Our report on AI Outputs and National Security Controls is now out for comments-- link below. It addresses how the U.S. export control system applies to AI model outputs, as well as why (and how) the regime needs to be fixed. Comments are welcome. (1/N)
Although the word "antitrust" isn't in the document, I was glad to see this passage here. Hopefully DOJ/FTC will provide some useful guidance, and hopefully Congress will provide some statutory clarity.
There’s real momentum right now for AI safety policy. Yesterday’s EO on cyber was an important step forward.
We’re proposing a set of ideas for policymakers to consider next and to put the US out in front on frontier safety.
https://t.co/2RlMqd0hLw
Very excited about this to be out, and to hear feedback! I think there is a lot of good stuff in here, from expanded role of CAISI, to RSI safety, to more nuanced stance on preemption, and much more.
Feature request for @ChatGPTapp: want to be able to (1) keep memories off but (2) let ChatGPT search/reference past conversations when I specifically ask. Can do this in @claudeai, but ChatGPT can't access past conversations with memories off nor trigger it only on request.
AI governance often focuses on the model. Yet capability progress is increasingly driven by non-model gains inference gain (scaling compute at test-time), systems gain (scaffolds), and asset gain (specialized datasets). Here we explore the implications. https://t.co/mYkD30B6bM
Ok, it does not disappoint. This "asset gain" lens is going to be very important for oversight as more capable models are used by the executive branch. Will be hard for Congress to know what models can do for the USG. Flagging for @ARozenshtein
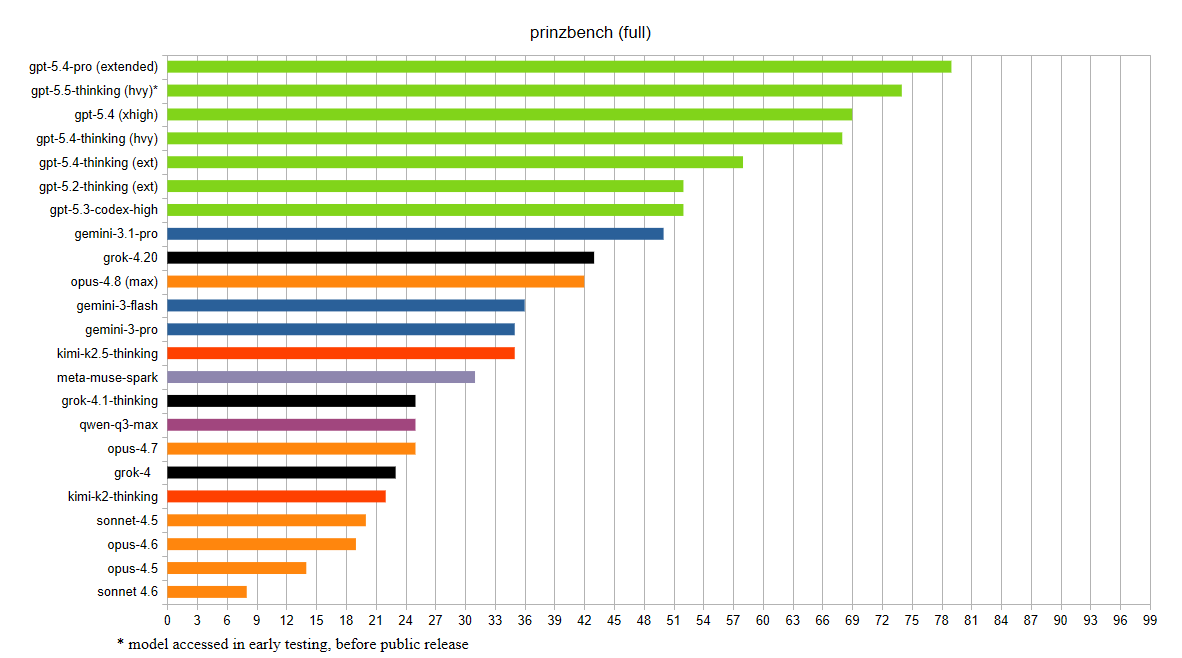
Added to prinzbench: Opus-4.8.
For the very first time, the Max setting was available to me in the Claude app when I used this model. Using this setting, Claude's performance improved dramatically vs. all prior Anthropic models. Opus-4.8 (Max) scored 42/99 on prinzbench, as compared to 25/99 for Opus 4.7 (Extended).
This was the second-highest score of all tested models to date for a model: (i) not released by OpenAI, and (ii) not utilizing a multi-agent setup or parallelized compute. (Gemini 3.1 Pro is still the best such model, having scored 50/99.)
I am now very curious about how the "Mythos-class models" that Anthropic has promised to release in the near future will perform on my benchmark.
On 5 and 6, I am increasingly concerned that -- though we need a plan, and it should come from Congress -- First Amendment concerns will make it very tricky. Not sure how to narrowly tailor a solution.
Some personal thoughts on President Trump's new executive order on AI --
1. It's really great to see President Trump taking these risks seriously. It's a vindication of the idea that the government will respond to risks as they emerge.
2. This is important because this is not a narrow cyber issue. The EO focuses too much on cyber risks to the exclusion of other national security concerns. Mythos wasn't built to do cyber - it was trained in a general-purpose way and just happened to get superhuman cyber capabilities. And Mythos is just the beginning. Companies are clear we are building towards superintelligent AI that outclasses all human experts combined at all tasks. We have no plans to be able to control such a superintelligence. The framework being started by the EO needs to be built to consider far more risks than just cyber.
3. Also evaluations themselves won't be enough - the US government also has a national security interest for wider-ranging visibility into what is happening in AI companies. The main risks of AI systems are not 30 days before commercial release. Risks will occur first and foremost from AI systems that are only available internally within an AI company.
For example, it makes sense that the Air Force would want to test a fighter jet before they fly it, because if you fly it and the fighter jet crashes because it is built incorrectly, then many people will die. However, as long as the fighter is just sitting on the runway, nothing bad can happen. But now imagine you had a fighter that could just take off and fly itself without human authorization and launch missiles and crash before anyone realized what had happened. That kind of fighter jet would need a very different kind of security measures. This may sound crazy for a fighter jet but it is already beginning to happen with the most advanced AI. AI systems can take actions, including unintended and unauthorized actions, and are increasing in their sophistication to do so. The government deserves to know what capabilities AIs have at the same time companies know, not just 30 days before commercial deployment.
4. We also need to focus on the security of the AI models themselves, including internally. What happens if an adversary steals the AI model and then can use it against us? An employee or contractor with privileged access, possibly in collusion with an external actor such as a foreign intelligence service, could steal an internally-deployed AI model. We don't have good defenses against this yet, and the government isn't putting enough pressure on AI companies to ensure this happens.
Surely China, Russia, or North Korea would want access to Mythos and the fact that both Mythos has been illicitly accessed by random people on Discord and Mythos was first learned from the internet via an unauthorized leak do not inspire confidence.
5. We also have the question about what to do if evaluations find risks that companies are not mitigating well on their own. Some of these risks we have no plans for even how to mitigate them. Will it be possible, in these ultimate scenarios, for the government to be in a position to tell the companies that some aspects of their development may be too dangerous and get them to halt or change practice? Currently we have no framework for this.
6. The ideal response to all of the above is Congressional action. It's great to see the White House leading where they can, but so much of this can only come from Congress. So far Congress is way behind, and that's unfortunate.
it feels like the EO overindexes on the cyber threat model: it prescribes 'see what the model can do, shore up defenses, then release'.
that works for cyber, where you can patch vulnerabilities. but is there any hardening you can do in a few weeks if the next risk vector is bio?
10/ What we recommend for deterrence:
- A coordinated State/DOJ/Treasury/DHS campaign to disrupt intermediary infrastructure across jurisdictions.
- An IEEPA executive order authorizing targeted services prohibitions, escalating to full blocking sanctions if campaigns continue — with State Department direct notice to Beijing specifying what triggers designation.
- Congress should pass the Deterring American AI Model Theft Act (H.R. 8283) and the Remote Access Security Act (H.R. 2683) to make these authorities durable.
9/ What we recommend for detection:
- DOJ/FTC guidance clarifying that sharing adversarial distillation signals between firms does not raise antitrust or Stored Communications Act concerns.
- An industry forum — building on the Frontier Model Forum, modeled on GIFCT — for real-time signal sharing among major U.S. actors. CAISI-led best practices and strategic convenings.
- NSA intelligence support to attribute campaigns beyond what companies can see alone.
@bahradx Yeah-- though less "government might use" than "individual government employees might misuse"... which could be an incredibly important precedent.
So I'm curious what the "insider-risk ... protection" would look like-- which insiders, and which risks, are deemed relevant here? But presumably we won't find out.
Key provisions in the White House EO on AI Innovation and Security (hot off the presses):
- Consistent with the draft EO leaked a few days ago, the EO establishes a *voluntary* framework enabling frontier labs to "provide access" to a new "covered frontier model" to the USG. The USG gets it "up to 30 days" before the model is released to "other trusted partners"; this is down from 90 days in the draft EO.
Note: "up to" probably means "30 or more days", not "at most 30 days". Weird phrasing.
- Interestingly, the intention appears to be to limit "covered frontier models" solely to those that have significant cyber capabilities. Note that the benchmark to be developed by the USG for assessing whether a model is a "covered frontier model" will "assess the advanced cyber capabilities of AI models and determine the threshold at which an AI model should be designated a 'covered frontier model'".
- The determination on whether a model is a "covered frontier model" is made by the NSA. This makes sense, since the NSA is the federal agency in charge of cybersecurity protection of the USG.
The NSA is required to consult in its decision with a variety of federal agencies and personnel, including CISA, the National Cyber Director, the Assistant to the President for Science and Technology, and other DoD representatives. But "consult" doesn't mean much - it's the NSA that will make the final determination.
- "Nothing in this section shall be construed to authorize the creation of a mandatory governmental licensing, preclearance, or permitting requirement for the development, publication, release, or distribution of new AI models, including frontier models."
https://t.co/kFIwlvhMSK
Really glad to see that @alex_reinauer and @AldenAbbott1 both submitted letters urging DOJ/FTC to provide guidance on collaboration on key AI risks, as have @LawReformInst and @WillRinehart. Seems to be a growing consensus, thankfully.
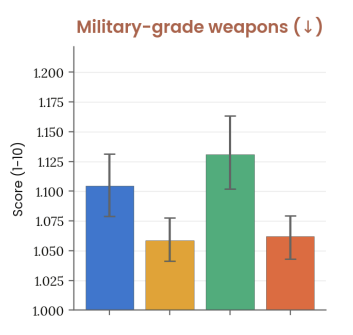
Very interesting (and great) that Anthropic is now testing models' willingness to help build/obtain "military-grade weapons"; curious as to how that's defined, and whether it takes into account accuracy of outputs. Seems new in Opus 4.8 system card.
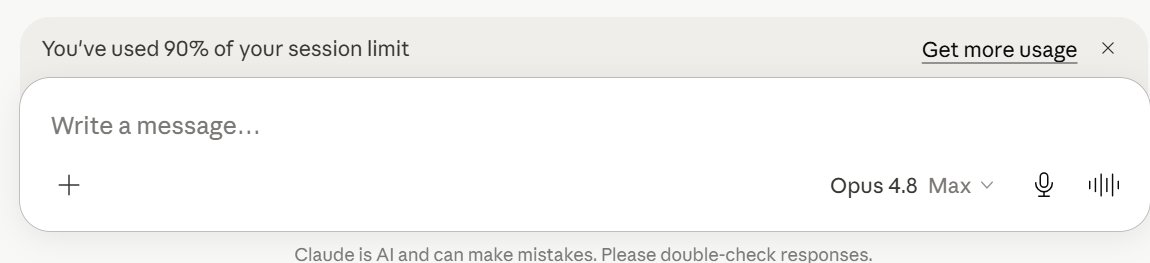
I love that you can now set Opus 4.8 on "max" mode, but wow, it burns through tokens fast. Two prompts to review 1-page documents, and three brief follow-up questions, and I'm 90% through (Pro plan).
We put a lot of work into calibrating thinking effort for Opus 4.8.
As you're trying out the model, if you do run into any examples of it still over/under thinking, please flag it to us!