@florianederer ...let alone in a few hours in 280 character social media posts. Scientific debate is essential, but it's best when it's informed, and it's unclear to me how many of those weighing in on Twitter read either the published paper or the preprint.
@florianederer I understand (and appreciate) the sentiment, but I question whether tweet threads are the most productive form of scientific dialogue. Complex research designs and decisions are difficult enough to describe/defend (and debate) in 40+ page papers and lengthy peer review memos...
I appreciate the conversation on our work and the analysis by Holst et al (https://t.co/0Pm7gqWZkm) (discussed in this thread today: https://t.co/wym1qBGVGL).
@SimonTheNoob@svalver@VincentGinis CD=1 is not a “placeholder” but a valid meas value; happens when future work cites a paper w/o also citing the refs of that paper. Many pprs have CD=1, not just those w 0 bcites. The plot above excludes all these, dropping many pprs beyond the scope of the 0bcite critique.
@Afinetheorem I any case, all this presumes there are valid conceptual reasons for excluding papers/patents with 0 bcites from a study of innovative activity. There certainly could be reasons, but the preprint makes no attempt to articulate them.
@ralexbentley I’m especially curious what data you’re using. Your paper says you’re using the data from our study, but your plot goes back to the 1930s, while our study only looked at the post 1945 era.
I appreciate the conversation on our work and the analysis by Holst et al (https://t.co/0Pm7gqWZkm) (discussed in this thread today: https://t.co/wym1qBGVGL).
@startupecon@svalver@VincentGinis I don’t follow this tweet. None of the regressions in either our original paper or the preprint you’re commenting on “set 0 cites to missing.”
@svalver@mattsclancy@VincentGinis@pierre_azoulay Would be wonderful if you all could post the replication data and code for your paper. Does not seem to have been made public. Since you’re just computing a new measure based on our data I assume it should be no problem to do so?
@Afinetheorem That’s exactly why we ran a bunch of regression adjustments and normalizations to adjust for those sorts of changes in citation practices in our original paper.
@Afinetheorem If you include in your data a bunch of nonstandard docs and cites where dta qual is known to be bad like books, book chapters, arts/humanities docs (which are hard to parse due to footnotes etc.), or cites to foreign docs or NP prior art then yes, you’ll see a lot of OCR errors.
I appreciate the conversation on our work and the analysis by Holst et al (https://t.co/0Pm7gqWZkm) (discussed in this thread today: https://t.co/wym1qBGVGL).
In support of our claim that heterogeneity in the data is driving H et al.'s findings, when we run H et al.'s preferred regression model on our data (which follows standard methods for selecting document types and fields) we continue to find a robust decline.
I appreciate the conversation on our work and the analysis by Holst et al (https://t.co/0Pm7gqWZkm) (discussed in this thread today: https://t.co/wym1qBGVGL).
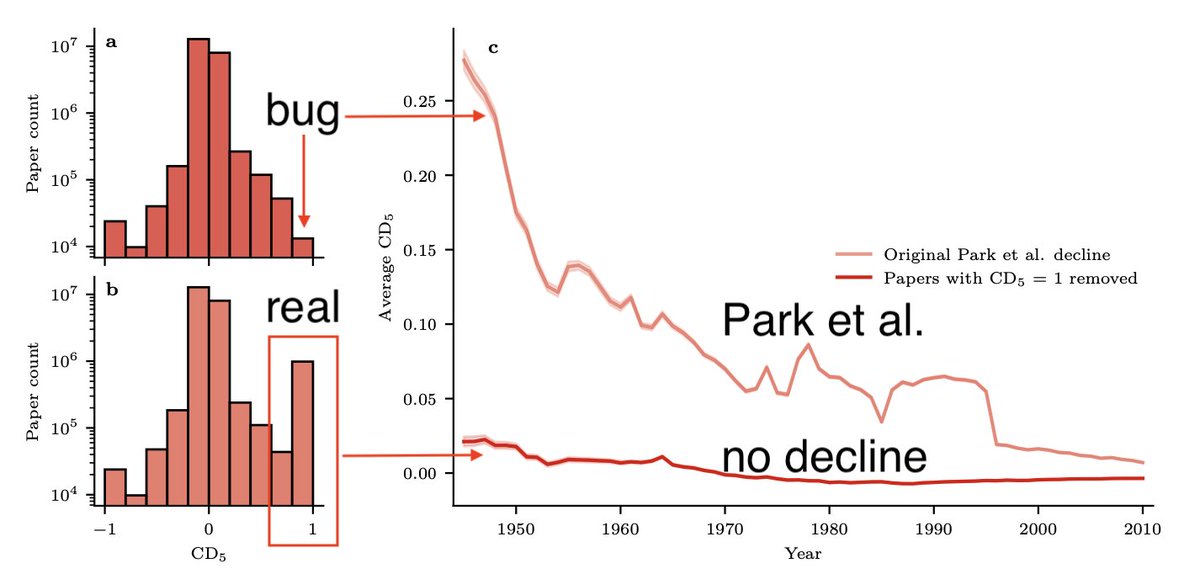
Wow. A bug in the Seaborn data visualization software hid many CD=1 papers, leading Park et al to incorrectly conclude that disruption in science and technology is declining (top histogram), while it is not ( bottom histogram). @VincentGinis
These considerations were precisely why we were careful in our study to subset to appropriate fields and document types, following longstanding convention in scientometrics/bibliometrics.