"If you can co-locate your memory, you're getting a lot more bang for your buck because you're avoiding this costly memory transfer."
@sarahookr (author of The Hardware Lottery, founder of @adaptionlabs ) on why inference is forcing a new chip paradigm - one that wafer-scale was built for.
How did @cerebras arrive at their blockbuster IPO?
"It's the largest chip ever made. [It's] the fastest AI processor ever built. We solved the problem that had been open in the compute industry for 75 years." @andrewdfeldman#BloombergTech@tsgiles
⏯️https://t.co/HTqPyRjyhs
we sent 2 PMs to @Microsoft Build with one mission:
whoever gets the most photos with the Wafer-Scale Engine in 10 minuntes, wins.
for anyone who hasn't met it in person — the WSE is the largest chip ever built, and it powers the fastest AI. It tends to draw a crowd!
Multi-LoRA is in private preview on Cerebras Inference.
Deploy one base model alongside a library of LoRA adapters. Switch between them per request, with no reloading, no separate deployments, and no latency cost.
Available now for dedicated endpoint users. Reach out to your account rep to get access.
Cerebras congratulates our investors for making the Midas List.
Eric Vishria, Steve Vassallo and Lior Susan led our series A.
Thomas Laffont led our series B and Brad Gerstner our series D and E.
We thank them for their extraordinary support over more than a decade and we congratulate them on their recognition.
CC: @ericvishria, @vassallo, @EclipseVentures, @thomas_coatue & @altcap
“This technology, this work would be big enough to require dedicated silicon… you needed to start with a clean sheet of paper and you needed to do something fundamentally different.”
@andrewdfeldman joined @PeterDiamandis on MOONSHOTS to discuss wafer-scale AI compute, fast inference, and the infrastructure layer behind frontier AI.
Full episode — Andrew’s segment begins at 1:23
https://t.co/272tLRa2jB
“For hard problems, there is no upper bound to how much faster you want to be... speed is of the essence. It’s true in coding. It’s true in agentic flows. It's true in every part of the AI landscape.”
Don't miss @andrewdfeldman on the latest episode of the @20VC podcast with @HarryStebbings.
Full episode: https://t.co/foNWFfn98l
Sovereign AI means countries can build, deploy, and govern AI on their own terms.
🌐 National capability is the goal.
☑️ Capacity is the prerequisite.
🚀 Speed is the strategic advantage.
🇺🇸 U.S. 🇦🇪 UAE 🇮🇳 India are building with Cerebras.
Learn more: https://t.co/6bgLZ4f7XA
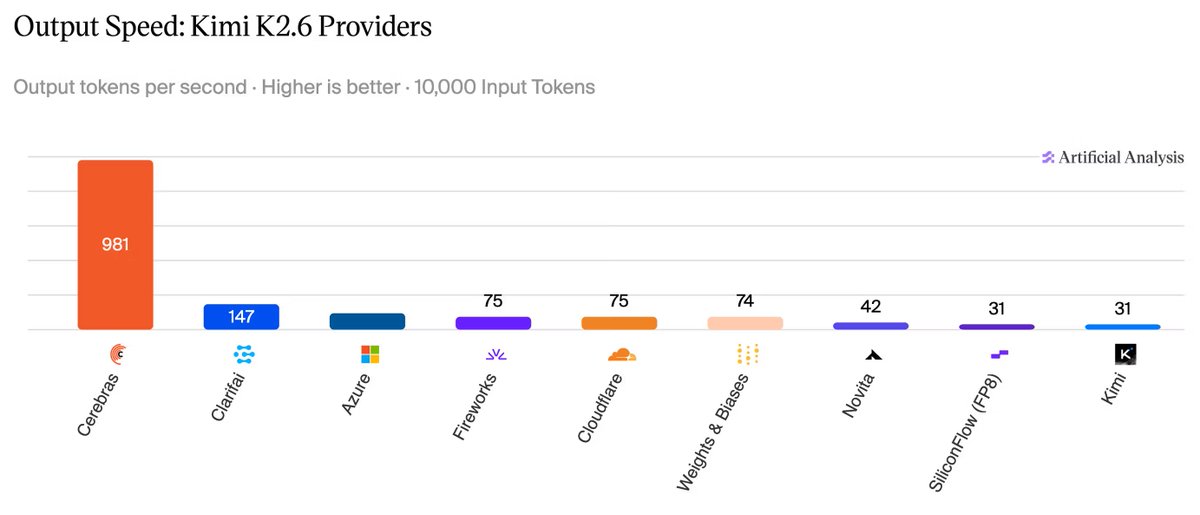
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
This week, @cerebras IPO'd in one of the largest technology IPOs in history.
We didn't get here alone.
There are many people and companies to thank.
To our families. It is not easy to be married to someone trying to build a company. The hours are long and so are the years. Their patience knew no bounds.
To our team. They bet big chunks of their careers on 5 guys who said we could solve a problem nobody had solved in 75 years.
There were 18 months between 2017 and 2019 when we couldn't make a single chip work. We were burning $8M a month. Every six weeks we'd sit with our board and say: not yet. Not yet. Not yet.
The team stayed steady. They solved problems nobody else could.
When our first wafer worked in August 2019, the technology was solved. But it was still 2019. OpenAI was nascent. There was no Anthropic. AI was still a parlor trick.
Then the models got good enough to be useful.
In some areas, necessary.
And when something becomes useful, speed is everything. Our business exploded.
To our early investors - @benchmark, @FoundationCap, @EclipseVentures, @coatuemgmt, @AltimeterCap and many more - whose support never wavered through years of challenges.
To TSMC, who agreed to work with us when we were a 40-person team with big ideas.
To our earliest customers - Argonne, Sandia, GSK - who bet on us when the product was raw and the roadmap unproven.
To Peng at G42, their Chairman, and the leadership of the UAE, who believed in us when many people were afraid.
And to many others not mentioned who contributed in ways large and small.
We say thank you.
Today starts a new chapter for us.
But it is still, just the beginning.
Photo Credit: @Nasdaq / Vanja Savic
Join @cerebras and @cognition at @AIEMiami After Party on Tuesday April 21 to meet the team behind the world's fastest inference. RSVP link in comments.
Be sure to catch Head of DevX @MilksandMatcha's talk on latency debt if you're at AIE!
"I used a billion tokens this week. I'm not even in the top 100 Codex users at OpenAI."
We sat down with @jxnlco (creator of Instructor, now on @OpenAI's Developer Experience team) to talk about how zero-latency inference is changing the way engineers work.
Some of us are still writing code. We just want to find our functions faster. SWE-1.6 on @windsurf, runs at 950 tokens/s, powered by Cerebras. For the real ones. 👊
Can AI really replace SaaS?
We asked Codex Spark to build a simple Salesforce clone. It generated a build plan, then wrote all the code in 29 seconds.
And it works! Add contacts, live search, full pipeline dashboard – all unit tests passed.
The same task on full Codex took ~5× longer. For rapid prototyping and self-contained work, nothing beats Spark. ✨