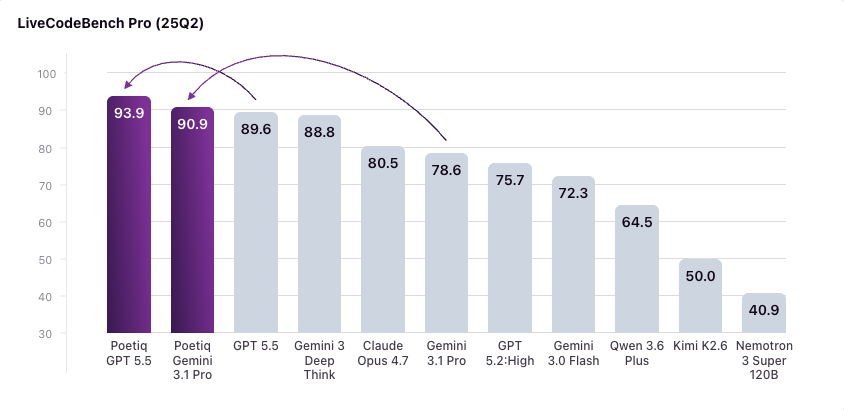
Incredibly proud of the team’s work on this. Recursive self-improvement and automated optimization at inference time yields SOTA on LCB Pro—zero fine-tuning required.
Poetiq's Meta-System built its own coding harness from scratch. It got SOTA on LiveCodeBench Pro.
No fine-tuning, no special model access. Just standard APIs. Using Gemini 3.1 Pro, it made a harness that beat all frontier models we tested.
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
This is exactly the kind of paper I desk reject from my reading list. Reliance on too much jargon from other remote fields, makes it only harder for the readers and not worth the effort. Often, terminology from within the field is sufficient.
Following up on our SOTA results on ARC-AGI, we’re excited to share new SOTA results on Humanity’s Last Exam (both with and without tools) and SimpleQA!
On HLE, Poetiq’s meta-system created multiple new SOTA configurations, going all the way up to 55%.
We’re thrilled to announce a new chapter for Poetiq: We have closed $45.8M in Seed funding.
It’s a privilege to build alongside partners who understand the scale of our vision, including Surface, FYRFLY, @ycombinator, 468, Operator Collective, NeuronVC, and HICO.
We are primates, with a third of our brain dedicated to vision. Graphics are the most effective way to communicate quantitative, spatial, and causal information, but they are as hard to master as clear and stylish prose. Here's an excellent guide to data visualization by Saloni Dattani @salonium https://t.co/tnXYMKKRYA
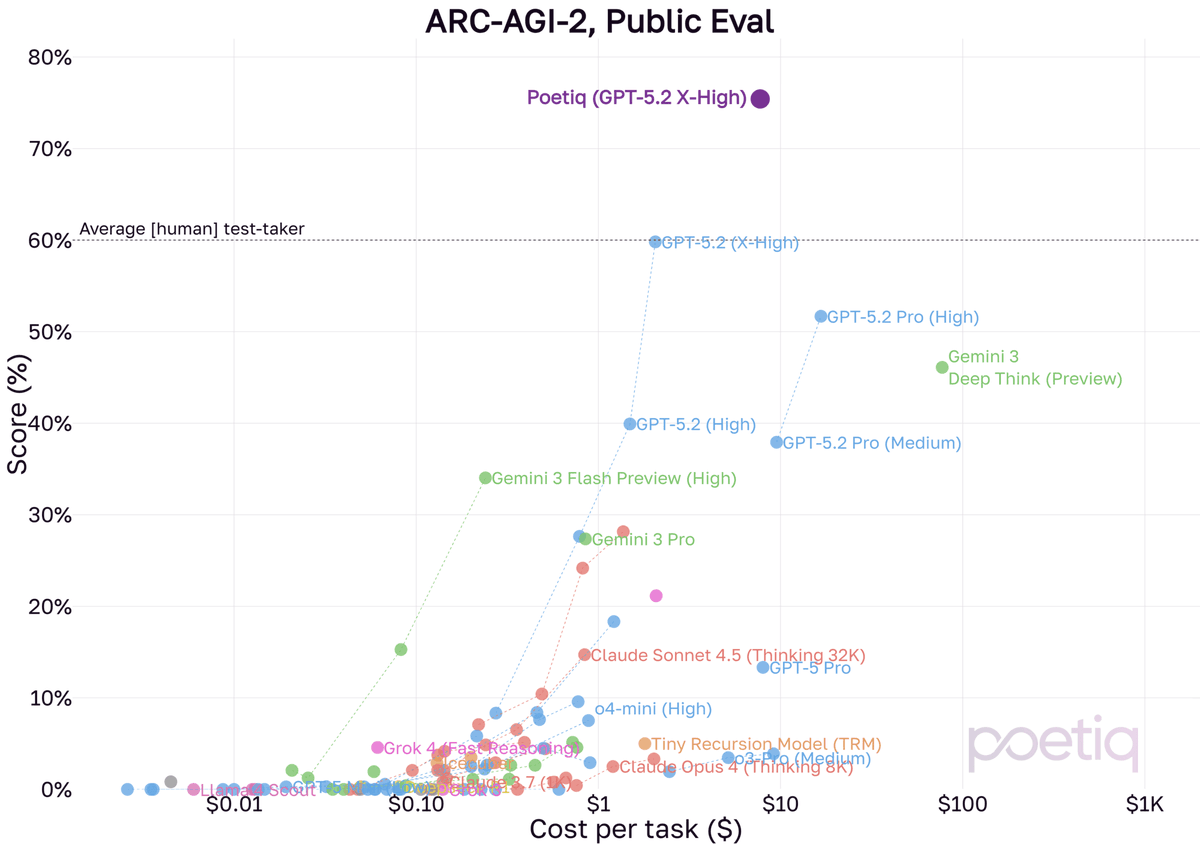
We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
@tbenst Prompt optimization is a reasonable first step and cool! Our released model demonstrates much more than that -- test time reasoning loop. Learned test time reasoning is cooler 😉!
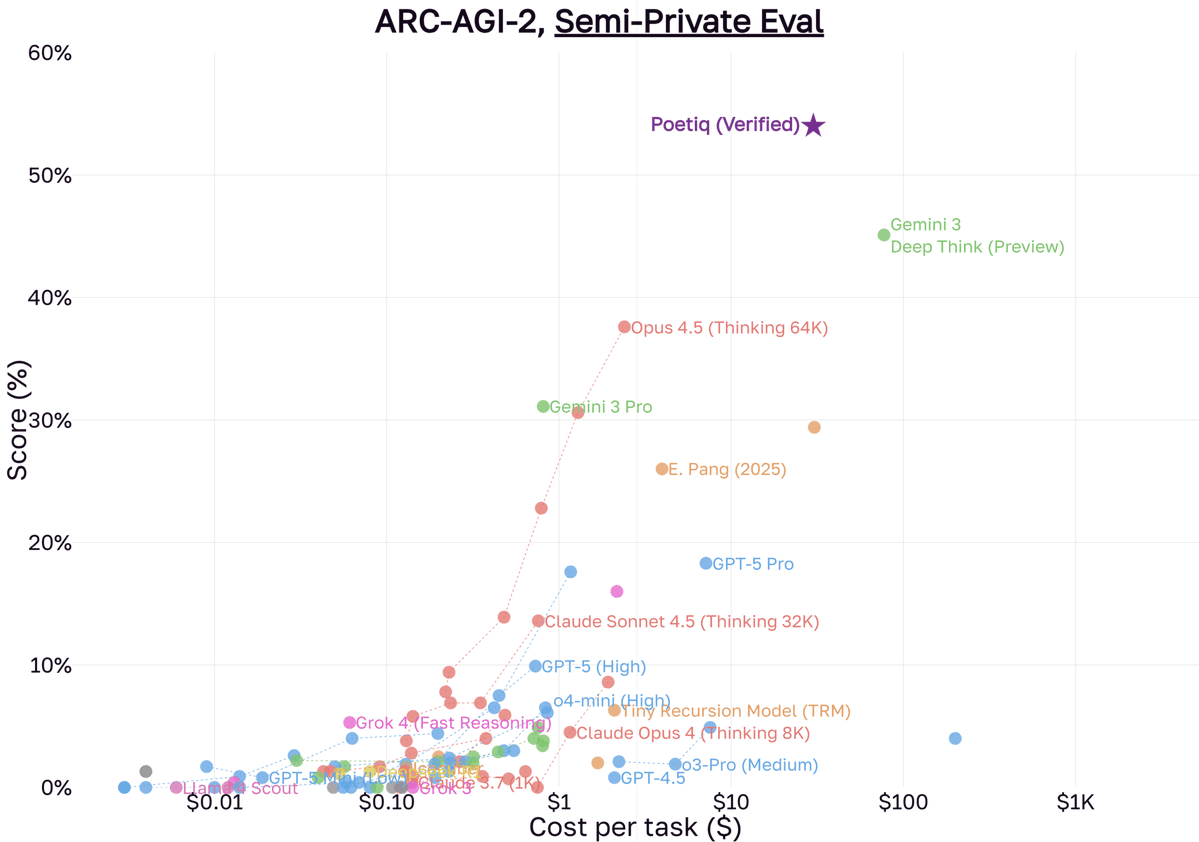
Poetiq has officially shattered the ARC-AGI-2 SOTA 🚀
@arcprize has officially verified our results:
- 54% Accuracy – first to break the 50% barrier!
- $30.57 / problem – less than half the cost of the previous best!
We are now #1 on the leaderboard for ARC-AGI-2!
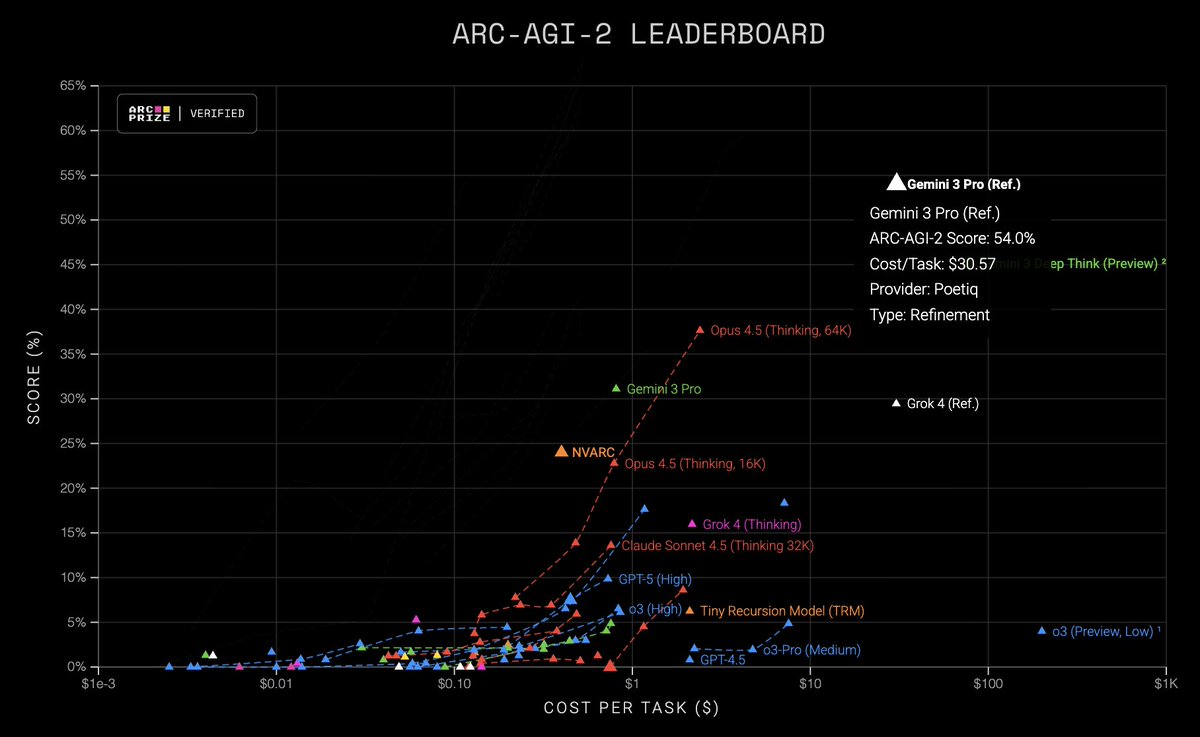
@sachinpeak@arcprize Our results are now officially verified! Though, plot on the official website presents it in a confusing way.
https://t.co/3yuQliGNHO
Poetiq has officially shattered the ARC-AGI-2 SOTA 🚀
@arcprize has officially verified our results:
- 54% Accuracy – first to break the 50% barrier!
- $30.57 / problem – less than half the cost of the previous best!
We are now #1 on the leaderboard for ARC-AGI-2!
Poetiq has officially shattered the ARC-AGI-2 SOTA 🚀
@arcprize has officially verified our results:
- 54% Accuracy – first to break the 50% barrier!
- $30.57 / problem – less than half the cost of the previous best!
We are now #1 on the leaderboard for ARC-AGI-2!
@giffmana I think people really need to read -- The Structure of Scientific Revolutions by Thomas S. Kuhn. A "Hero Scientist", sole inventor etc., is mostly a myth and science advances by communication, collaboration and resulting improvements of ideas.
Poetiq has officially shattered the ARC-AGI-2 SOTA 🚀
@arcprize has officially verified our results:
- 54% Accuracy – first to break the 50% barrier!
- $30.57 / problem – less than half the cost of the previous best!
We are now #1 on the leaderboard for ARC-AGI-2!