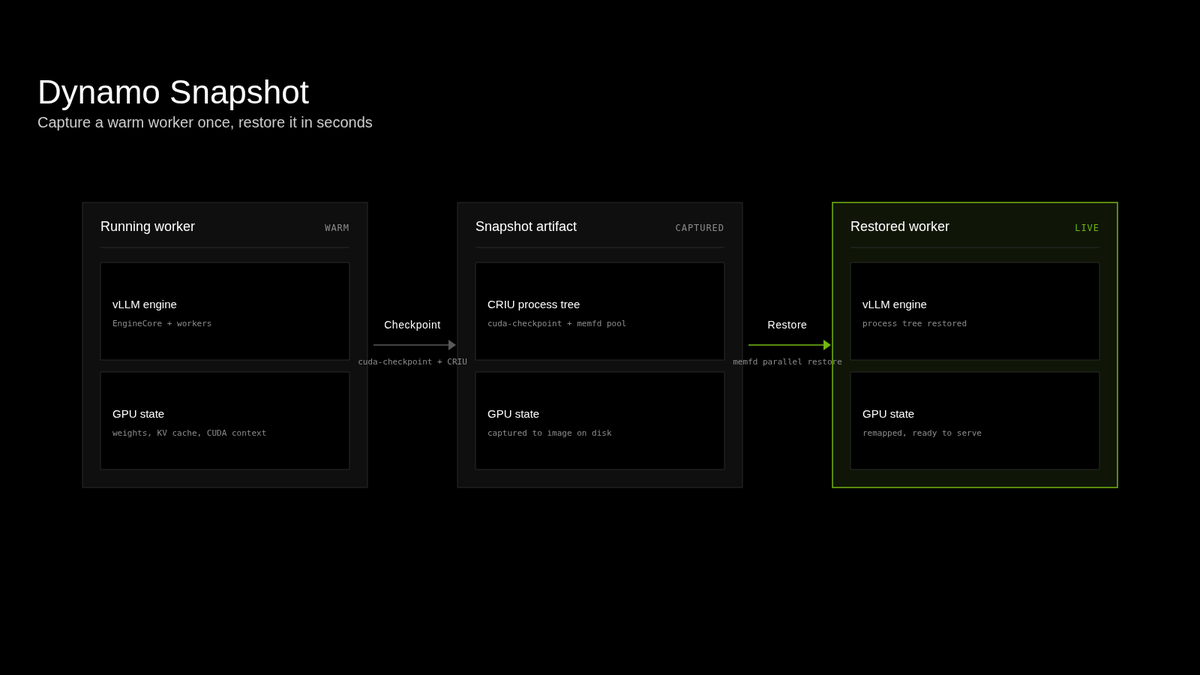
Introducing Dynamo Snapshot, our approach for fast startup for inference workloads on Kubernetes, which reduces startup time from minutes to under 5 seconds.
In production inference deployments demand fluctuates over time. Cold-starting inference workloads can take minutes, leaving idle GPUs that generate no tokens and serve no requests.
Snapshot leverages GMS to enable concurrent weight restoration over a high-speed interconnect, while using Linux native AIO and parallel memfd restoration to accelerate CRIU restore performance.
vLLM's PegaFlow and Dynamo's KVBM are converging on the same bet: external KV cache as a standalone Rust service over a connector boundary. The interesting design choice between them - does the inference engine own the prefix index, or does the storage layer?
A vLLM MoE deployment's DP/EP topology used to be locked in at launch — scaling or swapping config meant a full restart, in-flight traffic dropped. Elastic Expert Parallelism changes that. One API call resizes a live deployment:
curl -X POST localhost:8000/scale_elastic_ep \
-d '{"new_data_parallel_size": 16}'
Under the hood: standby comm groups span the target topology, EPLB redistributes experts across the new EP group, and weights are transferred directly between GPUs over NVIDIA NVLink/RDMA. The same runtime reconfiguration path is what fault-tolerant serving needs: evict failed ranks, redistribute their experts, bring replacements back, no restart.
Thanks to @NVIDIAAI, Sky Computing, @anyscalecompute, @RedHat_AI, and the community.
📖 https://t.co/bHmyFNZPEg
okay this is going kinda viral and tbh my original text was kind of messy, so here's a second pass with the help of Claude:
--
Implement <SPEC>. As you work maintain a running implementation-notes.html file that captures anything I should know about how the implementation diverges from or interprets the spec, including:
- Design decisions: choices you made where the spec was ambiguous
- Deviations: places where you intentionally departed from the spec, and why
- Tradeoffs: alternatives you considered and why you picked what you did
- Open questions: anything you'd want me to confirm or revise
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
When empirical experiments are run, I ask CC to review the decisions made and track evidence supported analysis and give itself a reward and cite this particular technique for future analysis where relevant 😊
I have a variation of this for analysis of papers. To write the intuition gained, thinking behind why this method works vs. does not work for <problem>, evidence to support and the exact citation from the paper to support the decision.
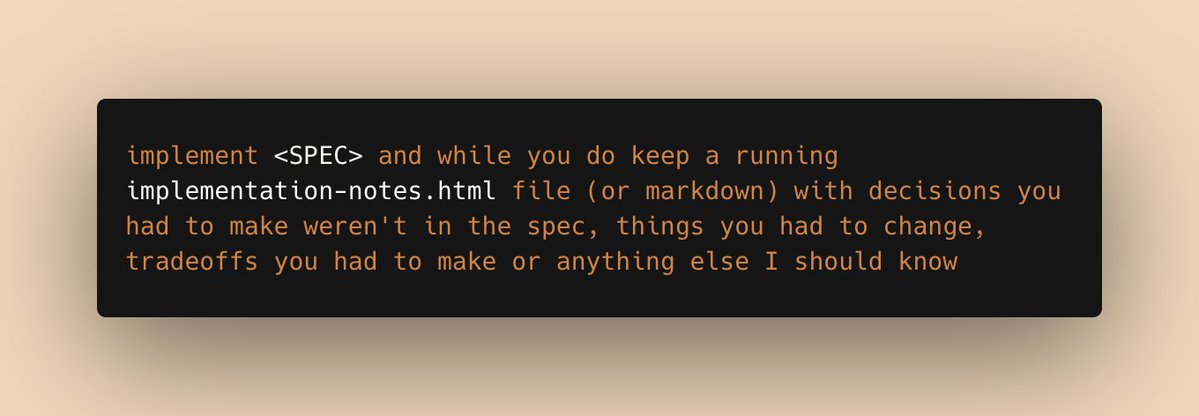
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
Interestingly, long context attention actually enables more opportunities to stream weights into HBM, decreasing the memory requirements for weights stored in HBM at any given time, which pairs well with managing the larger KV cache.
Check out our work on this:
We collaborated with NVIDIA to teach you how we made LLM training ~25% faster! 🚀
Learn how 3 optimizations help your home GPU train models faster:
1. Packed-sequence metadata caching
2. Double-buffered checkpoint reloads
3. Faster MoE routing
Guide: https://t.co/nwvVfNC8XE
This feels like confusing a serving-runtime problem for a chip-startup opportunity.
Agents do change inference patterns: loops, tool calls, branching, long context, KV reuse, burstiness. But most of that is an inference systems problem: scheduling, routing, KV-cache management, etc. Think Dynamo.
By the time a new chip co tapes out + builds a compiler stack + wins cloud distribution, NVIDIA/AMD will likely have baked the obvious hardware-level optimizations into existing platforms.
What a night for the NVIDIA Dynamo community 📸
From OSS commits to production-scale inference, NVIDIA Dynamo is quickly becoming part of the modern AI stack enhancing stability, reliability, and speed.
One thing was clear: faster inference is the new frontier—and Dynamo is the skill to master. Inference is hard (really hard), and the game is shifting.
And the conversations didn’t stop there. An incredible turnout stayed on to connect, share ideas, and celebrate the growing inference ecosystem.
Huge thank you to our speakers from @alibaba_cloud, @baseten, @haoailab, @intel, @Pinterest, @PrimeIntellect, and to everyone who joined us and continues to push Dynamo forward.
📗 https://t.co/9urWKV9Ltt