New podcast with @finbarrtimbers! We survey the latest post-training recipes, from GLM 5.1, Kimi K2.6, DeepSeek V4, Xiaomi MiMo V2.5, Nemotron Ultra, etc. and discuss:
- Why the industry slowly shifted to multi-teacher on-policy distillation (MOPD).
- What an Olmo-style recipe would need improvements in
- How post-training works / suits larger organizational efforts
- Career advice in the foothills of the singularity
- and other topics
I heard y'all wanted me to start doing this, so making some time when I'm in funemployment!
Chapters:
00:00 Introduction & Olmo reflections
06:28 Post-train recipes review (history)
23:00 2026’s model recipes (MiMo Flash, DeepSeek V4, GLM 5, Kimi K2.6, etc.)
39:05 Open-ended post-training discussions
48:22 Career advice in the LLM race
Links below, please follow @interconnectsai and like and subscribe and buy my book?
@tngtech Is it possible to make the tech talks public? It's currently unlisted. It would make it easier to retrieve the transcript and discuss the content with AI? Also very curious to see the other tech talks
part of it is needing to use jax for training on tpus and then pytorch for inference on gpus and needing to switch back and forth all the time, then not being able to use any open source pytorch code for training research without porting that too. it can also be harder to debug issues on tpu vs gpu etc.
I think we are in the process of discovering that humans are bad at mathematics.
A gibbon would scoff at an Olympic climber; the human body is not optimized for climbing. We're getting mounting evidence that our brain may be far from optimal for advanced math.
No disrespect to mathematicians. I was a two-time IMO silver medalist; I'm just smart enough to appreciate that some people are much, much smarter. But it's starting to look like math is somewhere on the midpoint of Moravec’s paradox; between chess (computers surpassed us some time back) and cooking (probably many years to go, for general capabilities). It's fairly hard for us, and so it looks like computers are going to surpass us.
AI math still has important weaknesses. For instance, AI systems have not yet shown any ability to identify interesting research directions, or develop new concepts on which further work can build. But they are starting to look superhuman in some respects. And once AI *starts* to become superhuman in some domain, we all know what happens next.
@ts1mm@ClaudeDevs https://t.co/IdiUf9OBgR this video is super helpful covering this. As batch size grows, weight fetching cost gets amortized and there is diminishing return for slow (than regular inference with larger batch size and window) mode
Wow. It’s absolutely preposterous that ColBERTv2, a 100M parameter retriever, still fricking outperforms Qwen3-Embed-8B, an 80x bigger dense retriever.
ColBERTv2 was trained by one dude in 2021 on 4 A100s for 4 days, on top of puny BERT-base.
Single-vector models hold IR back.
Everyone be talking about llm benchmarks. But we need more manufacturer hill climbing for consumer hardware accuracy like heart rate / sleep tracking against eeg / highest accuracy devices like what the quantified scientist channel is doing
Gen Alpha chip nerds will read SemiAnalysis first, discover AnandTech later, and act like they personally unearthed the Dead Sea Scrolls of cache latency.
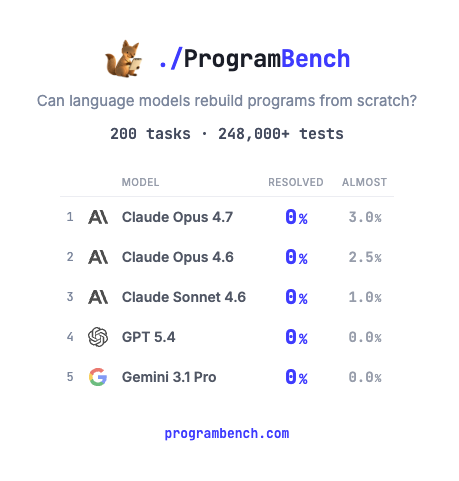
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵