Ethereum is preparing for a post-quantum future.
The transition away from BLS signatures starts with a dedicated Post-Quantum (PQ) Public Key Registry.
https://t.co/H1UUFfUZqk
Here is a deep dive into the design space, XMSS, and how Ethereum will secure its validators. 🧵👇
Today a crazy quantum story just got wilder.
On March 31, the Google Quantum AI team published a landmark result on Shor's algorithm for elliptic curve cryptography. Technically, the paper was a bombshell: a dramatic 10x improvement over the state-of-the-art. As a stunt and wakeup call to the blockchain space, those optimisations were illustrated on secp256k1, the elliptic curve underlying Bitcoin and Ethereum signatures.
But perhaps the most striking part of the paper was sociological, not technical. Instead of following standard academic process, the optimisations were kept secret, hidden behind a zero-knowledge (ZK) proof. Google's accompanying blog post mentions they "engaged with the U.S. government". The ZK proof demonstrates the existence of algorithmic improvements without leaking details. Academic censorship with ZK, a historic first!
As a co-author of the Google paper I witnessed some of the context surrounding this censorship. To be honest, multiple aspects of that context don't sit well with me. As much as I believe the general public ought to know more, I am limited in my ability to whistleblow. Though let me be clear about one thing: the Google team's professionalism has been absolutely exemplary, and they deserve nothing but praise.
Censorship has a way of backfiring. The Streisand effect, where an attempt to bury something only draws more attention to it, is exactly what's unfolding today. First, Google's key optimisation has been rediscovered by the French. And in a thrilling turn of events, a collaborative Shor-at-home challenge just launched. The initiative, available at ecdsa[.]fail, breached a new Shor world record in a matter of hours.
Let's start with the rediscovery. Just two months after Google's paper, French quantum expert André Schrottenloher cracks the main secret optimisation. His paper, titled "Optimized Point Addition Circuits for Elliptic Curve Discrete Logarithms", landed on the arXiv today. Big congrats to André, who beat several other nerdsnipped experts to it. In a blog post also published today, Craig Gidney, the world expert on Shor optimisations, revealed that he'd been sitting on this very optimisation for a whole year under censorship pressure.
Interestingly, André missed a handful of minor optimisations, both from Google's original publication and from improvements found since. It's plausible there's still plenty of juice left to squeeze out of Shor, and this is exactly what the ecdsa[.]fail challenge is about. The verifier program developed for the ZK proof does double duty, automatically filtering for valid submissions. Dozens of compounding small and micro improvements are rolling in. As of the time of writing there's an 8.4% improvement to Google's circuit, as measured by the product of logical qubit count and Toffoli gate count. Nice!
The nerdsnipping ran deeper than anyone expected. Over the last few weeks it became clear it extended well beyond André and other quantum experts. Behind the scenes, a small army of amateurs quietly got to work. Inspired by Karpathy-style autoresearch, they turned AI on Shor. Ironically, the verifier program for the ZK proof makes an ideal reward function for AIs. The barrier to entry for this modern style of research is refreshingly low, with several non-experts, even a teenager, finding nice optimisations. Get in touch if you'd like to join a Telegram group with fellow autoresearchers :)
Part 2: neutral atoms and qday
The story doesn't end with Google. On the same day Google went public, a stealthy startup called Oratomic published its own Shor paper in a coordinated release. It made a splash, ultimately becoming the most upvoted paper on scirate[.]com, a website ranking arXiv papers.
Oratomic's claim was wild. By building on Google's logical optimisations and applying custom physical optimisations for neutral atoms, they claimed just 10K physical qubits were sufficient to run Shor's algorithm on secp256k1. That number is mind-bogglingly low.
Knowing essentially nothing about neutral atoms when Oratomic's paper landed, I was intrigued and decided to learn more about the tech. I fell straight down the rabbit hole and spent a couple hundred hours on the topic. I got a little obsessed and watched every YouTube video I could find and spoke to a bunch of experts.
My conclusion? The tech is real, very real. Even Google recently decided to start a neutral atom lab, a notable pivot from their sole focus on superconducting qubits. If you care about qday, i.e. the day a quantum computer will break the first piece of cryptography in production, neutral atoms demand your attention. I shared some of my learnings on Shor and neutral atoms in a 30min talk at the ZKProof cryptography conference. You can find it on YouTube by searching "zkproof neutral atom".
Here's an interesting observation about this duo of breakthrough papers: neither Google nor Oratomic say a word about what their results mean for qday. No timelines. Zero. Nada. That is especially baffling given that the whole point of whitehat quantum cryptanalysis is to inform qday estimations and help the general public make good decisions.
So let me attempt to partially fill the silence, similarly to what Scott Aaronson did in his April 29 post. Given everything I know, including scary non-public information, I now put the odds of qday by 2032 at 50%. 10% by 2030.
Anecdotally, the US government has its own date: 2035. Originating at the NSA and later adopted by NIST, it's when branches of the US government will be disallowed from using quantum-vulnerable cryptography. In plain language: with hindsight, that date is a joke and should be discounted entirely. I don't see how NIST avoids being forced to pull it forward by years.
Part 3: post-quantum cryptography
There are good reasons to sound the alarm today, but please do not panic. Rushing carelessly towards immature post-quantum cryptography is a recipe for disaster. IMO a good target date for migration is 2029, roughly 3.5 years out. 2029 happens to be the date selected by Google, Cloudflare, and the Ethereum Foundation.
These days most of my time goes to safely migrating Ethereum towards post-quantum cryptography as part of the broader lean Ethereum effort. There's a lot to do. We need to rip out and replace BLS signatures at the consensus layer, KZG commitments at the data layer, and ECDSA signatures at the execution layer.
The plan to get there is compelling, and is based on hash-based cryptography. Within the Ethereum Foundation we've developed a Swiss army knife called leanVM (github[.]com/leanEthereum/leanVM) powered by the magic of hash-based SNARKs. Thanks to truly exceptional work by Emile, Thomas, and others, its performance is derisked. Regarding security, leanVM is a jewel, a minimal zkVM crafted for end-to-end formal verification and maximum security.
Want to help? There are two $1M initiatives. First, the Proximity Prize (proximityprize[.]org). Solve a long-standing mathematical conjecture in coding theory, improve hash-based SNARKs, and go home a millionaire. Second, the Poseidon Initiative (poseidon-initiative[.]info), offers $1M for breaking Poseidon, the SNARK-friendly hash function.
Short-term things being done to shift Ethereum toward native privacy:
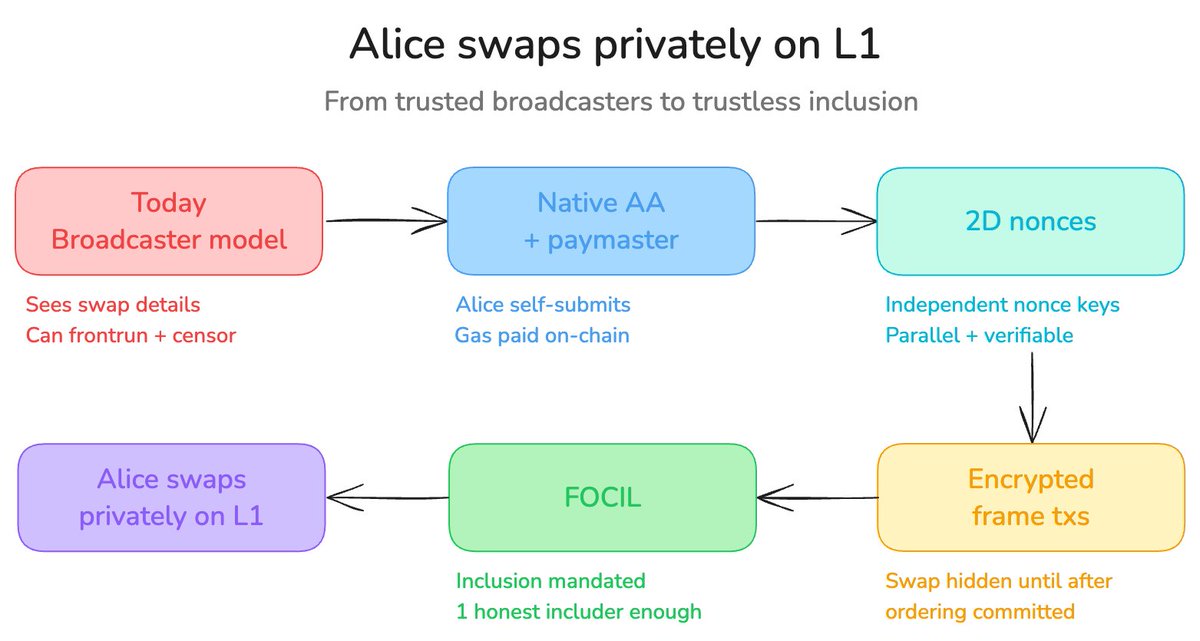
* AA + FOCIL (makes privacy protocol txs, among many other things, first-class with strong inclusion guarantees)
* Keyed nonces: https://t.co/BeTJvFhxiV
* Access-layer work (Kohaku, private reads...)
Ethereum is about to fundamentally change how blocks are executed. With the upcoming Glamsterdam hardfork, it's shipping EIP-7928: Block-level Access Lists, a proposal that brings parallelization to the EVM.
Here's a short explainer of what it is, how it works, and why it's a big deal for scaling.
Let's start from the top. Alongside EIP-7732 (ePBS), EIP-7928 is the execution-layer (EL) headliner for Glamsterdam. Like ePBS, the main focus has been scaling Ethereum, though both proposals come with a bunch of other, equally important properties on the side e.g. removing trust requirements from the PBS pipeline or improving sync.
EIP-7928 adds a Block Access List (BAL) to every Ethereum block. A BAL is a list of accounts and storage slots that the block touches, but that's not all: it also contains post-transaction state diffs (this part is critical!).
Post-transaction state diffs tell you what the state looks like after each transaction. Quick example: user A swaps 1 ETH for DAI on DEX B. The BAL tells you that user A's ETH balance decreased by 1 ETH + tx fees and their nonce went up by 1; that DEX B's ETH balance went up by 1 ETH; and that inside the DAI contract, user A's DAI balance increased while DEX B's decreased.
In other words, all of that info becomes statically available, something that previously required tracing the transaction.
Client software (Geth, Nethermind, Besu, Erigon, Reth, Ethrex, Nimbus) can use this to do a few very powerful things:
1. Parallelize transaction execution. Knowing the post-state of each tx resolves the dependencies between them. No transaction has to wait on the previous one anymore, so execution can be perfectly parallelized. Instead of large parts of block validation sitting idle waiting on sequential execution, clients can finally make much better use of modern hardware.
2. Batch prefetch. One of the most cumbersome jobs for a node has been fetching the state needed for execution from disk. Because state locations (e.g. the exact storage slot in the DAI contract where user A's balance lives) are only discovered along the way, while executing, state-fetching has been a real drag on scaling: it blocks execution, takes time, and eventually slows everything down. With BALs, everything a node needs for execution is known upfront and can be loaded into cache in one go, in parallel. This speeds things up even further.
3. Parallelize post-state root calculation. Another expensive task is walking the updated state tree to compute the post-state root, which is needed so that everyone agrees on what's on disk after executing the block. With the post-tx state already in the BAL, nodes can do this in parallel while executing. A heavy task that used to wait until all transactions had finished can now run alongside prefetching and execution.
4. Snap sync (v2). An often overlooked, less sexy aspect of blockchains is syncing. Nodes need to catch up with the chain, and they need to catch up faster than the chain progresses. Today, most nodes do snap sync: downloading blocks, headers, and state in parallel while chasing the tip, and then "healing" the database once they're close to the head. Healing means asking peers for trie nodes, receiving them, validating them, and updating the local DB. It's iterative, networking-heavy, can take a while, and especially higher throughput pushes that phase to its limits. BALs help here too: with snap v2, nodes can catch up to the tip and skip the healing phase entirely. Syncing at higher throughput becomes more robust and reliable.
So, to summarize, a BAL contains two things:
-> The state locations the block accesses
-> The state changes after each tx (incl. the new values)
We're already seeing big performance gains today: on 6-core machines, EL clients validate blocks up to 5x faster, making block gas limits of 300M a very realistic outcome. ePBS will add to that by decoupling the block from the payload, giving validators 2-4x more time for execution.
To not overshoot (security stays priority #1), the fork will likely ship with a 200M gas limit, but we shouldn't be stuck there for long before pushing to 300M and beyond. That's a 10x in scaling since we started taking the topic seriously, without touching hardware requirements.
None of this would have happened without people going all-in, heads down, shipping: so many hours spent in calls debating the right design, so many iterations refining the specs, and tons of test cases written (and still being worked on). The road from whiteboard to production-ready code has been a journey, and we're not at the finish line yet, but from what I can tell, things look super bullish for Ethereum.
Glamsterdam will be a fork that shows what's possible when a distributed, decentralized community works on a shared goal, laser-focused on providing enough block space to onboard the next wave of users.
Keyed nonces are not just a way to add stronger in-protocol support for privacy solutions. They are also a potential first foray into a new state scaling strategy for Ethereum: create new types of storage that are more optimized for handling categories of use cases that we care about, with restrictions on their use that make them usable at extreme scale while preserving the protocol's decentralization.
Let's zoom in on this case (in-protocol nullifiers). Let's say we get to 2000 TPS of privacy-preserving transactions onchain, for eight years. Then we get 2^11 tx/sec * 2^25 sec/year * 2^3 years = 2^39 [ie. 500 billion] nullifiers stored onchain (the challenge with nullifiers is that they are fundamentally not possible to prune).
It's actually far easier to keep Ethereum decentralized if we have 500 billion nullifiers onchain in a dedicated nullifier store, than if we just let them grow in the current state. The reason is that the more restrictive structure of nullifiers (only used to check validity, and we can require the nullifier ID to be explicitly specified in the tx) enables more decentralized ways of handling them. This includes:
* Sharding: each node (incl builders) can hold a small percentage of nullifiers, and make sure to have a connection to an honest peer in each other shard
* Bloom filters: see this somewhat wacky idea here for reducing the VOPS requirement for nullifiers to ~8 bits per nullifier: https://t.co/M2HgDru1NV
Both techniques are not possible to use for dynamically accessible state. And so builders would have to download the full 16 TB to become viable (not just optimal, viable!), and privacy protocol users would not be able to use FOCIL without providing a Merkle branch proving that their nullifier is unspent, and there would be very few nodes capable of providing such a branch...
Zooming back out, the moral of the story is that fully dynamic state is much harder to handle at extreme scale (tens to hundreds of TB) than state that is more controlled and restricted in how it can be used. And so if we can move the majority of usage into these more specialized forms of state (which we can make much cheaper in terms of gas), then we can keep Ethereum decentralized, and highly scalable, and keep the fully dynamic state available for applications (eg. defi) that really need its full functionality.
Did you know we open sourced a fuzzer, an AI Framework and a VS Code / Cursor Extension for Fuzzing Solidity?
- One click to scaffold
- One line command to have AI work for you
- One command to run a 10x fuzzer
All on our Github
Contrary to what you may think:
- 5 people spent 2 years working on this
- It cost 6 figures to make this happen
- E2E fuzzing is still a specialised skill because wisdom is not cheap
We’ve open sourced everything we built for you to carry on the torch
I’m doing a full breakdown this Friday at EthPrague
🔐 New EIP-8250: Keyed Nonces for Frame Transactions 🔐
by @soispoke, @nero_eth, @lightclients and @VitalikButerin
This replaces the single sender nonce with (nonce_key, nonce_seq), giving frame transactions independent replay domains.
For privacy protocols, the key can be derived from a nullifier: concurrent withdrawals from a shared sender become possible, with inclusion atomically marking the nullifier spent.
Target fork: Hegota
Links below 👇
Alice swaps privately on L1
tldr: Privacy protocol users today depend on broadcasters that can see, frontrun, and censor their transactions. In this thread we show how four future protocol upgrades can remove this dependency step by step. Native AA (EIP-8141) and 2D nonces let users self-submit with no off-chain infrastructure. Encrypted frame transactions hide swap parameters until after block ordering is committed. FOCIL guarantees inclusion as long as one honest includer can see the transaction pending in the public mempool.
👇🧵
This is an email I sent earlier today to all employees at Coinbase:
Team,
Today I’ve made the difficult decision to reduce the size of Coinbase by ~14%. I want to walk you through why we're doing this now, what it means for those affected, and how this positions us for the future.
Why now
Two forces are converging at the same time. We need to be front footed to respond to both.
First, the market. Coinbase is well-capitalized, has diversified revenue streams, and is well-positioned to weather any storm. Crypto is also on the verge of the next wave of adoption, with stablecoins, prediction markets, tokenization, and more taking off. However, our business is still volatile from quarter to quarter. While we've managed through that cyclicality many times before and come out stronger on the other side, we’re currently in a down market and need to adjust our cost structure now so that we emerge from this period leaner, faster, and more efficient for our next phase of growth.
Second, AI is changing how we work. Over the past year, I’ve watched engineers use AI to ship in days what used to take a team weeks. Non-technical teams are now shipping production code and many of our workflows are being automated. The pace of what's possible with a small, focused team has changed dramatically, and it's accelerating every day.
All of this has led us to an inflection point, not just for Coinbase, but for every company. The biggest risk now is not taking action. We are adjusting early and deliberately to rebuild Coinbase to be lean, fast, and AI-native. We need to return to the speed and focus of our startup founding, with AI at our core.
What this means
To get there, we are not just reducing headcount and cutting costs, we’re fundamentally changing how we operate: rebuilding Coinbase as an intelligence, with humans around the edge aligning it. What does this mean in practice?
- Fewer layers, faster decisions: We are flattening our org structure to 5 layers max below CEO/COO. Layers slow things down and create coordination tax. The future is small, high context teams that can move quickly. Leaders will own much more, with as many as 15+ direct reports. Fewer layers also means a leaner cost structure that is built to perform through all market cycles.
- No pure managers: Every leader at Coinbase must also be a strong and active individual contributor. Managers should be like player-coaches, getting their hands dirty alongside their teams.
- AI-native pods: We’ll be concentrating around AI-native talent who can manage fleets of agents to drive outsized impact. We’ll also be experimenting with reduced pod sizes, including “one person teams” with engineers, designers, and product managers all in one role.
In short: AI is bringing a profound shift in how companies operate, and we’re reshaping Coinbase to lead in this new era. This is a new way of working, and we need to leverage AI across every facet of our jobs.
To those who are affected
I know there are real people behind these decisions — talented colleagues who have poured themselves into this company and our mission. To those of you who will be leaving: thank you. You’ve helped build Coinbase into what it is today, and I am sincerely grateful for everything you've done.
All impacted team members will receive an email to their personal account in the next hour with more information, and an invitation to meet with an HRBP and a senior leader in your organization. Coinbase system access has been removed today. I know this feels sudden and harsh, but it is the only responsible choice given our duty to protect customer information.
To those affected, we will be providing a comprehensive package to support you through this transition. US employees will receive a minimum of 16 weeks base pay (plus 2 weeks per year worked), their next equity vest, and 6 months of COBRA. Employees on a work visa will get extra transition support. Those outside of the US will receive similar support, based on local factors and subject to any consultation requirements.
Coinbase prides itself on talent density. Our employees are among the most talented people in the world, and I have no doubt that your skills and experience will be highly sought after as you pursue your next chapters.
How we move forward
To the team that is staying, I know this is a difficult day. We’re saying goodbye to colleagues and friends you've been in the trenches with. But here’s what I want you to know as we move forward together:
Over the past 13 years, we have weathered four crypto winters, gone public, and built the most trusted platform in our industry. We’ve made it this far by making hard decisions and by always staying focused on our mission. This time will be no different – nothing has changed about the long term outlook of our company or industry. And most importantly, our mission has never been more important for the world. Increasing economic freedom requires a new financial system, and we’re building it.
The Coinbase that emerges from this will be more capable than ever to achieve our mission.
Brian
Ethereum is turning privacy into a first-class primitive.
Frame transactions (EIP-8141) + 2D nonces remove the need for intermediaries: fees can be paid from the withdrawal itself, no third party relayer or doxxed account needed anymore.
Next steps include:
- cheaper deposits/withdrawals (more throughput, cheaper proving)
- enshrined privacy at L1
More details in the ethresearch post:
https://t.co/60IlxRAEmI
Can AI write EVM bytecode + a Lean proof of solvency under arbitrary reentrancy, bypassing the compiler entirely?
Yes! In this experiment we create 86 bytes of WETH bytecode plus a sorry-free Lean solvency theorem 👇
(thread + link below)
the reth team just returned from interop preparing for the Glamsterdam hardfork
L1 scaling looking bright with ePBS, BALs, gas repricing and snap/v2
they also got to see the arctic code vault!
1/ Recently an unnamed source shared data exfiltrated from an internal North Korean payment server containing 390 accounts, chat logs, crypto transactions.
I spent long hours going through all of it, none of which has ever been publicly released.
It revealed an intricate ~$1M/month scheme of fraudulent identities, forged legal documents, and crypto-to-fiat conversion.
Enjoy the findings!
The attack was
1. North Korea figured out which RPC providers LZ was using
2. They compromised two of the providers to make them return fake data
3. DDoSed other providers to shut them down, forcing LZ to use the bad ones
AFAIK I was the only one who actually called it
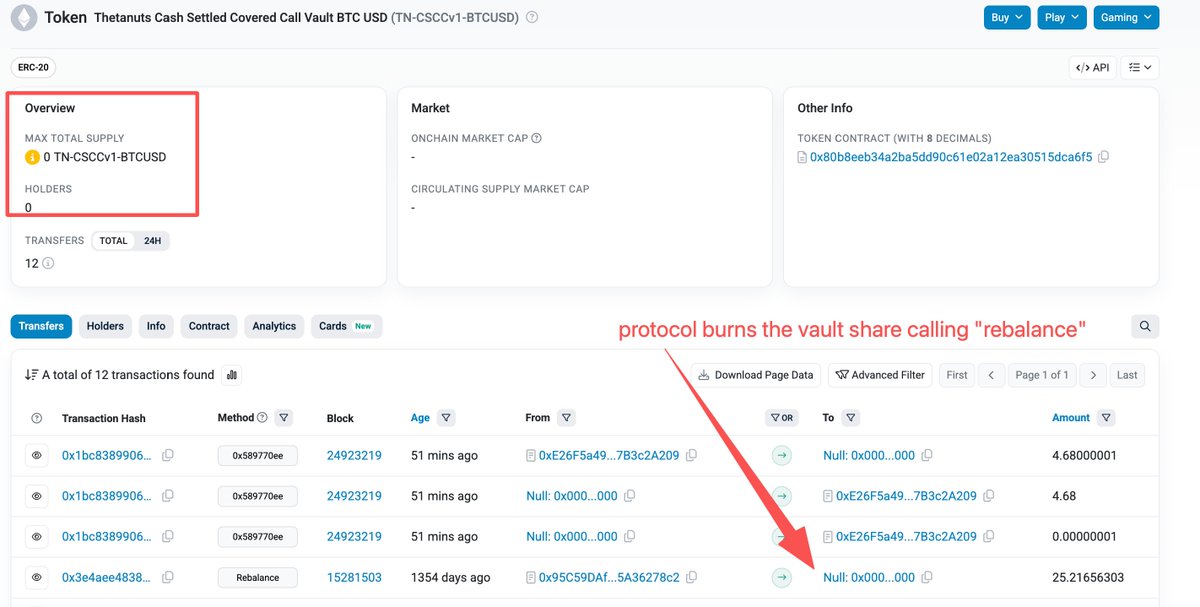
Checked the attack on @ThetanutsFi . I don't think it's an overflow.
Instead, the vault before attacker's deposit has a total supply of 0 wei.
It's simple: 0 vault share equals the total money inside the contract.
All the attacker needs to do is to deposit and then withdraw. The un-owned money is his.
So why is the total supply 0? The protocol owner called a "rebalance" function 1354 days ago to burn them...
source: https://t.co/R32SpqWxD8