@giffmana@jeremyphoward@AnthropicAI If you write non-standard spaghetti code like me, AI has tremendous difficulty debugging. They have never seen it before i.e. OOD.
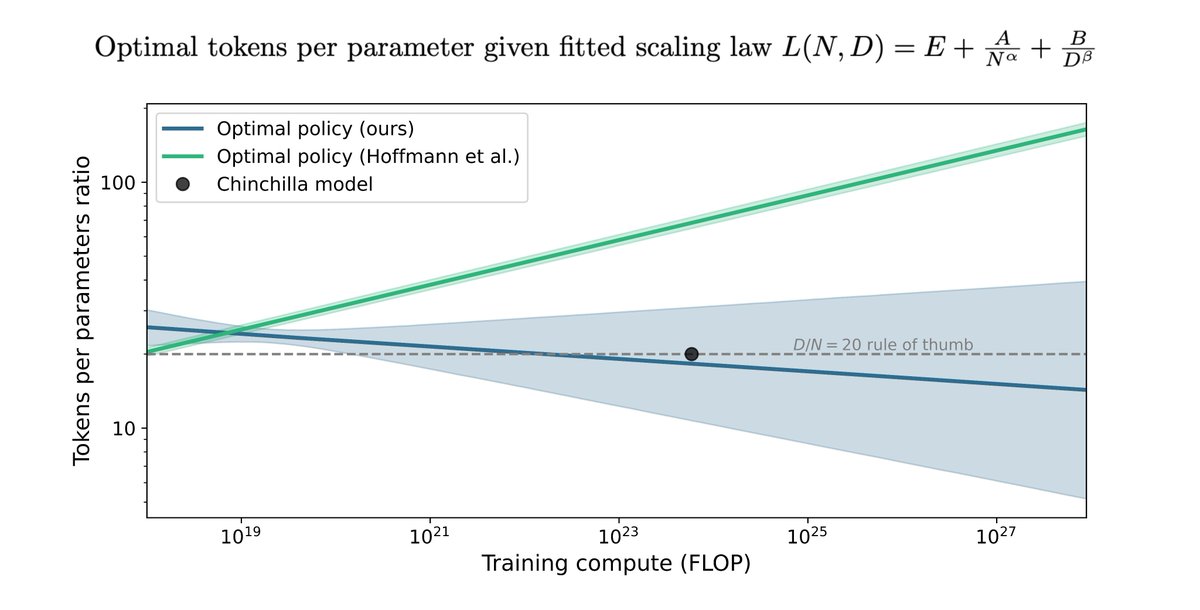
The Chinchilla scaling paper by Hoffmann et al. has been highly influential in the language modeling community. We tried to replicate a key part of their work and discovered discrepancies. Here's what we found. (1/9)
Our computer vision textbook is released!
Foundations of Computer Vision
with Antonio Torralba and Bill Freeman
https://t.co/We0ZSJzkle
It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields.
1/4
In praise of RDF
RDF is a data model, a knowledge representation system, a web standard & a data exchange format
Used to build #knowledgegraphs & #LLM-based applications
@semihsalihoglu describes its virtues, vices, history & applications
#AI#GraphDB
https://t.co/WtLK0gYnQ0
Can AI web agents 💻 hop around websites to complete complex user tasks?
We present 🌠MMInA, a multihop multimodal Internet agent benchmark, with 1050 challenging human-written web browsing tasks.
arXiv preprint: https://t.co/hxHe9ZPxy8
Project page: https://t.co/UnvE6dlvx0
CS159: LLMs for reasoning lecture slides from Caltech are really good. Link: https://t.co/cqQrAHa4Kg
Thank you for making them public @yisongyue and @acbuller
Introducing 𝐀𝐋𝐎𝐇𝐀 𝐔𝐧𝐥𝐞𝐚𝐬𝐡𝐞𝐝 🌋 - Pushing the boundaries of dexterity with low-cost robots and AI. @GoogleDeepMind
Finally got to share some videos after a few months. Robots are fully autonomous filmed in one continuous shot. Enjoy!
🚨BREAKING: The @Stanford Institute for Human-Centered AI publishes its Artificial Intelligence Index Report 2024, one of the most authoritative sources for data and insights on AI. Below are its top 10 takeaways:
1. AI beats humans on some tasks, but not on all;
2. Industry continues to dominate frontier AI research;
3. Frontier models get way more expensive;
4. The United States leads China, the EU, and the U.K. as the leading source of top AI models;
5. Robust and standardized evaluations for LLM responsibility are seriously lacking;
6. Generative AI investment skyrockets;
7. The data is in: AI makes workers more productive and leads to higher quality work;
8. Scientific progress accelerates even further, thanks to AI;
9. The number of AI regulations in the United States sharply increases;
10. People across the globe are more cognizant of AI’s potential impact—and more nervous.
➡️Read the @StanfordHAI report below.
➡️For more information on AI policy & regulation, subscribe to my newsletter (link in bio).
Along with Core, we have published a technical report detailing the training, architecture, data, and evaluation for the Reka models.
https://t.co/ROrakRAcPu
Reducing Hallucination in Structured Outputs via RAG
Nice paper by researchers at ServiceNow where they discuss how to deploy an efficient RAG system for structured output tasks.
The RAG system combines a small language model with a very small retriever. It shows that RAG can enable deploying powerful LLM-powered systems in limited-resource settings while mitigating issues like hallucination and increasing the reliability of outputs.
The paper covers the very useful enterprise application of translating natural language requirements to workflows (formatted in JSON). So much productivity can come from this task but there is a lot of optimization that can be further achieved (eg., using speculative decoding or using YAML instead of JSON).
Nothing too special in the paper but there are some great insights and practical tips on how to effectively develop RAG systems for the real world. This is my favorite kind of AI report.
🤏 Why do small Language Models underperform?
We prove empirically and theoretically that the LM head on top of language models can limit performance through the softmax bottleneck phenomenon, especially when the hidden dimension <1000.
📄Paper: https://t.co/YkdQttDDSK
(1/10)
Planning is a key agentic AI design pattern in which we use a large language model (LLM) to autonomously decide on what sequence of steps to execute to accomplish a larger task. For example, if we ask an agent to do online research on a given topic, we might use an LLM to break down the objective into smaller subtasks, such as researching specific subtopics, synthesizing findings, and compiling a report.
Many people had a “ChatGPT moment” shortly after ChatGPT was released, when they played with it and were surprised that it significantly exceeded their expectation of what AI can do. If you have not yet had a similar “AI Agentic moment,” I hope you will soon. I had one several months ago, when I presented a live demo of a research agent I had implemented that had access to various online search tools.
I had tested this agent multiple times privately, during which it consistently used a web search tool to gather information and wrote up a summary. During the live demo, though, the web search API unexpectedly returned with a rate limiting error. I thought my demo was about to fail publicly, and I dreaded what was to come next. To my surprise, the agent pivoted deftly to a Wikipedia search tool — which I had forgotten I’d given it — and completed the task using Wikipedia instead of web search.
This was an AI Agentic moment of surprise for me. I think many people who haven’t experienced such a moment yet will do so in the coming months. It’s a beautiful thing when you see an agent autonomously decide to do things in ways that you had not anticipated, and succeed as a result!
Many tasks can’t be done in a single step or with a single tool invocation, but an agent can decide what steps to take. For example, to simplify an example from the HuggingGPT paper (cited below), if you want an agent to consider a picture of a boy and draw a picture of a girl in the same pose, the task might be decomposed into two distinct steps: (i) detect the pose in the picture of the boy and (ii) render a picture of a girl in the detected pose. An LLM might be fine-tuned or prompted (with few-shot prompting) to specify a plan by outputting a string like "{tool: pose-detection, input: image.jpg, output: temp1 } {tool: pose-to-image, input: temp1, output: final.jpg}".
This structured output, which specifies two steps to take, then triggers software to invoke a pose detection tool followed by a pose-to-image tool to complete the task. (This example is for illustrative purposes only; HuggingGPT uses a different format.)
Admittedly, many agentic workflows do not need planning. For example, you might have an agent reflect on, and improve, its output a fixed number of times. In this case, the sequence of steps the agent takes is fixed and deterministic. But for complex tasks in which you aren’t able to specify a decomposition of the task into a set of steps ahead of time, Planning allows the agent to decide dynamically what steps to take.
On one hand, Planning is a very powerful capability; on the other, it leads to less predictable results. In my experience, while I can get the agentic design patterns of Reflection and Tool use to work reliably and improve my applications’ performance, Planning is a less mature technology, and I find it hard to predict in advance what it will do. But the field continues to evolve rapidly, and I'm confident that Planning abilities will improve quickly.
If you’re interested in learning more about Planning with LLMs, I recommend:
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Wei et al. (2022)
- HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, Shen et al. (2023)
- Understanding the planning of LLM agents: A survey, by Huang et al. (2024)
[Original text: https://t.co/pWmIR9wEki ]
Highly amusing update, ~18 hours later:
llm.c is now down to 26.2ms/iteration, exactly matching PyTorch (tf32 forward pass). We discovered a bug where we incorrectly called cuBLAS in fp32 mathmode 🤦♂️. And ademeure contributed a more optimized softmax kernel for very long rows (50,257 elements per row, in the last logits layer).
But the fun doesn’t stop because we still have a lot of tricks up the sleeve. Our attention kernel is naive attention, not flash attention, and materializes the (very large) preattention and postattention matrices of sizes (B, NH, T, T), also it makes unnecessary round-trips with yet-unfused GeLU non-linearities and permute/unpermute inside our attention. And we haven’t reached for more optimizations, e.g. CUDA Graphs, lossless compressible memory (?), etc.
So the updated chart looks bullish :D, and training LLMs faster than PyTorch with only ~2,000 lines of C code feels within reach. Backward pass let’s go.
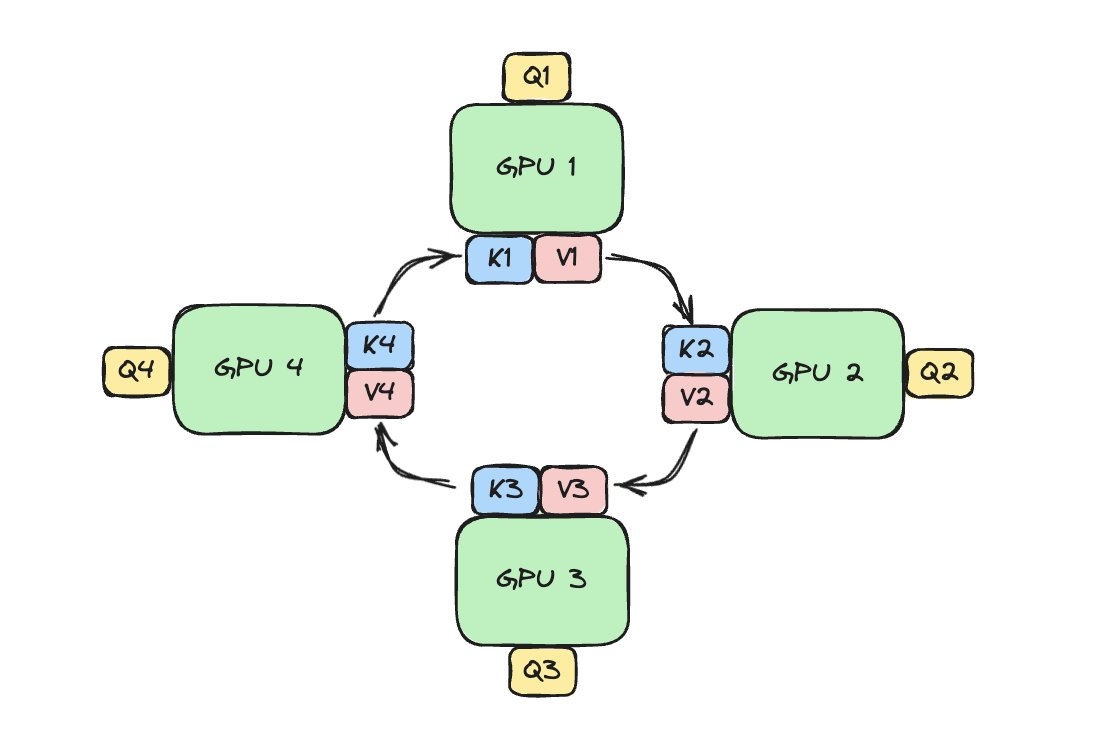
How do LLMs scale to million token context window? Ring Attention is a nice trick to parallelize long sequence across devices and rotate them in a ring with zero overhead scaling.
In our new blog, we cover the tricks behind this magic. It looks like this (1/5🧵)
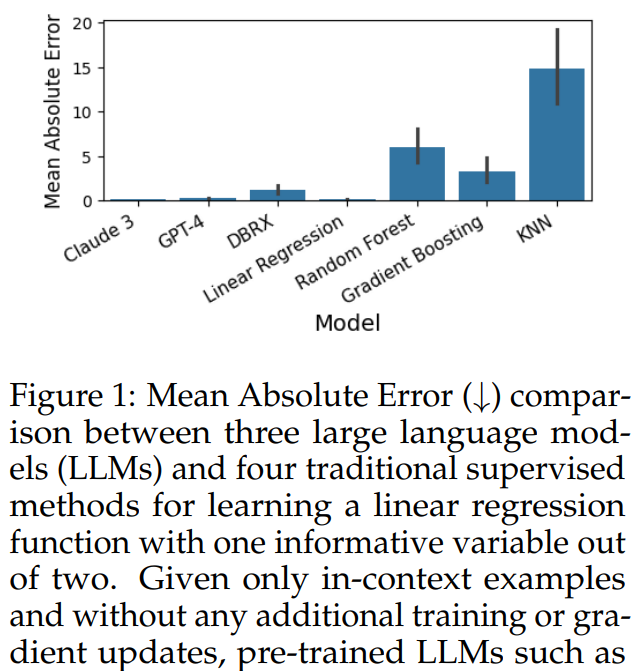
From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
Several LLMs (e.g., GPT-4) perform on par w/ supervised methods like Random Forest on regression
repo:https://t.co/ONrEZT0Ips
abs: https://t.co/lgmtzkF6Tm
Very interesting papers @ZeyuanAllenZhu . This trick is very interesting. I recall hearing evidence OpenAI does label training data with source/provenance (the LLM sometimes spits out those memorized labels). Can't remember where/who I learnt this from