A bunch of companies are banning developers from pushing vibe-coded software to production.
Who didn't see this one coming?
Vibe-coding is amazing, but we are now realizing what happens when we let anyone put autogenerated slop in front of users.
We need something better.
Scientists at Stanford Medicine have proposed an explanation for the rare cases of myocarditis that can occur after mRNA COVID-19 vaccination. The research points to a two-step inflammatory process involving the cytokines CXCL10 and IFN-gamma.
According to the study, vaccine-activated immune cells, particularly macrophages, produce high levels of CXCL10. This molecule then stimulates T cells to release IFN-gamma, creating a potent inflammatory signal that can damage heart muscle cells. The team confirmed this pathway through experiments using human heart tissue models, immune cells, and mice.
Importantly, blocking CXCL10 and IFN-gamma reduced signs of heart injury in laboratory models while largely preserving the protective immune response generated by the vaccine. The researchers also tested genistein, a natural compound found in soybeans, which showed anti-inflammatory effects in the models, though further clinical studies are required.
Myocarditis following mRNA vaccination is very rare, occurring in approximately 1 in 140,000 people after the first dose and 1 in 32,000 after the second, with higher rates observed in young males. Most cases are mild and resolve with full recovery. The study notes that COVID-19 infection itself carries a significantly higher risk of myocarditis, roughly 10 times greater than vaccination.
This work may inform the development of safer future mRNA vaccines while underscoring the established benefits of current ones in preventing severe COVID-19 outcomes.
[Cao, X., et al. (2025). Inhibition of CXCL10 and IFN-γ ameliorates myocarditis in preclinical models of SARS-CoV-2 mRNA vaccination. Science Translational Medicine, 17(828)]
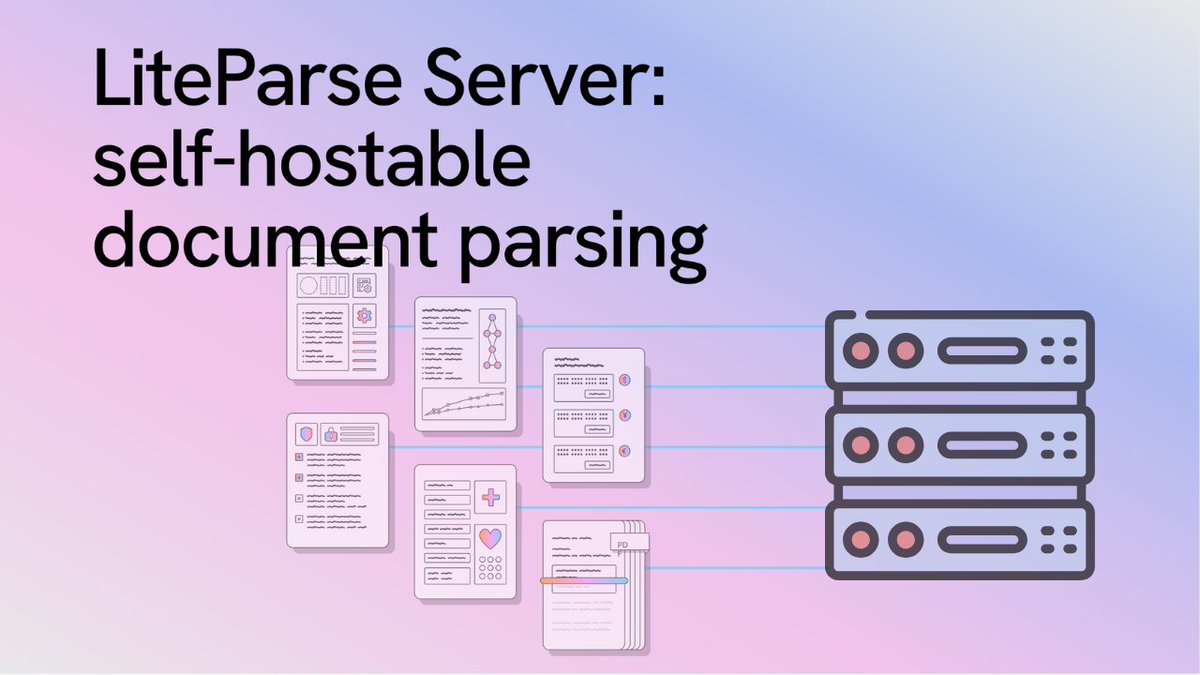
Need document parsing that stays fully local and private? 👀
Meet liteparse-server, a self-hostable, open-source HTTP server for parsing documents and generating screenshots from PDFs, Office files, and images.
✅ 100% self-hosted
✅ Private by default
✅ Open source
✅ Built for production deployments
Deploy it as:
🐳 a @Docker container
⚡ or a serverless Express.js API
It also integrates easily with:
- @Redisinc for caching and rate limiting
- @opentelemetry-compatible collectors for traces and metrics
- observability tools like @JaegerTracing, @PrometheusIO and @grafana
Read the full breakdown here: https://t.co/E3y2ZHvURm
GitHub repo: https://t.co/K0d8XVEFGK
I really didn't expect another major open-weight LLM release this December, but here we go: NVIDIA released their new Nemotron 3 series this week.
It comes in 3 sizes:
1. Nano (30B-A3B),
2. Super (100B),
3. and Ultra (500B).
Architecture-wise, the models are a Mixture-of-Experts (MoE) Mamba-Transformer hybrid architecture. As of this morning (Dec 19), only the Nano model has been released as an open-weight model, so this post will focus on that one (shown in my drawing below).
Nemotron 3 Nano (30B-A3B) is a 52-layer hybrid Mamba-Transformer model that interleaves Mamba-2 sequence-modeling blocks with sparse Mixture-of-Experts (MoE) feed-forward layers, and uses self-attention only in a small subset of layers.
There’s a lot going on in the figure above, but in short, the architecture is organized into 13 macro blocks with repeated Mamba-2 → MoE sub-blocks, plus a few Grouped-Query Attention layers. In total, if we multiply the macro- and sub-blocks, there are 52 layers in this architecture.
Regarding the MoE modules, each MoE layer contains 128 experts but activates only 1 shared and 6 routed experts per token.
The Mamba-2 layers would take a whole article itself to explain (perhaps a topic for another time). But for now, conceptually, you can think of them as similar to the Gated DeltaNet approach that Qwen3-Next and Kimi-Linear use, which I covered in my Beyond Standard LLMs article.
The similarity between Gated DeltaNet and Mamba-2 layers is that both replace standard attention with a gated-state-space update. The idea behind this state-space-style module is that it maintains a running hidden state and mixes new inputs via learned gates. In contrast to attention, it scales linearly instead of quadratically with the input sequence length.
What’s actually quite exciting about this architecture is its really good performance compared to pure transformer architectures of similar size (like Qwen3-30B-A3B-Thinking-2507 and GPT-OSS-20B-A4B), while achieving much higher tokens-per-second throughput.
Overall, this is an interesting direction, even more extreme than Qwen3-Next and Kimi-Linear in its use of only a few attention layers. However, one of the strengths of the transformer architecture is its performance at a (really) large scale. I am curious to see how the larger Nemotron 3 Super and especially Ultra will compare to the likes of DeepSeek V3.2.
Olmo models are always a highlight due to them being fully transparent and their nice, detailed technical reports.
I am sure I'll talk more about the interesting training-related aspects from that 100-pager in the upcoming days and weeks.
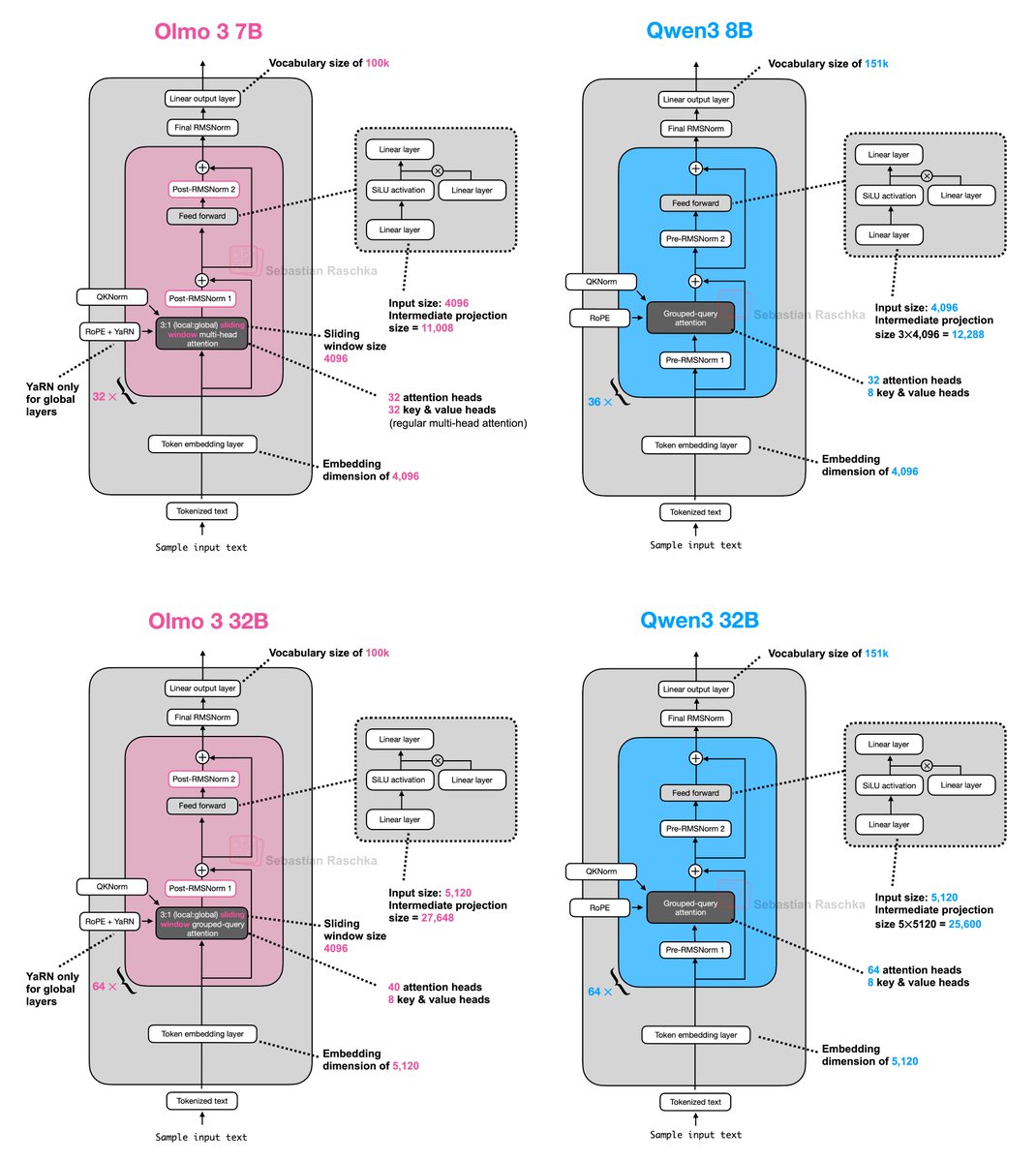
In the meantime, here's the side-by-side architecture comparison with Qwen3.
1) As we can see, the Olmo 3 architecture is relatively similar to Qwen3. However, it's worth noting that this is essentially likely inspired by the Olmo 2 predecessor, not Qwen3.
2) Similar to Olmo 2, Olmo 3 still uses a post-norm flavor instead of pre-norm, as they found in the Olmo 2 paper that it stabilizes the training.
3) Interestingly, the 7B model still uses multi-head attention similar to Olmo 2. However, to make things more efficient and shrink the KV cache size, they now use sliding window attention (e.g., similar to Gemma 3.)
Next, let's look at the 32B model.
4) Overall, it's the same architecture but just scaled up. Also, the proportions (e.g., going from the input to the intermediate size in the feed forward layer, and so on) roughly match the ones in Qwen3.
5) My guess is the architecture was initially somewhat smaller than Qwen3 due to the smaller vocabulary, and they then scaled up the intermediate size expansion from 5x in Qwen 3 to 5.4 in Olmo 3 to have a 32B model for a direct comparison.
6) Also, note that the 32B model (finally!) uses grouped query attention.
The most effective AI Agents are built on these core ideas.
It's what powers Claude Code.
It's referred to as the Claude Agent SDK Loop, which is an agent framework to build all kinds of AI agents.
(bookmark it)
The loop involves three steps:
Gathering Context: Use subagents (parallelize them for task efficiency when possible), compact/maintain context, and leverage agentic/semantic search for retrieving relevant context for the AI agent. Hybrid search approaches work really well for domains like agentic coding.
Taking Action: Leverage tools, prebuilt MCP servers, bash/scripts (Skills have made it a lot easier), and generate code to take action and retrieve important feedback/context for the AI agent. Turns out you can also enhance MCP and token usage through code execution and routing, similar to how LLM routing increases efficiency in AI Agents.
Verifying Output: You can define rules to verify outputs, enable visual feedback (this becomes increasingly important in multimodal problems), and consider LLM-as-a-Judge to verify quality based on fuzzy rules. Some problems will require visual cues and other forms of input to perform well. Don't overcomplicate the workflow (eg, use computer-using agents when a simple Skill with clever scripts will do).
This is a clean, flexible, and solid framework for how to build and work with AI agents in all kinds of domains.
McKinsey just dropped its 2025 AI report.
1. Everyone’s testing, few are scaling.
88% of companies now use AI somewhere.
Only 33% have scaled it beyond pilots.
2. The profit gap is huge.
Just 6% see real EBIT impact.
Most are still stuck in “experiments,” not execution.
3. The winners think bigger.
Top performers aren’t cutting costs. They’re redesigning workflows and creating new products.
4. AI agents are emerging.
23% are testing agents.
Only 10% have scaled them (mostly in IT and R&D).
5. The jobs shift is starting.
30% of companies expect workforce reductions next year, mostly in junior or support roles.
TL;DR:
AI adoption is nearly universal. Impact isn’t.
The gap between pilots and profit is where the next unicorns will be built.
Python for Data Analysis: https://t.co/LGw4ZkJLR3 by @wesmckinn
↕️
Definitive handbook for manipulating, processing, cleaning, & crunching datasets in #Python. Updated 3rd edition is packed with practical case studies that show how to solve a broad set of data analysis problems.
↕️
Read it online: https://t.co/5dnRG51ikc
I am recruiting 2 PhD students to work on LM interpretability at UMD @umdcs starting in fall 2026!
We are #3 in AI and #4 in NLP research on @CSrankings.
Come join us in our lovely building just a few miles from Washington, D.C. Details in 🧵


















![Rainmaker1973's tweet photo. Scientists at Stanford Medicine have proposed an explanation for the rare cases of myocarditis that can occur after mRNA COVID-19 vaccination. The research points to a two-step inflammatory process involving the cytokines CXCL10 and IFN-gamma.
According to the study, vaccine-activated immune cells, particularly macrophages, produce high levels of CXCL10. This molecule then stimulates T cells to release IFN-gamma, creating a potent inflammatory signal that can damage heart muscle cells. The team confirmed this pathway through experiments using human heart tissue models, immune cells, and mice.
Importantly, blocking CXCL10 and IFN-gamma reduced signs of heart injury in laboratory models while largely preserving the protective immune response generated by the vaccine. The researchers also tested genistein, a natural compound found in soybeans, which showed anti-inflammatory effects in the models, though further clinical studies are required.
Myocarditis following mRNA vaccination is very rare, occurring in approximately 1 in 140,000 people after the first dose and 1 in 32,000 after the second, with higher rates observed in young males. Most cases are mild and resolve with full recovery. The study notes that COVID-19 infection itself carries a significantly higher risk of myocarditis, roughly 10 times greater than vaccination.
This work may inform the development of safer future mRNA vaccines while underscoring the established benefits of current ones in preventing severe COVID-19 outcomes.
[Cao, X., et al. (2025). Inhibition of CXCL10 and IFN-γ ameliorates myocarditis in preclinical models of SARS-CoV-2 mRNA vaccination. Science Translational Medicine, 17(828)]](https://pbs.twimg.com/media/HI_-smYWAAAbca8.jpg)