Google $goog invested about $900m in SpaceX $spcx back in 2015. And it grew to about $120b when $spcx goes public later this month. During that 11 year span, that appreciation is more than the cumulative income google made from Gmail, Drive, Maps, Photos, Chrome, Android licensing, google hardware (pixel phone/tablets, nest, etc.) combined. Absolutely insane.
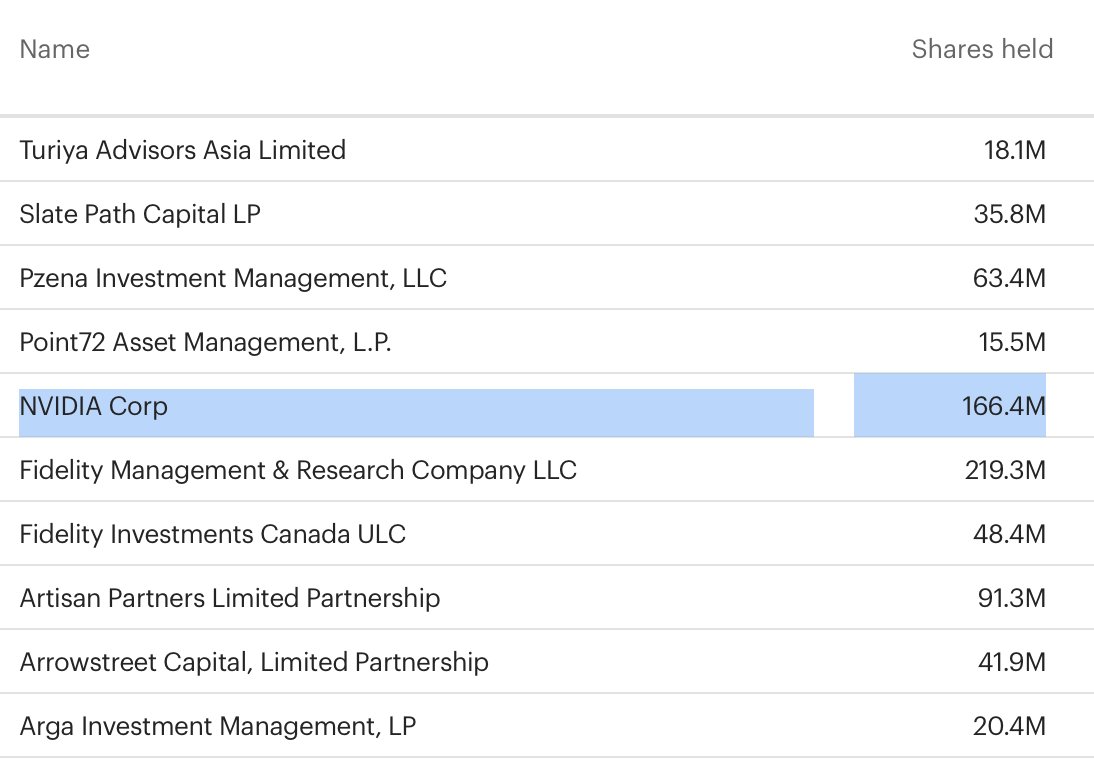
Wow... $nvda gets a FREE leap $70 call option of $iren. The same $70 option expiring on 1/21/28 is now worth $24.75.
That's not all. This also locks $iren more tightly into $nvda's DSX architecture and latest GPUs without $nvda sharing the capital burden upfront.
He who pays the piper calls the tune... $nvda still calls the tune even without having to pay the piper. lol
https://t.co/ihcRim5HN8
Wow... $nvda gets a FREE leap $70 call option of $iren. The same $70 option expiring on 1/21/28 is now worth $24.75.
That's not all. This also locks $iren more tightly into $nvda's DSX architecture and latest GPUs without $nvda sharing the capital burden upfront.
He who pays the piper calls the tune... $nvda still calls the tune even without having to pay the piper. lol
https://t.co/ihcRim5HN8
@elonmusk just dropped TWO massive compute deals on the same week. @SpaceX Colossus is now powering:
- Anthropic’s Claude (full capacity boost, rate limits exploding)
- Cursor (training their next-gen coding AI + $60B acquisition option)
bro is straight up rounding up all the top AI talent and firepower... and pointing them straight at @OpenAI. This isn’t random partnerships. This is chess. he's building the anti-OpenAI alliance with the best models + unlimited Colossus juice.
Who’s next? Perplexity? Or is he going for the whole table?
waiting to see 📷 @sama's counter. #xAI #Colossus
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
If this is accurate, it's a significant breakthrough in subquadratic scaling that enables AI models to process massive codebases with linear complexity and eliminating traditional context window limitations. I wonder if it's ready to tackle long-context coding agents to efficiently handle large-scale, enterprise-level repositories and transform zero-shot refactoring and debugging capabilities.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
This alone is worth upgrading to @macOS Tahoe.
Finder's column view will always resize to fit filenames. While in column view, click on the three dots -> Show View Options -> check Resize columns to fit filenames.
@RealDanODowd@Tesla@elonmusk Morgan Stanley's Adam Jonas in new $TSLA note: "I'm callin' it. Autonomous cars are solved. Do I mean six or seven 9's to the right of the decimal? No. Perfection? Never. But enough to pull the safety driver at scale in major metros."