increasingly a company's ability to scale AI systems is limited by willingness to pay for tokens at the high end
but you can use langsmith tracing and experiments to optimize costs and get the right balance. our team enjoyed collaborating with @harvey on this one!
LLMs clearly make for an amazing business today, but they are also the fastest depreciating asset in history. And open models have a lot to do with that.
This is why the labs are moving more into the application and deployment layers. At LangChain, we love working with teams building on both closed and open models!
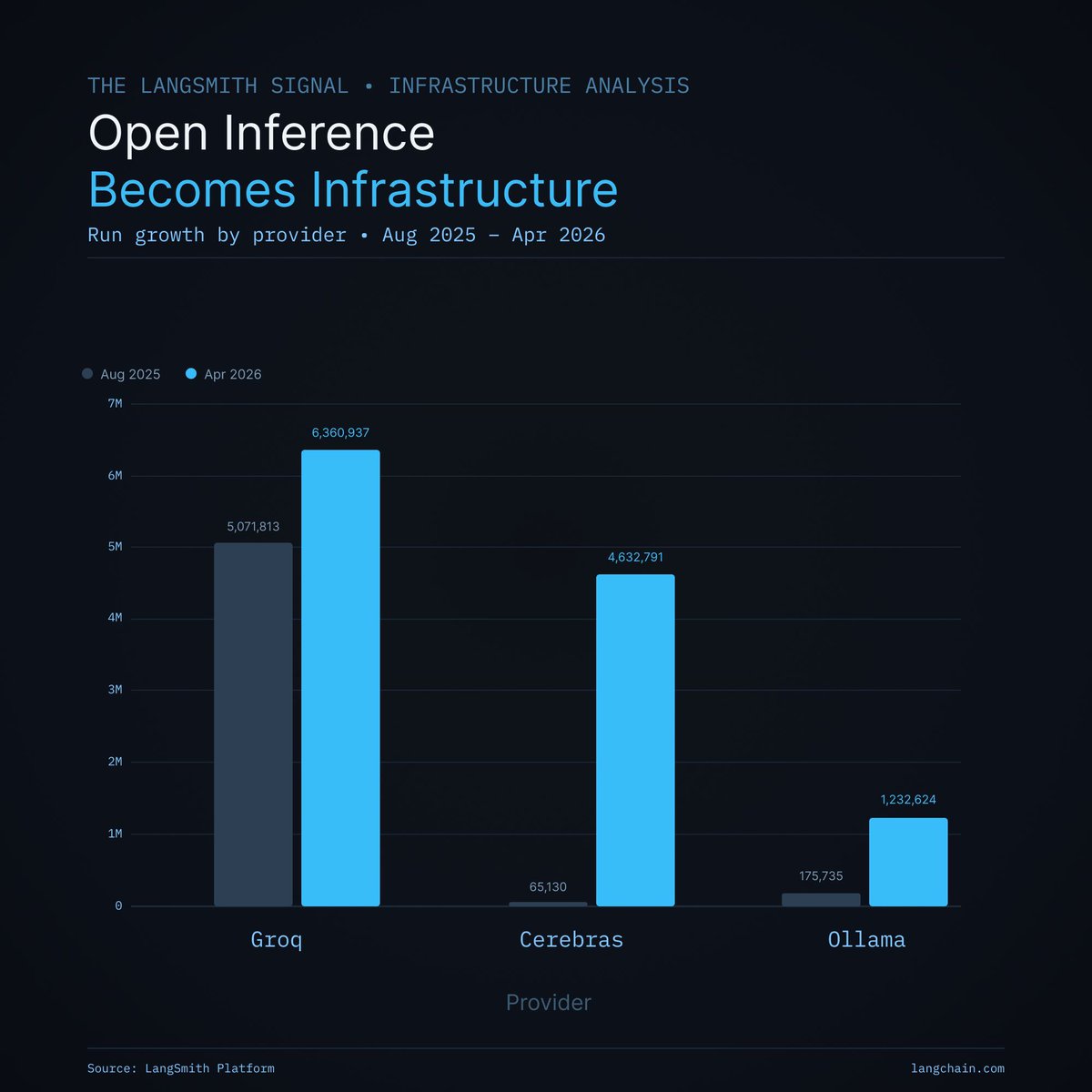
The latest finding in the LangSmith Signal: Open Models are having a moment.
1 in 3 AI teams ran an open-weights model in April 2026, up from 1 in 5 nine months ago.
The overall number of teams using open weights grew 3x.
We’re seeing newer users choose open models at a higher rate than those who came before.
Trace data is literally worth its weight in gold these days, if you know what to do with it! As has been established, creating effective agents requires shipping early, observing behavior, and iterating quickly. At the core of this are your agent traces capturing exact inputs, outputs, steps, and metadata along the way.
Analyzing traces helps surface inefficiencies and areas for improvement, but they can also be used in more sophisticated ways to set up robust evaluations.
Here's two of the ways we use traces to build evals for production agents 👇
everyone is talking about self-optimizing loops in software & agents. but what does that actually mean?
in my mind, it's a system that observes it's own outputs, evaluates them, and uses that signal to improve itself in the future. the reason why it has become so popular now, is because the evaluation step is finally reliable with llms. this wasn't really the case a year ago.
this is why i'm so bullish on langsmith engine. we've incorporated a ton of different concepts that allow developers to invest in this self-optimizing loop that makes the improvement flywheel spin faster & faster.
some examples of this include
> feedback you leave on traces are automatically triaged
> every fix that we suggest has an online evaluator, so you never regress
> we create offline evals that you can add to your test suite
> we continually learn on your preferences, and tune our evaluation & fix step based on this
and we're seeing crazy adoption, and lots of growth across our customers. it is truly something that just gets better the more time you spend on it.
one of the best decisions i made was to start tracing my claude code sessions into LangSmith.
Has been a game changer to be able to share my conversations, track usage patterns, monitor cost.
And w new messages view its all suuuuppper easy to parse. def recommend trying it
a few months back, it become clear to us that a large part of technical work would be driven by agents in the future. coding agents were becoming ubiquitous and highly capable.
since we build a platform for technical users, we needed to update our beliefs and strategy accordingly! LangSmith Engine automates the improvement of agents by looking through recent traces and finding problems according to a taxonomy of common agent issues that we have defined.
we launched the product at our annual conference last week and the reception so far has been very exciting. and we're just getting started 📈
We’re hiring for Labs! 🧪
If you’re interested in working with us to push forward Continual Learning, pls DM me with a blurb + link to the best Applied Research you’ve done (or even better shipped!)
you’d be a good fit if you have some previous research background and are excited to build real experiments on:
- understanding massive amounts of Agent Trace data
- building + updating Environments over time
- Harness Eng + Post-training over long time horizons
Agent observability is a means to an end: making your agent better.
But observability and evals tools have traditionally failed to connect traces to meaningful actions. Agent engineering teams are left combing through traces, guessing at root causes, and writing evals manually.
We built Engine to close the agent improvement loop. Engine monitors your agent's traces, creates ready-to-merge fixes, and writes evals.
Now every trace becomes a fix, an eval, and a better agent.
very excited for this one!
a year ago, most of what was being traced to LangSmith was "LLM apps". now everything is becoming an agent. with that shift, it's getting harder to know what your software is doing from a UI, and more important to automatically assess quality/perf/security and other dimensions you care about
we're launching evaluator libraries today!
🌉Join us in SF for a meetup on building better agents with the agent and code improvement loops. You'll hear talks by @samecrowder, Head of Product at @LangChain, and @nnennahacks, AI Developer Relations Lead at @QodoAI .
Sam will walk through the agent improvement loop and how teams use traces as the foundation for continuous improvement.
Nnenna will present how Qodo is building agents, their architecture, and how they’re enhancing them using LangSmith.
🗓️ Wed, April 29 | 🕕️ 6 PM | 📍 SF (SOMA)
RSVP 👉️ https://t.co/vCr5H37Kak
LangSmith 🤝 San Francisco
You don't know what your agents will do until you actually run them. What works in demos can break in the real world.
Without tracing and evals, you're just guessing at why. Track what your agent actually does. Optimize and fix your agents. Then measure whether your fixes work.
That loop is how agents get better, and LangSmith is built to power that workflow.
a year ago, it was hard enough to build useful agents that most companies didn't have cost issues. that's changed a lot just from the start of this year!
use langsmith to track agent costs and alert when anything unexpected happens
Introducing Cost Alerting in LangSmith 💸
More and more agents are making it to production, and costs are increasing dramatically.
Use LangSmith to set configurable alerts on total cost, so you know right away when your agents are spending more than they should.
Docs: https://t.co/snH5UIDbiK
Sign up: https://t.co/EyAuPFrQf3
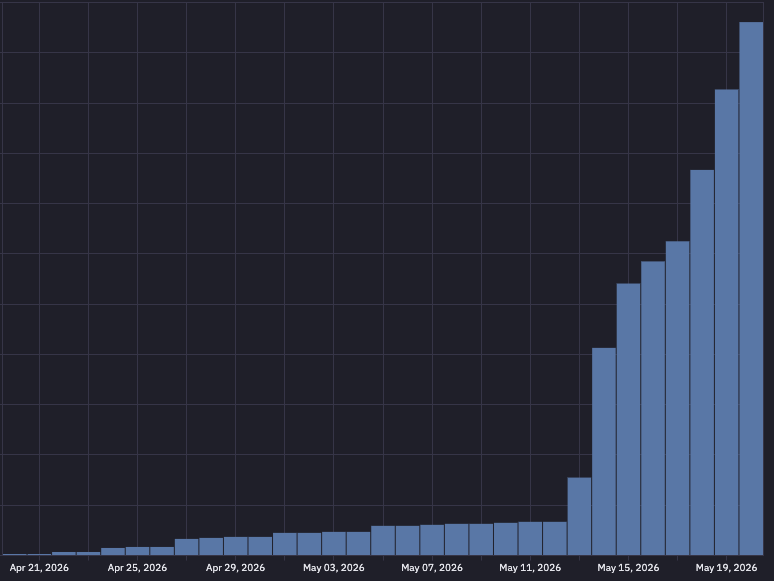
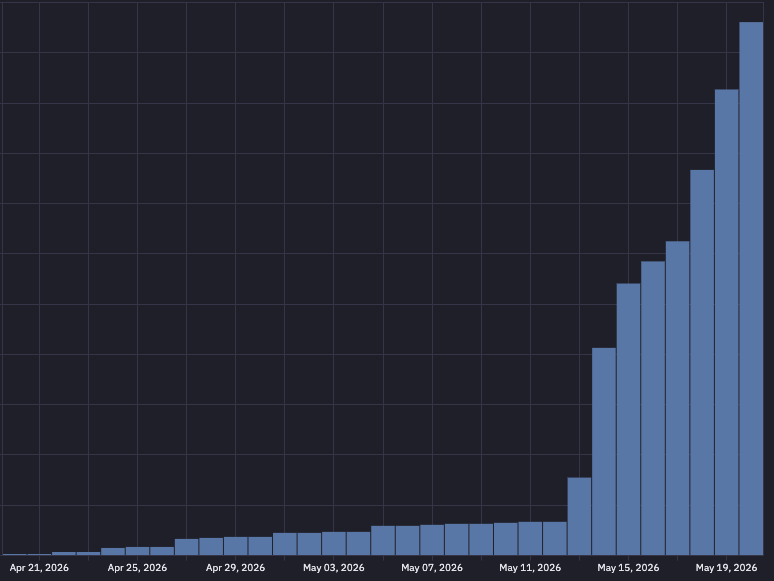
When you're the system of record for 6.7B agent runs, you start to see things 👀
Recent observation - Azure's share of OpenAI traffic nearly 4x'd in under 3 months. The enterprise wave is arriving fast
we just added the ability to assign specific reviewers to an annotation queue. as building agents becomes more and more automated, human feedback being part of the loop will be as critical as ever.
Great stat in here: Claude Code went from 17% to 92% on our eval set once it had access to LangSmith traces and Skills. A coding agent without trace data is just guessing at fixes
Environments in LangSmith Prompt Hub
Environments give you a proper promotion workflow for your prompts:
- Assign any commit to Staging or Production
- Promote between environments instantly
- Roll back with a single click from a full deployment history
- Reference reserved tags (`staging`, `production`) in your code so the right version is always served with no code changes needed
The same promote-and-rollback pattern you already use for app deployments, applied to prompt management. Give it a spin :rocket:
Docs: https://t.co/1c1e0H6ZZr