Would you realize if the book you were reading was AI? What if it was humanized to remove AI-speak?
We find that even without using stylistic cues (e.g., word choice or sentence structure) narrative choices alone give AI fiction away!
👀 Can AI produce a novel worth reading? We built a platform to find out.
📚 Introducing AutoFiction: a web platform that hosts AI-generated novels by Claude Code & Codex, rated and reviewed by real readers.
We have 33 books so far, spanning dark fantasy, murder mysteries, Harry Potter fanfics, and more. All free to read.
(1/n)
AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
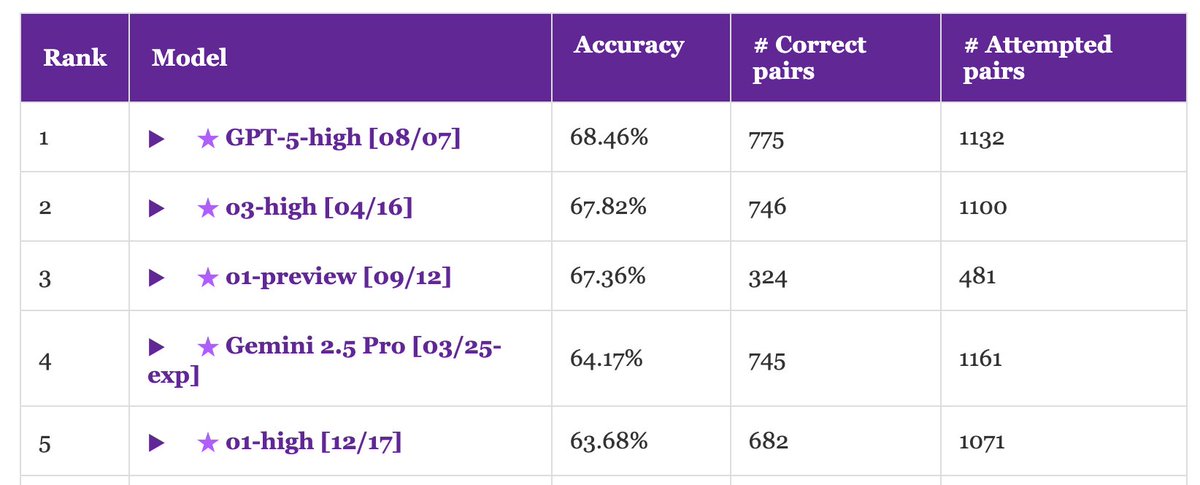
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
Phase 1 of Physics of Language Models code release
✅our Part 3.1 + 4.1 = all you need to pretrain strong 8B base model in 42k GPU-hours
✅Canon layers = strong, scalable gains
✅Real open-source (data/train/weights)
✅Apache 2.0 license (commercial ok!)
🔗https://t.co/Nk3tOY2ICp
🏆 Our @nvidia KV Cache Compression Leaderboard is now live!
Compare state-of-the-art compression methods side-by-side with KVPress. See which techniques are leading in efficiency and performance. 🥇
https://t.co/kP9fdEG5JZ
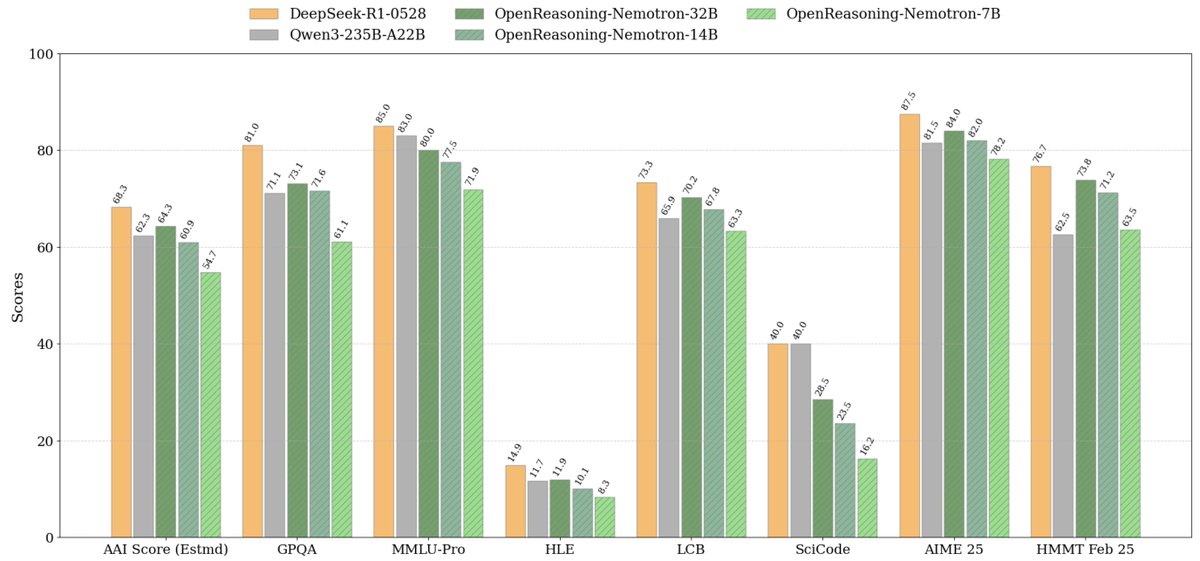
We've released a series of OpenReasoning-Nemotron models (1.5B, 7B, 14B and 32B) that set new SOTA on a wide range of reasoning benchmarks across open-weight models of corresponding size.
The models are based on Qwen2.5 architecture and are trained with SFT on the data generated with DeepSeek-R1-0528.
A few highlights 🧵
Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly increase (/decrease) the probability of every action I took for the future". You get a lot more leverage from verifier functions than explicit supervision, this is great. But first, it looks suspicious asymptotically - once the tasks grow to be minutes/hours of interaction long, you're really going to do all that work just to learn a single scalar outcome at the very end, to directly weight the gradient? Beyond asymptotics and second, this doesn't feel like the human mechanism of improvement for majority of intelligence tasks. There's significantly more bits of supervision we extract per rollout via a review/reflect stage along the lines of "what went well? what didn't go so well? what should I try next time?" etc. and the lessons from this stage feel explicit, like a new string to be added to the system prompt for the future, optionally to be distilled into weights (/intuition) later a bit like sleep. In English, we say something becomes "second nature" via this process, and we're missing learning paradigms like this. The new Memory feature is maybe a primordial version of this in ChatGPT, though it is only used for customization not problem solving. Notice that there is no equivalent of this for e.g. Atari RL because there are no LLMs and no in-context learning in those domains.
Example algorithm: given a task, do a few rollouts, stuff them all into one context window (along with the reward in each case), use a meta-prompt to review/reflect on what went well or not to obtain string "lesson", to be added to system prompt (or more generally modify the current lessons database). Many blanks to fill in, many tweaks possible, not obvious.
Example of lesson: we know LLMs can't super easily see letters due to tokenization and can't super easily count inside the residual stream, hence 'r' in 'strawberry' being famously difficult. Claude system prompt had a "quick fix" patch - a string was added along the lines of "If the user asks you to count letters, first separate them by commas and increment an explicit counter each time and do the task like that". This string is the "lesson", explicitly instructing the model how to complete the counting task, except the question is how this might fall out from agentic practice, instead of it being hard-coded by an engineer, how can this be generalized, and how lessons can be distilled over time to not bloat context windows indefinitely.
TLDR: RL will lead to more gains because when done well, it is a lot more leveraged, bitter-lesson-pilled, and superior to SFT. It doesn't feel like the full story, especially as rollout lengths continue to expand. There are more S curves to find beyond, possibly specific to LLMs and without analogues in game/robotics-like environments, which is exciting.
Introducing IFBench, a benchmark to measure how well AI models follow new, challenging, and diverse verifiable instructions. Top models like Gemini 2.5 Pro or Claude 4 Sonnet are only able to score up to 50%, presenting an open frontier for post-training. 🧵
📢 Can LLMs really reason outside the box in math? Or are they just remixing familiar strategies?
Remember DeepSeek R1, o1 have impressed us on Olympiad-level math but also they were failing at simple arithmetic 😬
We built a benchmark to find out → OMEGA Ω 📐
💥 We found that although very powerful, RL struggles to compose skills and to innovate new strategies that were not seen during training. 👇
work w. @UCBerkeley@allen_ai
A thread on what we learned 🧵
We know Attention and its linear-time variants, such as linear attention and State Space Models. But what lies in between?
Introducing Log-Linear Attention with:
- Log-linear time training
- Log-time inference (in both time and memory)
- Hardware-efficient Triton kernels
🧵 1/8 The Illusion of Thinking: Are reasoning models like o1/o3, DeepSeek-R1, and Claude 3.7 Sonnet really "thinking"? 🤔 Or are they just throwing more compute towards pattern matching?
The new Large Reasoning Models (LRMs) show promising gains on math and coding benchmarks, but we found their fundamental limitations are more severe than expected.
In our latest work, we compared each “thinking” LRM with its “non-thinking” LLM twin. Unlike most prior works that only measure the final performance, we analyzed their actual reasoning traces—looking inside their long "thoughts". Our analysis reveals several interesting results ⬇️
📄 https://t.co/PjnYpVRdX3
Work led by @ParshinShojaee and @i_mirzadeh, and with @KeivanAlizadeh2, @mchorton1991, Samy Bengio.
✨ New paper ✨
🚨 Scaling test-time compute can lead to inverse or flattened scaling!!
We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways:
➡️ Frontier LLMs struggle on Seal-0 (SealQA’s core set): most chat models (incl. GPT-4.1 w/ browsing) achieve near-zero accuracy
➡️ Advanced reasoning models (e.g., DeepSeek-R1) can be highly vulnerable to noisy search results
➡️ More test-time compute does not yield reliable gains: o-series models often plateau or decline early
➡️ "Lost-in-the-middle" is less of an issue, but models still fail to reliably identify relevant docs amid distractors
📜: https://t.co/oAb3mUsQOp
🤗: https://t.co/Gm0HoIvZKO
🧵:👇
🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
🚀 New paper on evaluating retrieval robustness – how well LLMs handle imperfect retrieval:
1️⃣ RAG >= non-RAG?
2️⃣ More docs >= fewer docs?
3️⃣ Sensitivity to doc order
▶️ 11 LLMs × 3 prompting strategies
Findings: LLMs show surprisingly high robustness—but limitations remain. 1/2
How much do language models memorize?
"We formally separate memorization into two components: unintended memorization, the information a model contains about a specific dataset, and generalization, the information a model contains about the true data-generation process. When we completely eliminate generalization, we can compute the total memorization, which provides an estimate of model capacity: our measurements estimate that GPT-style models have a capacity of approximately 3.6 bits per parameter. We train language models on datasets of increasing size and observe that models memorize until their capacity fills, at which point “grokking” begins, and unintended memorization decreases as models begin to generalize."
Does RL truly expand a model’s reasoning🧠capabilities? Contrary to recent claims, the answer is yes—if you push RL training long enough!
Introducing ProRL 😎, a novel training recipe that scales RL to >2k steps, empowering the world’s leading 1.5B reasoning model💥and offering new insights into the debate.
new paper! 🫡
why are state space models (SSMs) worse than Transformers at recall over their context? this is a question about the mechanisms underlying model behaviour: therefore, we propose using mechanistic evaluations to answer it!