Qwen first release on interpretability (qwen scope) is very interesting
they use SAE features to identify what causes repetition in model outputs, then use steering to manufacture a "bad" rollout where the model repeats a lot. this gives RL a clear negative signal to learn from, since repetition barely shows up in normal rollouts so the model never gets punished for it
they also use SAE features as a fingerprint for benchmarks, you look at which features each benchmark activates and compare overlap. lets you find redundancy inside a benchmark and across benchmarks without running any model. for instance 63% of GSM8K features are in MATH but only 10% the other way
OpenAI just released a new open-source model
it's "a bidirectional token-classification model for personally identifiable information (PII) detection and masking in text"
https://t.co/xTZt1J3WcT
https://t.co/PwaJ0rL2Cz
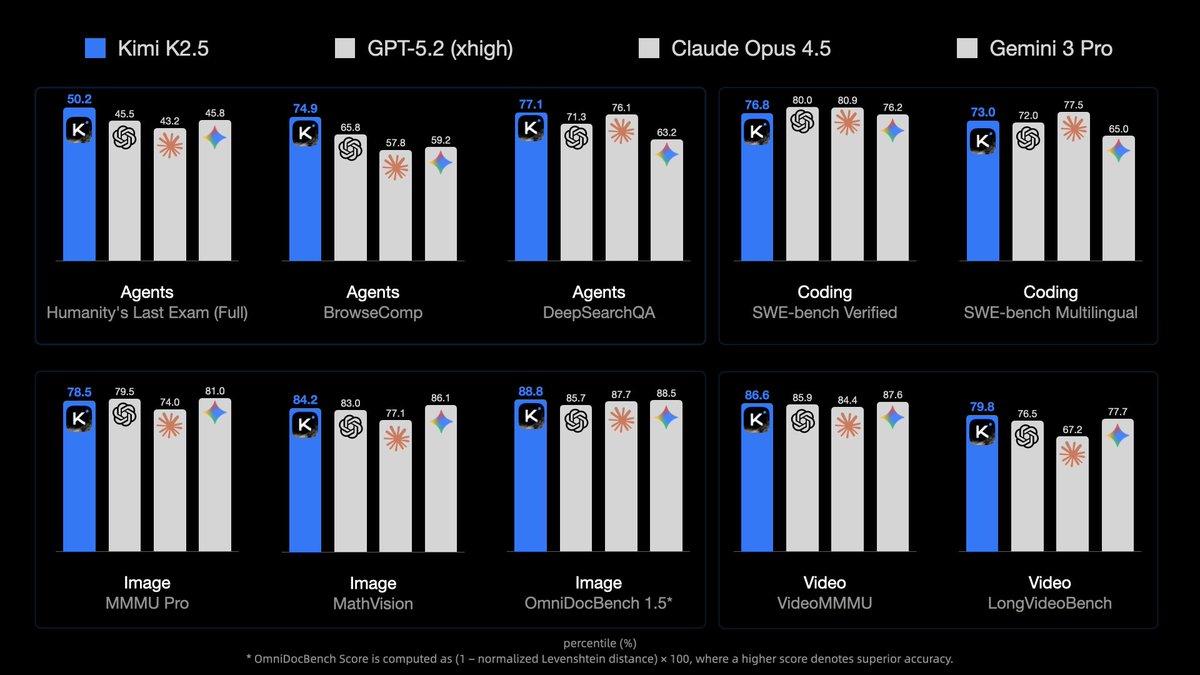
🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence.
🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%)
🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%)
🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion.
🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup.
-
🥝 K2.5 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
🥝 K2.5 Agent Swarm in beta for high-tier users.
🥝 For production-grade coding, you can pair K2.5 with Kimi Code: https://t.co/A5WQozJF3s
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/6h2KkoA0xd
🔗 Weights & code: https://t.co/H38KegeDIY
Excited to be in Suzhou for #EMNLP2025! I’m presenting our main conference paper showing how LLMs push computation into the last token’s residual stream (https://t.co/q0kaqiytwP). If you work on interpretability/alignment and want to chat (I’m applying for PhD positions starting in 2026), feel free to DM me!
🎉Check out our recent papers accepted to #NeurIPS and #EMNLP on #MechInterp of LLMs (I'm hiring Fall'26 PhDs on this topic)
#NeurIPS2025 Failure by Interference: Language Models Make Balanced Parentheses Errors When Faulty Mechanisms Overshadow Sound Ones
(https://t.co/UHc0WkeCd7 w/ @DakingRai, Sam Miller, @kevpmo)
My recent favourite! We propose a new perspective of "top-down mechanism decomposition" to understand why LMs fail. Surprisingly, even when LMs fail, we can discover reliable internal mechanisms that can successfully solve the task, and we found that the model fails mostly because the faulty mechanisms overshadow the sound ones! Steering the sound mechanisms solves the problem. We proved the idea on a Code Generation task (balanced parentheses) and found it generalizes to Arithmetic Reasoning.
#EMNLP2025 All for One: LLMs Solve Mental Math at the Last Token With Information Transferred From Other Tokens
(https://t.co/0tKM3a8taY w/ @siddarthpm1@DakingRai@YilunZhou)
We try to understand how LLMs calculate for a + b - c. Humans solve it following a compositional formulation: a+b first, and -c later. But LLMs do not necessarily do the same. We discover a highly faithful subgraph, where LLMs transfer all information to the last token position and complete all calculations there. Such a sparse and non-compositional subgraph surprisingly generalizes to multiple LLMs.
#EMNLP2025 A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
(https://t.co/jDdhmVO4NA w/ @DuMNCH Ninghao Liu, and their students Dong Shu, Xuansheng Wu, Haiyan Zhao, and my student @DakingRai)
If you've enjoyed our recent survey and #ICML tutorial on Mech Interp (https://t.co/AtFz8XEjYB), this survey will give you more details specifically about SAEs! A must-read;)
#EMNLP2025 Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models
(https://t.co/NRkOckrlmG led by @DuMNCH and his students Zihao Li and Xu Wang)
We extract SAE features representing Verbal Process and Symbolic Process of an LLM's CoT reasoning and perform steering to enhance their effect.
Congrats and thanks to all collaborators!
How do LLMs perform direct math calculations? Check out our new #EMNLP2025 mechanistic interpretability paper led by @siddarthpm1 where we propose and validate a novel transformer circuit that captures the essence of this operation (spoiler alert: it works nothing like a human).
Thanks for reading this far! If you found this interesting, be sure to check out the full paper and the code, and feel free to contact me with any questions or clarifications. A huge thanks to @YilunZhou, @ZiyuYao, and @DakingRai for the extensive guidance and helping me to my first first-author publication at a major conference! (10/10)
Paper: https://t.co/CeFWrgKv5d
Code: https://t.co/D4r5D9TqqF
🚨New EMNLP 2025 Paper: When a human does mental math like 12+45-8, we tend to do it stepwise: first compute 12+45=57, then 57-8=49. Does an LLM do the same? Turns out it doesn’t. But how does it work? Our paper investigates exactly this! 🧵(1/10)
Paper: https://t.co/CeFWrgKv5d
Code: https://t.co/D4r5D9TqqF
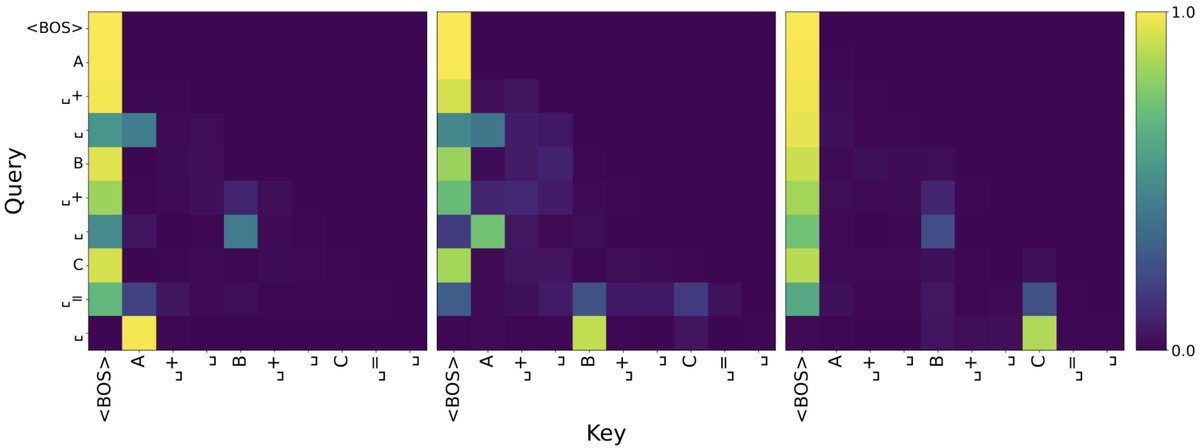
We also performed a series of further experiments investigating the exact responsible attention heads in the key layers. The figure below shows attention patterns in 3 of the 5 key attention heads we identified in the transfer layers, each of which allows the last token to attend to a different operand (last row), further supporting the information transfer hypothesis! (9/10)
Thanks @rohanpaul_ai for featuring our EMNLP 2025 paper! Super-proud of the work, led by @siddarthpm1, undergrad (read: PhD applicant very soon) from UCSC!
In short, we uncovered a quite surprising mechanism of LLM solving arithmetic, but stay tuned for our own explainer thread!
When a language model solves a math problem in its head, where in the network is the real calculation happening?
This paper finds that almost all the actual math gets done right at the very last token of the sequence, not spread out across all the tokens.
The earlier tokens spend a lot of layers just holding information and doing general setup.
Then, in just 2 middle layers, they pass their information to the last token. After that, the last token finishes the calculation on its own and produces the answer.
They built two techniques to test this, called Context-Aware Mean Ablation (CAMA) and Attention-Based Peeking (ABP).
These methods let them force the model to only work in certain ways, so they could see which parts were essential. With these tools, they discovered a sparse circuit, which they call All-for-One (AF1).
This circuit is surprisingly efficient: most of the network can wait, then only a couple of layers are needed to hand off information, and the final token does the job.
This works really well on plain arithmetic like "42 + 20 - 15". But the shortcut fails if the problem is written as a word problem or inside Python code, because then the model also needs to understand language or programming context.
In short, the big insight is that language models don’t spread math work across the whole sequence. Instead, they rely heavily on the last token, with just a brief moment of information passing from the earlier ones.
----
Paper – arxiv. org/abs/2509.09650
Paper Title: "All for One: LLMs Solve Mental Math at the Last Token With Information Transferred From Other Tokens"