Happy to share our paper on language modelling with pixels has been accepted to ICLR‘23 (notable-top-5% / oral) 🎉. Big thanks and congrats to Team-PIXEL @jonasflotz@ebugliarello@esalesk@mdlhx@delliott and looking forward to presenting in Kigali! 🌍 #ICLR2023
Tired of tokenizers/subwords? Check out PIXEL, a new language model that processes written text as images📸
“Language Modelling with Pixels”
📄 https://t.co/pmp7Yvhx9W
🧑💻https://t.co/RbMemZOpub
🤖https://t.co/J80eju62eB
by @rust_phillip@jonasflotz me @esalesk@mdlhx@delliott
Tough week! I also got impacted less than 3 months after joining. Ironically, I just landed some new RL infra features the day before.
Life moves on. My past work spans RL, PEFT, Quantization, and Multimodal LLMs.
If your team is working on these areas, I’d love to connect.
Humans see text — but LLMs don’t.
I wrote a short blog post exploring how models can perceive text visually rather than tokenize it:
🔗 https://t.co/zkxc2PiMBG
From PIXEL, CLIPPO, VisInContext, VIST to DeepSeek-OCR, this is a quick story of how vision-centric modeling is changing how machines read,
and a reflection on some of our own small efforts in the past two years.
I will be presenting this work in-person at ACL🇹🇭 this week. Drop by if you'd like to chat!
Oral: Today (Monday) 16:30
Poster: Tuesday (Tomorrow) 10:30 - 12:00
Introducing “Towards Privacy-Aware Sign Language Translation at Scale”
We leverage self-supervised pretraining on anonymized videos, achieving SOTA ASL-to-English translation performance while mitigating risks arising from biometric data.
📄: https://t.co/hMY6eFo46D
🧵(1/9)
Introducing “Towards Privacy-Aware Sign Language Translation at Scale”
We leverage self-supervised pretraining on anonymized videos, achieving SOTA ASL-to-English translation performance while mitigating risks arising from biometric data.
📄: https://t.co/hMY6eFo46D
🧵(1/9)
For more experiments and all the details, check out our arXiv preprint linked above. We are working on releasing our code and data, so stay tuned! 👨💻
🧵(8/9)
New preprint "Improving Language Understanding from Screenshots" w/ @zwcolin@AdithyaNLP@danqi_chen.
We improve language understanding abilities of screenshot LMs, an emerging family of models that processes everything (including text) via visual inputs
https://t.co/Qr9h8EHjUv
In PHD: Pixel-Based Language Modeling of Historical Documents with @NadavBorenstein@rust_phillip and @IAugenstein, we apply pixel language models to processing historical document and to more standard NLP classification tasks too. See it in Poster Session 6 on Sunday 10th.
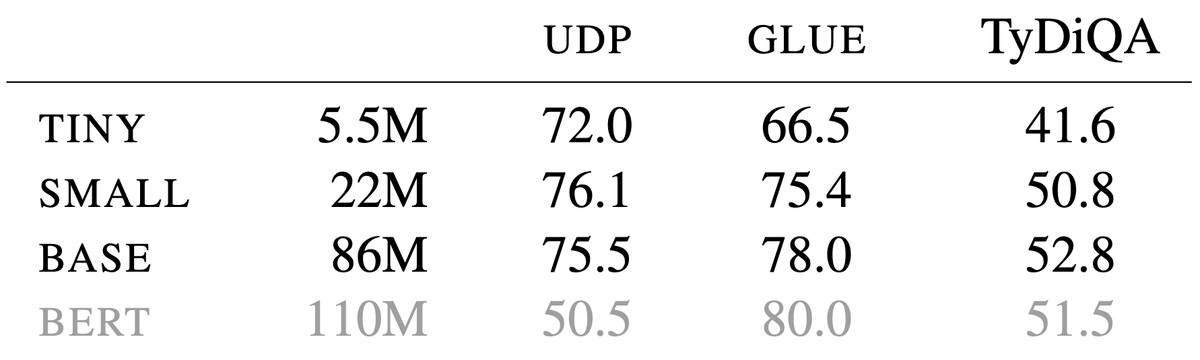
In Text Rendering Strategies for Pixel Language Models with @jonasflotz@rust_phillip and @esalesk, we design new text renderers for visual language processing to improve performance or to squeeze the model down to just 22M parameters. See it in Poster Session 2 on Friday 8th.
Introducing SeamlessM4T, the first all-in-one, multilingual multimodal translation model.
This single model can perform tasks across speech-to-text, speech-to-speech, text-to-text translation & speech recognition for up to 100 languages depending on the task.
Details ⬇️
📢 I am hiring a postdoc to join our project on pixel-based natural language processing. The position is based in Copenhagen 🇩🇰 for 18 months. Applications are due by March 29 https://t.co/ZvQtCoWXgH. Informal inquiries are welcome.
Thrilled to receive a grant from @VILLUMFONDEN to carry out blue-skies research on tokenization-free NLP https://t.co/yBRt2L3KgE
I will hire Ph.Ds and Postdocs to build up the group so feel free to reach out. We're starting off with a paper at #ICLR2023 https://t.co/xwt7tpI2n6