Claude Opus 4.7 solves its first ProgramBench task 👀
After creating a 663-word CLAUDE.md we were able to increase solve percentage by 1.1 points on Claude Code + Claude Opus 4.7 across 10 ProgramBench, and actually solve one of them.
You can replicate our results here: https://t.co/TuTuKHZ6as
big thanks to @KLieret@jyangballin for releasing such a forward-thinking benchmark!
Hey Richard, congrats on the raise! We met at tony's poker a while back, and I came to your place for the games you hosted. Love Recursive's thesis, we have been looking a lot into auto research environments lately with a few other frontier labs since we believe this is the clearest path for whats next in AI developments, glad you see it the same way. Would love to send you some samples of what we've been working on in dms!
For my eval-maxxing nerds out there, good friends of mine are running a series called "strange evals", you can benchmaxx now on anything. If in SF swing by! https://t.co/1LASlygFln
Introducing Muse Spark, the first in the Muse family of models developed by Meta Superintelligence Labs.
Muse Spark is a natively multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
Muse Spark is available today at https://t.co/wHkMPH82ZH and the Meta AI app. We’re also making it available in private preview via API to select partners, and we hope to open-source future versions of the model.
Learn more: https://t.co/PloE9q5x96
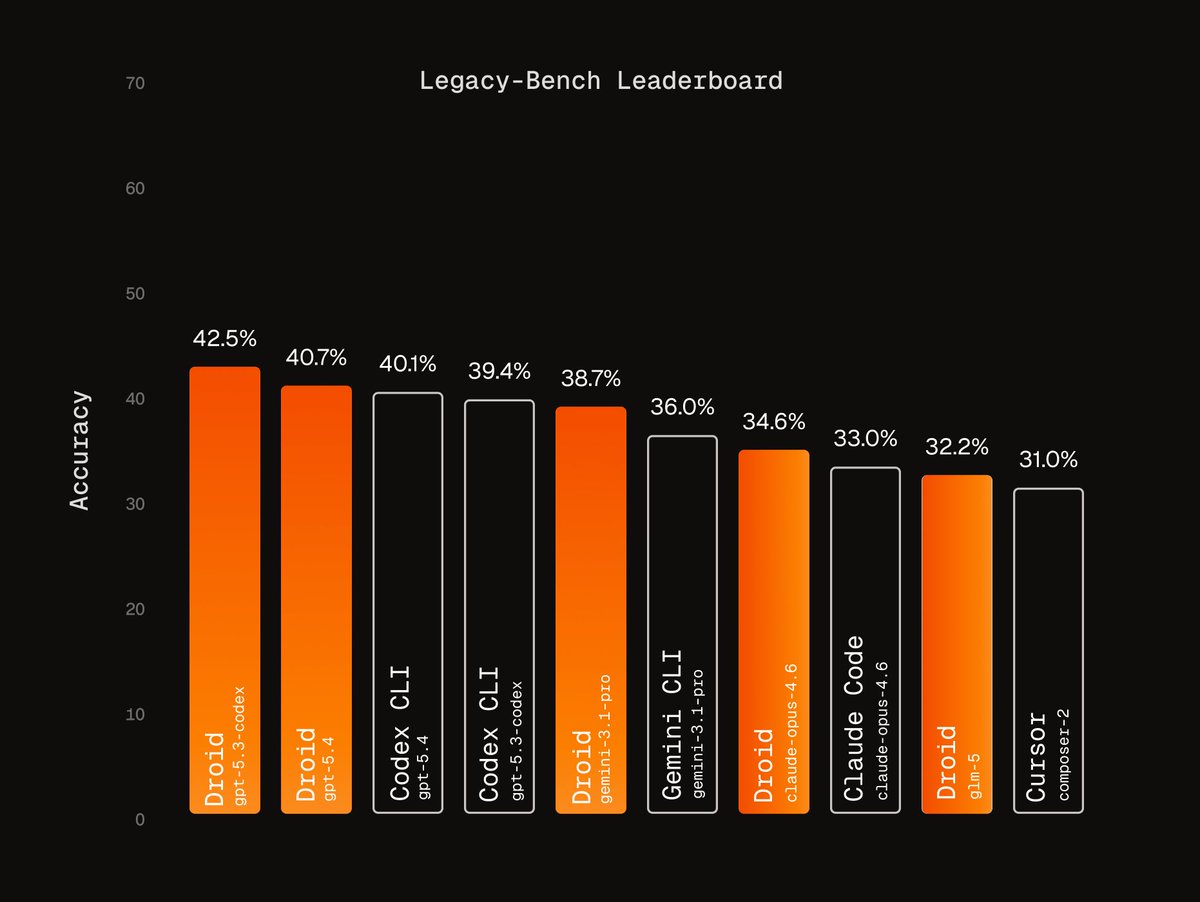
No major benchmark is designed for COBOL, Fortran, or Assembly - the languages powering trillions in transactions and infrastructure that must be modernized or risk catastrophic failure.
We built Legacy-Bench to measure frontier agents on the code the world actually runs on.