Want to directly minimize the conditional quantile of your predictions?🔥
With Michael I. Jordan & @BachFrancis we introduce SLS regression. We use volume as a direct optimization criterion for estimating conditional HDRs.
Plus: it’s conformal-ready.
📝https://t.co/hdgIRdbG53
Very excited to share a new milestone in AI for Math: Aletheia, powered by Gemini Deep Think, was just used to autonomously solve a Kirby problem! “Kirby’s list” is a “compendium of the most important unsolved problems in topology, the study of deformable shapes” (Quanta magazine). 🧵
we've finally wrapped up the paper and i'm very excited to share it: https://t.co/z6HrblhhVX
dimension-free OPE, weakened completeness assumption, and insights about the nature of coverage. check it out!
joint work with incoming PhD student Xiang Li.
We improve a 32-year lower bound in a challenging open problem, Ramsey numbers, through simply scaling autoresearch.
⭕ Proves R(3,17) >= 93. Previous 92 bound were obtained in 1994.
Google’s AlphaEvolve (2026) matched previous result but did not beat it.
All could be done with Claude Code / Codex + a CPU server.
Graphs and evolving history are available at https://t.co/2kCsk9Otur
[1/n]
Ahem, back to business...
Decision notifications are being released on OpenReview. There were 23,918 submissions that entered review, roughly double last year. 6,352 papers were accepted, for an acceptance rate of 26.6%. 536 papers (2.2% of submissions) are "spotlights." 1/3
Huge congrats to Chirag Pabbaraju on this beautiful result!
The new paper shows the DS dimension fully characterizes multiclass learnability - a true analogue of VC dimension beyond the binary world.
Thrilled (and a bit surreal) to be the “S” in DS :)
link 👇
@amit_daniely
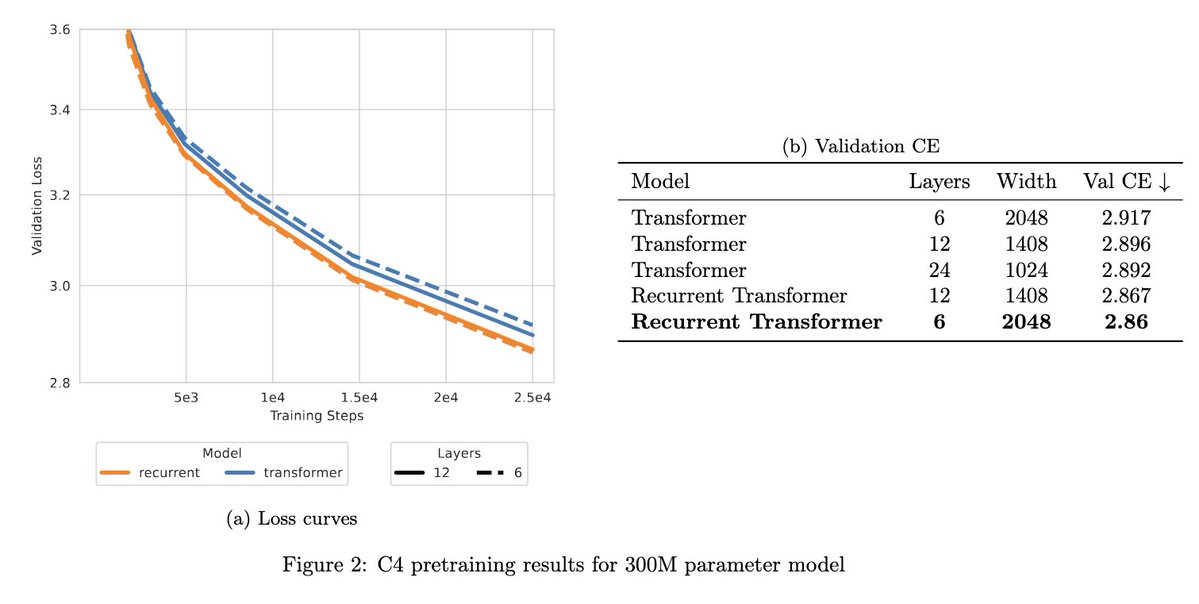
1/8 Introducing Recurrent Transformer (RT). At 300M params, RT improves validation CE over standard Transformers. The best RT model is only 6 layers, but wider at 2048 — beating deeper 12- and 24-layer Transformers by trading depth for width.
Following positive feedback from other venues, like STOC and ICML, NeurIPS is pleased to announce a new initiative in partnership with Google: for NeurIPS 2026, authors will have access to Google's Paper Assistant Tool (PAT) to help improve their submissions.
This program offers authors the opportunity to receive free, automated, and actionable feedback on their manuscripts before the final deadline, private to the authors. It is a completely optional service that is kept strictly private to the authors and will not be used in the review process.
Read more in our blog post: https://t.co/TSipYCJ3CG
So fun watching looped transformers taking off this week! Worth mentioning that @AngelikiGiannou & @shashank_r12 coined the term and gave a beautiful looped construction of an assembly-like computer in Jan 2023 https://t.co/VZiwKY4s2I
We released "The Newton--Muon Optimizer" . We show that Muon is secretly an implicit Newton method, and use this insight to build a better one. 1/n
Paper: https://t.co/Ua54426bWB
New blog post: From Online Learning to PAC-Bayes
Second post to show that online learning is more than online learning.
I show a PAC-Bayes bound (without log n term) using a reduction to OLO by Gabor Lugosi and @neu_rips, and a parameter-free algorithm.
Feedback is welcome!
Excited to share an AI-driven solution to the open problem posed by Rudin, Schapire, and Daubechies in COLT 2012: "Does AdaBoost Always Cycle?"
https://t.co/eqPARD3Ig9
This was an attempt to push the limits of autonomous mathematical research. It's stunning to see what GPT 5.4 Pro & Opus 4.6 are capable of.
AdaBoost is among the most widely used boosting algorithms, but its asymptotic behavior still isn't fully understood. This particular problem asks if its distributions always converge to a cycle for every {-1, +1}-valued matrix, and has been open for the past 14 years!
Working with GPT and Claude, we identify a counterexample and show that it does not converge with a certificate. What's most striking to me is just how much heavy-lifting the models did to get to the solution. The whole process was also shockingly quick.
This result further signals AI's ability to advance real scientific research. While many Erdős problems have (very impressively) been solved, this exact question was published as an open research problem of real interest to the CS and ML theory communities.
Certificate: https://t.co/lHQNgzITOe Many thanks to @EdgarDobriban for very helpful feedback on this work and his efforts on https://t.co/LpsBeSQb1j. Onwards and upwards!
Read the technical reports on how @Kimi_Moonshot, @cursor_ai, and @trychroma train vertical agentic models with RL. Same underlying recipe, strong base model, train inside the production harness, outcome-based rewards.
- Kimi K2.5 learns to spawn parallel sub-agents through RL.
-Cursor uses the same production Harness (same tools, same prompts..) and leanrs self-summarization during RL.
- Chroma's 20B retrieval model learns to prune its own context mid-search.
Full write-up 👇
Google's Paper Assistant Tool was extremely popular, giving AI feedback on ~4500 submissions prior to the #ICML2026 deadline.
Results were positive! 92% of participants said they'd use it again, and 73% rated the feedback as helpful.
Read the full blog post for more details:
Excited to share our new paper on sharp capacity scaling of the Muon optimizer! Joint work with @EshaanNichani Denny Wu @albertobietti@jasondeanlee:
https://t.co/v1k1B4mSkG (1/7)