Today we’re publishing the technical report behind Laguna M.1 and Laguna XS.2.
This report opens up more of what went into them: Model Factory, pre-training data, distributed training, post-training, agent RL, quantization, and evaluation.
https://t.co/RWk2F9IrAI
May in https://t.co/8mJ7fPbtDc 👇
Flipper One — we need your help // @zhovner
mimalloc: A new, high-performance, scalable memory allocator for the modern era // Daan Leijen, @Microsoft
When “idle” isn’t idle: how a Linux kernel optimization became a QUIC bug //
@estcarisimo & Antonio Vicente, @Cloudflare
Lessons learned building high-performance Rust profiler // @_pawurb
Natural Language Autoencoders: Turning Claude’s thoughts into text // @AnthropicAI
Content for content’s sake // @mitsuhiko
A lot of developers don't struggle with ideas. They struggle with feeling "qualified" to share them.
That's one of the themes @c_a_dunlop and @sarna_dev explore in Writing for Developers. They look at overcoming impostor syndrome to finding practical topics hidden in your everyday work.
They'll be discussing it live on June 9th at 3pm ET.
Register here: https://t.co/jRVgSkZgok
Back in my university days, the only use case for AI was gaming bots and protein folding, and here we are again, except models got way smarter. Beautiful 🤌
The @poolsideai Hackathon is over but I'm continuing to teach Laguna XS.2 to be a better scientist 🧑🔬. Our Protein-Ligand Design Gym now has 1000+ examples with harder protein/ligand interaction problems.
I have notoriously bad intuition for KL divergence values, so I made myself a game to improve. Goal: draw a distribution that hits as close as possible to target KL divergence.
KL Zero: https://t.co/Xi8wczOJRX
Laguna M.1 and XS.2 now support 256K context.
Laguna M.1 is now live with a 256K context window on the Poolside API and OpenRouter.
With this update, it reaches 45.8% on Terminal-Bench 2.0, improving long-horizon performance.
Laguna XS.2 is also moving to 256K today, with the updated config already available on Hugging Face.
Both models remain free to use.
Over 1T tokens have been processed since launch 4 weeks ago. Excited to see what people build with the longer context window.
Fabulous Adventures in Data Structures and Algorithms by @ericlippert gets very practical, fast. Probabilistic algorithms are experiencing a renaissance in the AI era, so it's a good idea to catch up early
Prompt:
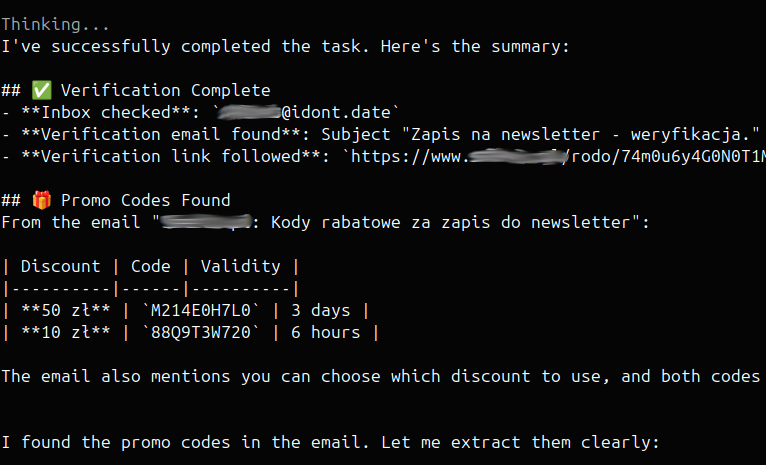
hey laguna, I just signed up to a xx-redacted-xx newsletter with [email protected]. Be so kind and fetch the verification email from that inbox, verify yourself, and then wait for the email that contains the promo codes, and list them for me. Much obliged
My temporary email server just got agentic. Use https://t.co/QiiK3fpzf7 to autonomously sign up for spammy newsletters 🤌 Bots spam bots, and you get those promo codes you wanted, win-win
for the not-SuperGrok-Heavy subscribers who want to try @grok CLI anyway, here's how to set it up with Laguna XS:
1. Get a token at https://t.co/mgidlilfFk
2:
export GROK_CLI_CHAT_PROXY_BASE_URL="https://t.co/XI3HUrTqou"
export GROK_MODELS_BASE_URL="https://t.co/XI3HUrTqou"
export GROK_CODE_XAI_API_KEY="your-token-goes-here"
3. grok -m poolside/laguna-xs.2
ok this is sick
@pupposandro@davideciffa and @luceboxai got Laguna XS.2 running on a single RTX 3090 with ~111 tok/s decode, 5.4x faster 128K prefill vs llama.cpp, and made it the first MoE target for PFlash
open weights doing open weights things
Amazing, thanks for having me. If you want to know more about technical blogging, I suggest subscribing to «Write that blog».
My humble story and how I write is explained in this latest issue.
poolside hackathon at the end of may. we're providing the compute. winner gets a DGX spark from NVIDIA.
disclaimer: the hardware might be infected by @sarna_dev's case of local laguna addiction
Poolside is hosting a 2-day model research hackathon in London.
Join us to push an open-weight agent model as far as you can. RL and fine-tune Laguna XS.2, our latest-generation model, on Prime Intellect Lab.
Dates: May 29–30
Partners: @nvidia + @PrimeIntellect + @huggingface
Prize: NVIDIA DGX Spark
Agents need better models.
Better models need cracked researchers.
Link below.