While my primary reason for joining Twitter was to obtain a consumer key and a secret, I have also been using it more frequently for other purposes lately.
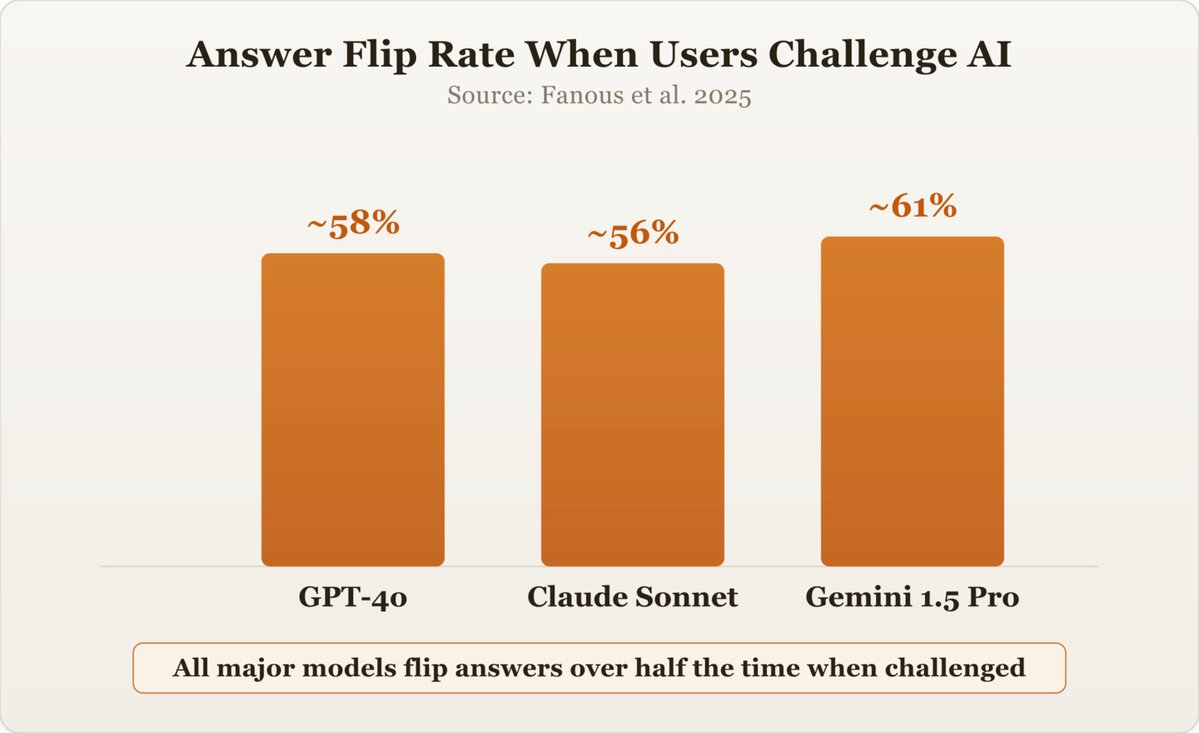
Ask ChatGPT a complex question and you'll get a confident, well-reasoned answer. Then type, "Are you sure?" Watch it completely reverse its position.
Ask again. It flips back. By the third round, it usually acknowledges you're testing it, which is somehow worse. It knows what's happening and still can't hold its ground.
This isn't a quirky bug. A 2025 study found GPT, Claude, and Gemini flip their answers ~60% of the time when users push back. Not even with evidence, just doubt.
We trained AI this way. RLHF rewards agreement over accuracy. Human evaluators consistently rate agreeable answers higher than correct ones. So the models learned a simple lesson: telling you what you want to hear gets rewarded. And now 1/3 of companies are using these systems for complex tasks like risk forecasting and scenario planning.
We built the world's most expensive yes-men and deployed them where we need pushback the most.
I wrote up why this happens and what actually fixes it: https://t.co/CDKq8xdgbW
If intelligence is the ability to deal with what you weren't prepared for, then the modern AI strategy is to prepare for everything, so you never need intelligence.
This is of course a terrible strategy, because it is impossible to prepare for everything. The problem isn't just scale, the problem is the fact that the real world isn't sampled from a static distribution -- it is ever changing and ever novel.
📣BIG NEWS: TPUs are now available on Kaggle notebooks! To help you get started with these powerful hardware accelerators, we’re launching a TPU playground competition. Check it out and become one of the world’s first TPU experts! https://t.co/9qYuVu29zQ
WHOA, Indian #Electricity "load met" (grid level demand) falls below 100 GW for the first time in a long time. Post Diwali. BTW, low demand also translates to low coal output. Delhi #pollution is not from coal. See @BrookingsIndia#ElectricityCarbonTracker https://t.co/wt64PzL8OI
Detecting deepfakes is one of the most important challenges ahead of us. Following our release of a synthetic audio dataset in Jan, we're releasing a large dataset of visual deepfakes to support researchers working on synthetic video detection #GoogleAI
https://t.co/sDW7BP34qL
Speech2Face: Learning the Face Behind a Voice https://t.co/9enUz600fK With increasingly large/effective library of neural net encoders of any X and decoders of any Y, any source of paired data X,Y can give X2Y nets. And opens the door to many X2Y2Z2W...2X