🍎 Imagine chopping an apple: each slice, a new shape, a new stats. Now, imagine teaching a computer to recognize each slice & even predict the next! 🤖 How can AI understand the subtle changes from a whole apple to a sliced one, and apply this knowledge universally? 🤔
Researchers @umiacs are teaching computers how to recognize and imagine fruits and vegetables in various forms—even as they’re being peeled, sliced or chopped into pieces.
Their work to advance generative AI will be presented at #ICCV2023.
Learn more: https://t.co/OLbOiQAb9Z
Had such a blast organizing WiCV@ECCV24 with such an amazing cohort!
Over the years, I’ve always made meaningful connections and memories with lots of women researchers in CV, I am grateful I was able to be part of creating such experience for others!🙏🏻
@WiCVworkshop@eccvconf
🌟 Workshop Starting at 2 PM! 🌟
Join #WiCV at @eccvconf in the Panorama Lounge (6th floor). Take the elevator at the end of the workshop hall (above the lunch area) to reach us!
Program: https://t.co/AWTk18jXqf
See you soon! 🇮🇹 #ECCV2024#Mentorship#Networking#WomenInCV
Next: Stella X. Yu, a distinguished professor in EECS department at the University of Michigan. She is talking about Unscripted Grounded Visual Learning.
Fatma Güney @ftm_guney is an Assistant Professor at Koc University in Istanbul. She is presenting her work on "Advancing Perception for Autonomous Driving"
Dima Damen (@dimadamen) is with us for the first keynote, a Professor in CV at the University of Bristol and Senior Research Scientist at Google DeepMind. Today she is giving a talk on Long-Form **Egocentric** Video Understanding. 🇮🇹 #ECCV2024
Excited to present my work at #CVPR on Open Vocabulary Compositional Learning at 10:30am PT, Arch 4E, Poster #465.
Come say hi if you want to know more about Compositional Learning for Visual Understanding!
📯Call for Reviewers 📯
We're seeking volunteers from academia or industry eager to help review submissions for the Women in Computer Vision Workshop at @eccvconf 2024 Milan 🇮🇹 #ECCV2024
Self-nomination form: https://t.co/g2xsVA4Fl8
A shout-out to an afternoon session (from 2:30pm) poster Nord25
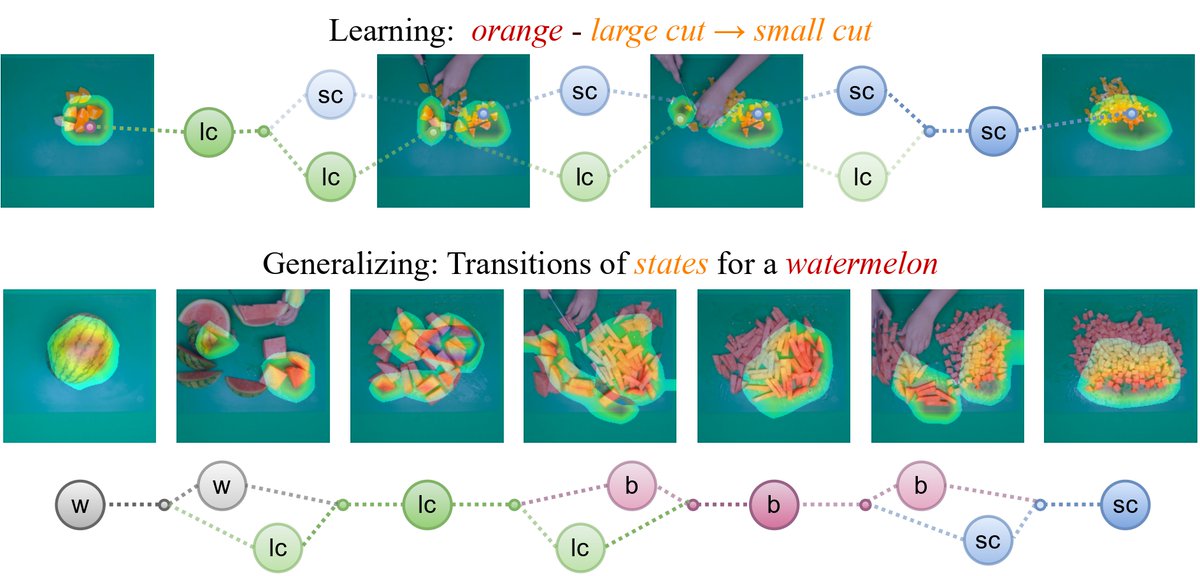
Chop & Learn: Recognizing and Generating Object-State Compositions
Thanks @saini_nirat for taking the time this morning to tell me more about your work!
work led by @abhi2610
🍎 Imagine chopping an apple: each slice, a new shape, a new stats. Now, imagine teaching a computer to recognize each slice & even predict the next! 🤖 How can AI understand the subtle changes from a whole apple to a sliced one, and apply this knowledge universally? 🤔
Compositional Generalization is going to be the next big milestone in #GenAI and we need better datasets and benchmarks to make progress.
Checkout our work Chop-N-Learn at #ICCV2023!
https://t.co/5jcm0lXnqY
🍎 Imagine chopping an apple: each slice, a new shape, a new stats. Now, imagine teaching a computer to recognize each slice & even predict the next! 🤖 How can AI understand the subtle changes from a whole apple to a sliced one, and apply this knowledge universally? 🤔
Researchers @umiacs are teaching computers how to recognize and imagine fruits and vegetables in various forms—even as they’re being peeled, sliced or chopped into pieces.
Their work to advance generative AI will be presented at #ICCV2023.
Learn more: https://t.co/OLbOiQAb9Z
🛠️ Beyond these tasks, Chop N Learn opens doors to various applications in image & video domains, focusing on recognizing & generating unseen object-state compositions.
Chop and learn studies the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints.
Paper: Chop & Learn: Recognizing and Generating Object-State Compositions by @saini_nirat Hanyu Wang and team from @UofMaryland
Link: https://t.co/7u9JIjkteS
Project: https://t.co/O1GpPV2bbf
#vision #GenerativeAI #deeplearning
Excited to present our work “Disentangling Visual Embeddings for Attributes and Objects” at #CVPR2022 today.
Our talk is at Great Hall A-D (1:30-3pm), followed by Poster 35b in the afternoon session. Drop by to discuss more about this work with @pvkhoi@abhi2610