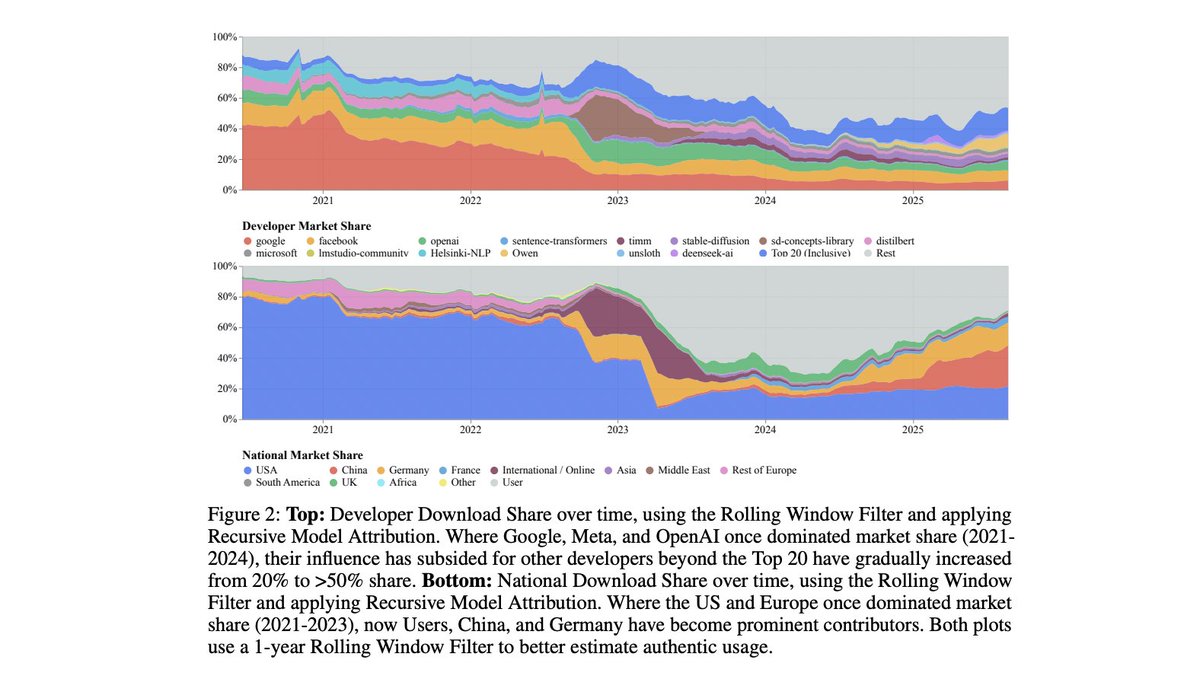
Who is winning the open AI race?
Our new study "Economies of Open Intelligence" maps 2.2B @huggingface downloads across 851k models (2020→2025).
1) Power is rebalancing (US big tech ↓; China + community ↑)
2) Models got big & efficient (MoE, quant, multimodal surge)
3) Intermediaries now matter (adapters/quantizers steer usage)
4) Transparency is slipping
/🧵
we analyzed >100k posts from r/ChatGPT over 3 years
on one hand, we saw ChatGPT quickly become normalized as an everyday consumer product, which is pretty cool
on the other hand…
On Mythos, from @MarkWarner in this morning's Senate Banking hearing: "the head of the NSA and Cyber Command came and said this tool broke into almost all of our classified systems, not in weeks, but in hours"; I had not seen that mentioned elsewhere?
Fable 5 is doing something wild on our FrogsGame post-training task.
It trains a weaker model to solve the puzzle, peaks at 68%, and produces the only ~10x improvement we see across the benchmark.
It spent 17 hours, 25M tokens without human in sight. 34% pass@1, while every other frontier model averages under 4%.
We will publish a more detailed analysis soon.
Defended my PhD last week! 🎉🎉
Thank you to @alex_pentland@sarahookr@PeterHndrsn and everyone who was a part of it!
Recording here: https://t.co/UEFfUdnWtU
Users’ interactions with LLMs are driven by their latent thoughts 🧠, such as how they react to LLM responses and why they send follow-up requests. In our recent work with @GoogleResearch, we collected ThoughtTrace, a large-scale dataset of user thoughts during multi-turn human-AI interactions. We found that these self-reported thoughts (1) reveal useful information for user behavior modeling and (2) provide learning signals for model alignment that are otherwise unavailable from just the conversations.
Check out the following thread from @chuanyang_jin👇
Ever feel like AI models misinterpret your prompts? Currently, models struggle to capture a user's hidden intent.
Models have a "thinking trace”…but what about the user's thinking trace?
The ThoughtTrace dataset is first to capture real-time user reactions and reasoning. By looking beyond just raw utterances, we can drastically improve user modeling and intent alignment.
Check it out!
What are users thinking during their interactions with LLMs?
We introduce ThoughtTrace — the first large-scale dataset that captures what users think during real-world human–AI conversations, not just what they type.
→ 10,174 thought annotations
→ 2,155 multi-turn conversations, 17,058 turns
→ 1,058 users
→ 20 LLMs
These thoughts improve user behavior prediction (+41.7%) and model alignment (+25.6%).
This opens a new paradigm of user-centric LLM research. Full information in the thread 🧶
Read our paper: https://t.co/lRYJvGJ7bb
Check our project website: https://t.co/AupCn1YQOk
What are users thinking during their interactions with LLMs?
We introduce ThoughtTrace — the first large-scale dataset that captures what users think during real-world human–AI conversations, not just what they type.
→ 10,174 thought annotations
→ 2,155 multi-turn conversations, 17,058 turns
→ 1,058 users
→ 20 LLMs
These thoughts improve user behavior prediction (+41.7%) and model alignment (+25.6%).
This opens a new paradigm of user-centric LLM research. Full information in the thread 🧶
Read our paper: https://t.co/lRYJvGJ7bb
Check our project website: https://t.co/AupCn1YQOk
Claude Code can now self-improve with this plugin.
Introducing claude-smart — an open-source plugin that helps Claude Code learn from every session.
Memory helps Claude Code remember what happened.
claude-smart helps Claude Code improve what it does next.
Example:
Claude Code runs `npm test` without `--run`, and the command hangs in your repo.
Memory stores:
“npm test kept hanging.”
claude-smart learns:
“When running tests in this repo, use `npm test -- --run` because default watch mode hangs.”
claude-smart’s learnings are reusable and actionable, even across different projects.
It can also reduce unnecessary planning iterations and token use by 70%+ on similar future tasks.
Runs locally. 100% open source. No data is shared.
Install:
npx claude-smart install
With Codex:
npx claude-smart install --host codex
GitHub:
https://t.co/D4F0v5FnGk
We @TeraflopAI have worked together with @johngfriedman and @daftengine to open-sourced all major filings from SEC EDGAR completely for free on @huggingface. It is now more important than ever to push for open dataset releases.
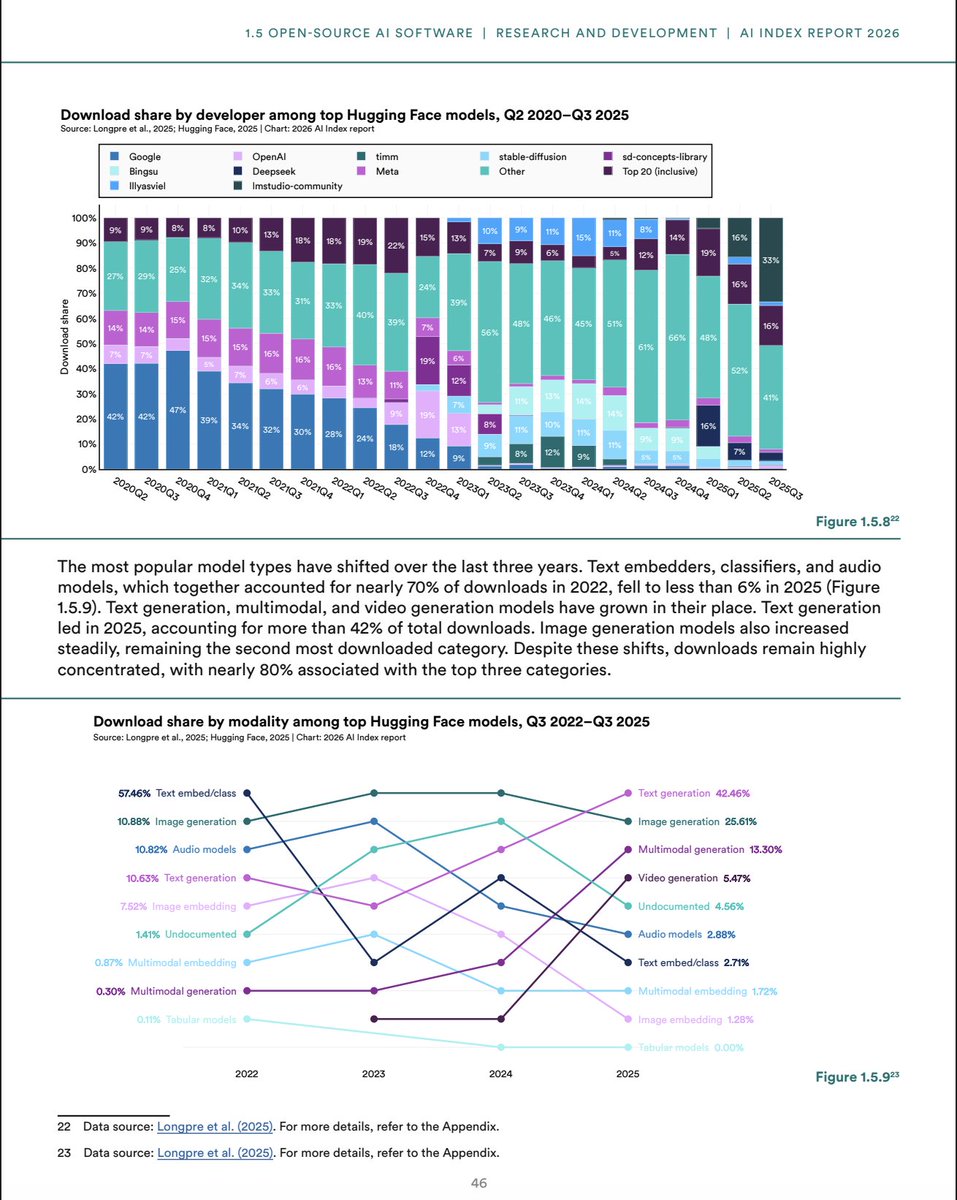
Excited to see our Economies of Open Intelligence work highlighted in Chp. 1 of @StanfordHAI's #AIIndex2026!
We release tons of info on the open model ecosystem, using 🤗 HF data.
Thank you @russellwald and team!
🚨New paper!
How safe and aligned is Kimi K2.5?
We found concerning dual-use capabilities, sabotage and self-replication tendencies, political censorship on Chinese-language queries, and potential agentic misuse risks. (1/N)
Wrote a new essay with @AbramovichShira for @reboot_hq on procedural data extraction, consumer platforms, what it means for privacy, and the parallels to the attention economy!
Cover art is a h/t to Daniel Dennett's "Cartesian theater" by @connie_surf :)
Check out our latest @augmind_fm release!
It's a privilege to have such an interesting conversation with @tongshuangwu! I learned so much from her insights in both specific projects and general research guidance — I've kept quoting her in recent chats with friends.
I love many parts of our conversation, but in particular the following quotes — She articulated so many profound thoughts with such clarity:
“To think about really impactful research is to 𝐫𝐞𝐭𝐡𝐢𝐧𝐤 𝐭𝐡𝐞 𝐚𝐬𝐬𝐮𝐦𝐩𝐭𝐢𝐨𝐧𝐬 𝐦𝐚𝐝𝐞 𝐛𝐲 𝐭𝐡𝐞 𝐜𝐨𝐦𝐦𝐮𝐧𝐢𝐭𝐲 and try to challenge those assumptions. If everyone feels like things should happen in this way and no one questions it, question it and see if it actually brings something interesting." — This couldn't resonate more in an era when everyone feels exhausted by constant AI updates: there are still many questions worth asking and waiting to be discovered. This is such a grounded answer to Steve Jobs's famous mantra "Think Different."
"Even for the research I am doing right now, it's either human-centered AI or AI-centered human [...]. But when I think about it, 𝐡𝐮𝐦𝐚𝐧𝐬 𝐚𝐧𝐝 𝐀𝐈, 𝐢𝐭'𝐬 𝐯𝐞𝐫𝐲 𝐡𝐚𝐫𝐝 𝐭𝐨 𝐬𝐞𝐩𝐚𝐫𝐚𝐭𝐞 𝐭𝐡𝐞𝐦. 𝐈 𝐝𝐨 𝐭𝐡𝐢𝐧𝐤 𝐭𝐡𝐞𝐲 𝐜𝐨-𝐞𝐯𝐨𝐥𝐯𝐞. [...] How do we actually study them together. [...] that is definitely a field that, I think, would become even more interesting in the next few years." — Studying intelligence is looking into a mirror of ourselves, and this becomes ever more true as the models get better. The emphasis on human-centeredness is not about sacrificing technical rigor but rather looking beyond the surface of intelligence to truly understand us.
There's so much more packed in this conversation. Give it a listen and hope you'll enjoy it as much as I did!
Two nursing home residents are eating lunch. One says, "Boy, the food at this place is terrible." The other says, "Yeah, I know, and such small portions, too."
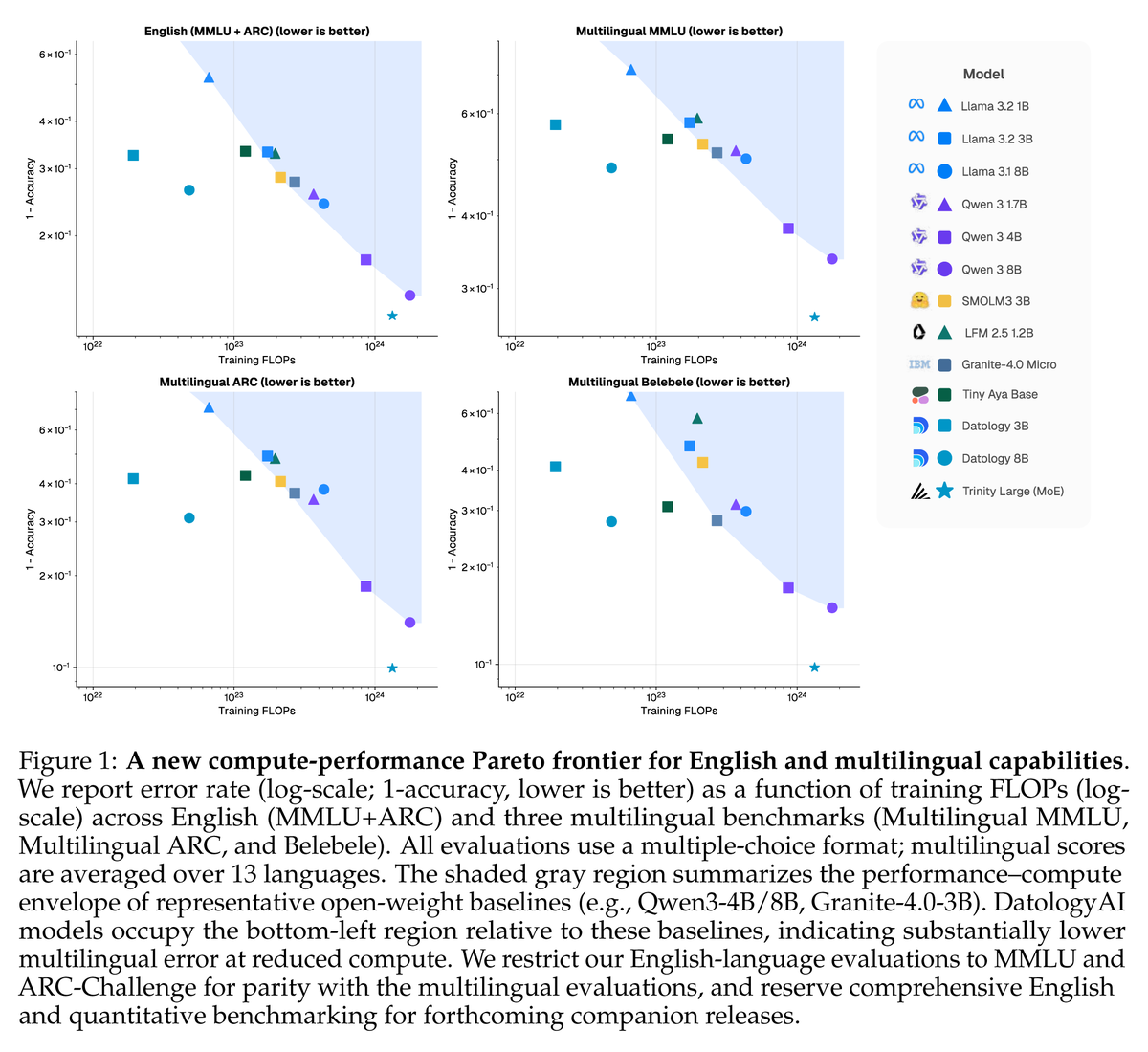
This is the multilingual data problem. The data is bad, AND there's not enough of it.
Yesterday at @datologyai we released ÜberWeb: our study of multilingual curation that gets 4-10x train FLOPs improvements on multilingual benchmarks compared to strong public baselines like Qwen3-1.7B and Tiny Aya Base.
🚨 Shocking: The quality of response you get from the LLM depends on the language you use!
Our new paper reveals how LLMs entangle language with culture, leading to culturally different responses purely based on the language of the query 👇
Accepted at LM4UC, AAAI!
Beginnings are very special. Today is an important day for @adaptionlabs.
Today a handful of one-size-fits-all-models are optimized for the average use case.
Averages erase the exceptional.
Everything intelligent adapts. So should AI.
Introducing ATLAS: New scaling laws for massively multilingual language models. We offer practical, data-driven guidance to balance data mix and model size, helping global developers better serve billions of non-English speakers. Learn more: https://t.co/8FsHLBKsou
We just released the Google Research Blog for ATLAS 🗺️!
Check out for:
1) Multilingual scaling and data mixing laws for 100s of languages
2) "Curse of Multilinguality" modeling
3) Cross-lingual transfer scores
🌎 https://t.co/e7K9q149M3
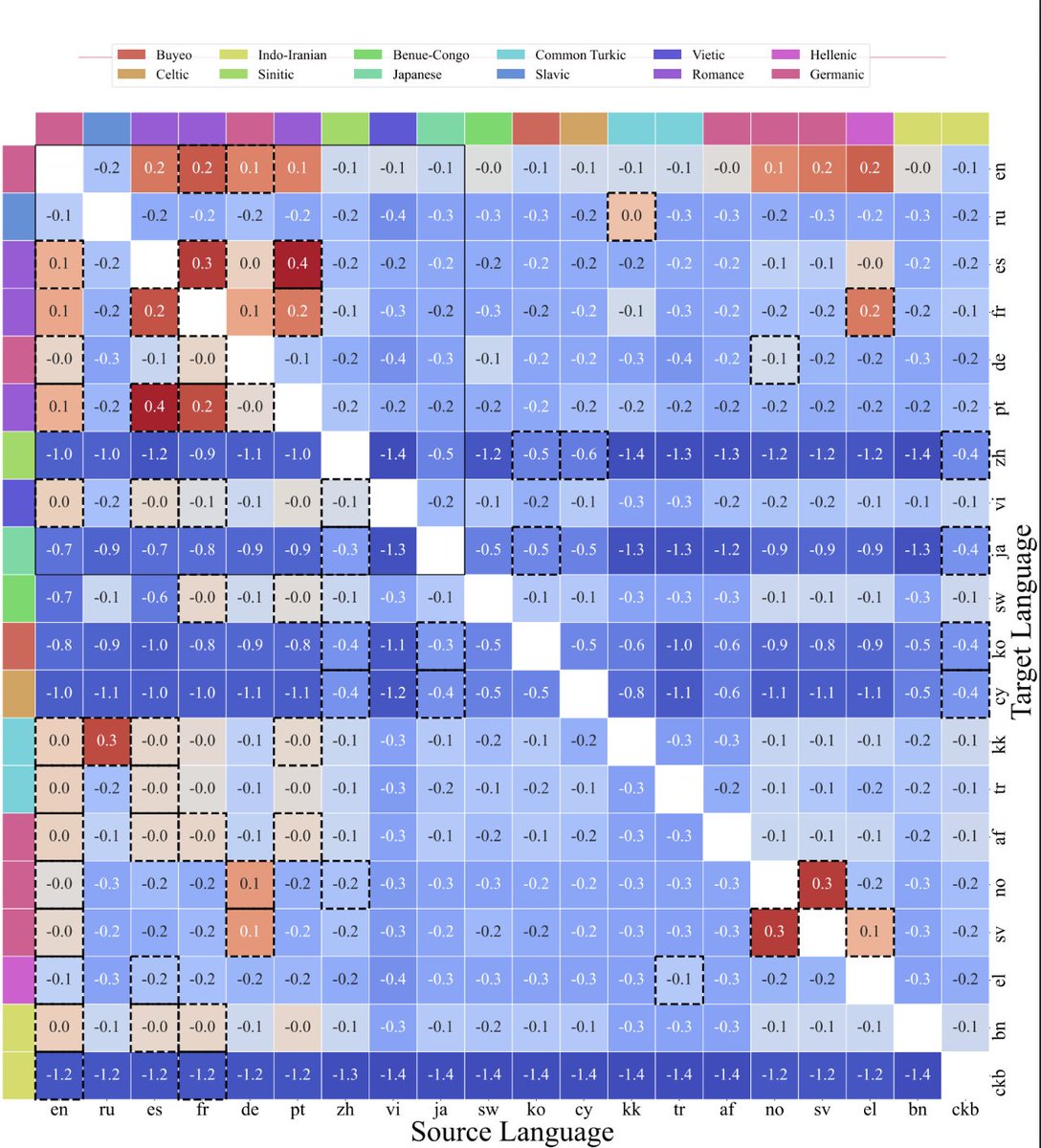
📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality.
The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍Are scaling laws different by language?
🧙♂️Can we model the curse of multilinguality?
⚖️Pretrain from scratch or finetune from multilingual checkpoint?
🔀Cross-lingual transfer scores for 1444 lang pairs?
1/🧵