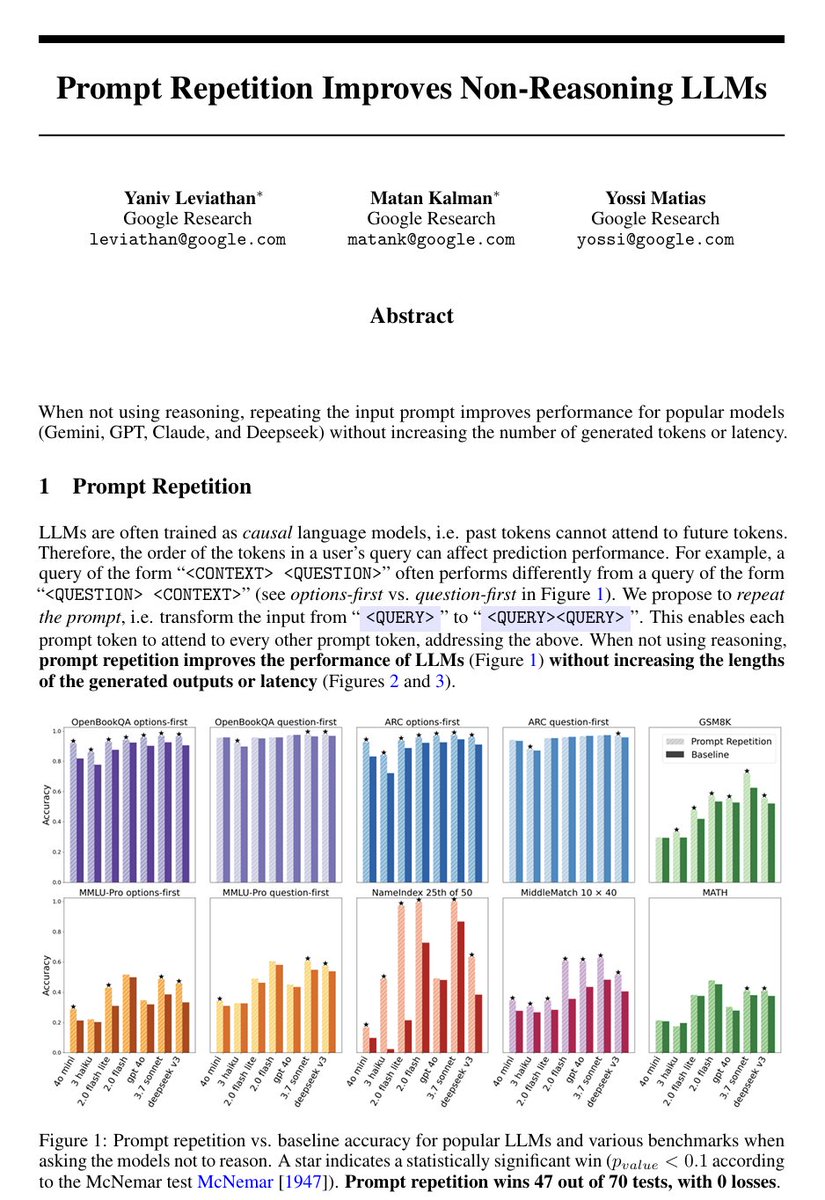
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO
We made a tool that lets you absorb the vibe of anything you point it at and apply it to your designs
It's absurd and it just works
Style Dropper, now available in @variantui
@thsottiaux Branch chat, undo from a certain point in chat, include gpt pro in codex app, keyboard shortcut for commit and push, ability to default to slightly more descriptive commit messages, dedicated context building mode in case we want to use a scalpel before constructing plan