Codex 5.5 use cases I found so far:
> made my internet faster
> made my local 6B SLM 3x faster
> made my macbook pro faster like new
> made a lightweight suite to write & test metal kernals
> made a skill to communicate with claude code in realtime
> made a pipeline to generate SFT dataset using Deepseek v4
> made a computer use workflow to fine tune models in Google Colab
> made 4 routines to test workflows on autopilot 3 times/day
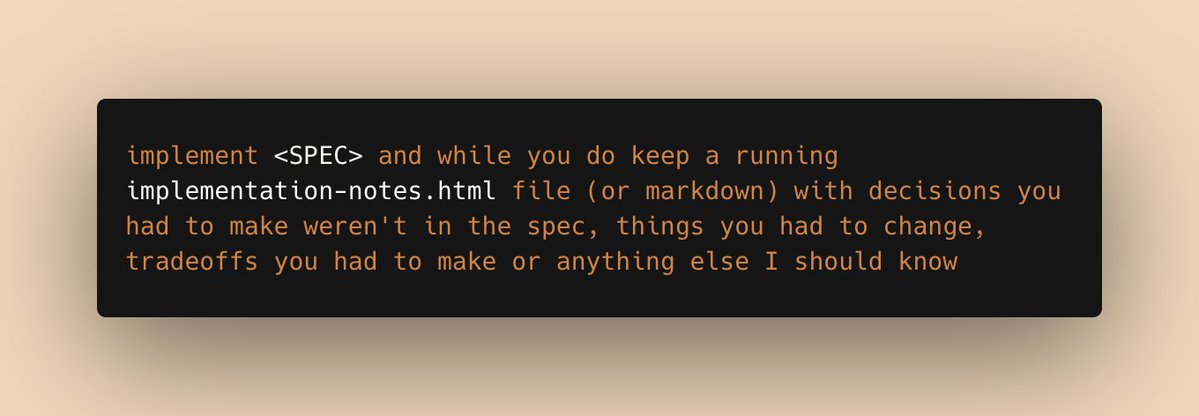
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
Here's the first of five NVFP4 optimized benchmark. It's a crowd favorite that saw HUGE benefit from the CUTLASS back end! If you're using @NVIDIAAI Blackwell GPUs or a GB10 (DGX Spark or equivalent) this is for you!
TLDR: 57.49 tok/s single stream on fully native architecture!
Dear @UnslothAI
My @NVIDIAAI GB10 (DGX Spark) absolutely loved your quantization of this model!
unsloth/Qwen3.6-35B-A3B-NVFP4
It ran stably up to concurrency 64, not optimal but I did that for no other reason than to see if it would 😂
🧵
i've run a stack of models across a single 3090, a 5090, and a 128GB DGX Spark. exactly three are worth building on. the honest list.
the three worth it:
> 1. StepFun Step-3.5 Flash, the REAP pruned 121B MoE (Q6, DGX Spark) a 121 billion parameter mixture of experts running on a single desktop box. the most worth-it model in everything i've tested.
> 2. Qwen 3.6 27B Dense, Q4 (single RTX 3090) the undisputed king of the 24GB tier. one shot a playable game, around 41 tok/s, fits with context headroom to spare. one 24GB card, this is your answer.
> 3. NVIDIA Nemotron 3 Nano Omni, 30B-A3B (DGX Spark) the best multimodal i've tested for video classification work. vision in, runs clean on the Spark.
the rest, ran them, they hold up fine:
on the Spark: DeepSeek V4 Flash 158B,
GLM 4.7 Flash, GLM 4.5 Air REAP 82B-A12B, Gemma 4 26B-A4B, Qwen3-VL 235B-A22B, Qwen3 Coder 30B-A3B, Qwen3 30B-A3B, Carnice 35B-A3B.
on consumer GPUs:
Kimi K2.5 1T, Qwen3-Coder-Next 80B, Hermes 4.3 36B, Qwen 3.5 27B Dense.
single 3090 to a 128GB Spark, that's the range. the three up top are the ones worth your hardware today.
Atlas is open source!
An inference engine written from scratch in Rust + CUDA. No PyTorch, no Python, no 200-dependency install dance. <2 min cold start, BUILT for GB10
Qwen3.6-35B at 130 tok/s on a single DGX Spark.
Demo powered by @Gradio
🧵 https://t.co/vxZLwBJMub
Made this for everyone who is working with a @NVIDIAAI DGX Spark (GB10) ⚡️
Definitely also bookmark the official site, it's a fabulous resource with playbooks for nearly everything you'd want to see!
https://t.co/uAxkSvIbWG
Andrej Karpathy: "90% of your AI coding bill is paying for context you didn't need to send"
Here are 10 things senior AI engineers stopped wasting tokens on:
1. Auto-context loading 50 files for a 30-line fix: $1.20/turn for tokens you'll never read. 80% input waste, every session
2. Running Opus on lint, format, and rename tasks: $0.60 for what Haiku nails at $0.02. 30x overpay on the cleanup tier
3. Tool call loops that re-send the full repo on every retry: 5x context cost per agentic flow. fixing these alone cuts 30-50% of bills
4. Sonnet as the default model: Kimi 2.6 matches its quality on most coding tasks at 1/6 the cost. defaulting to Sonnet in 2026 is leaving 60-70% on the table
5. Streaming responses on stable-prefix workflows: kills your prompt cache. you pay 10x for tokens that should have cost cents
6. "Just in case" file includes: 80,000-token prompts that should be 3,000. context bloat is the silent budget killer
7. Per-session knowledge rebuilding: 10 min writing a SKILL.md once vs paying agents to re-figure out your environment every run. $4 vs $0.30 per execution
8. Single-model setups: premium tier on every task is the most expensive mistake in AI coding right now
9. Asking 10 small questions one at a time: 10 separate input prefix charges vs one batched call. 70-90% savings on routine workflows
10. Buying Claude Pro + ChatGPT Plus + Cursor Pro: you seriously use one. the other two are habit, not utility
what actually compounds instead:
- context discipline (grep before fetching, always)
- prompt caching on every stable prefix
- multi-model routing (Kimi 2.6 default, Opus for the 10%)
- graduated skills via SKILL.md files
- profiling tool calls before optimizing prompts
- the routing mindset (right model for right task)
in 12 months, the gap between developers shipping on $200/month and $4,000/month budgets won't be skill
it'll be how well they route
study this.
Whole day with Pi agent just used 10% of my $20 Codex weekly quota
All gpt 5.5, various thinking levels
I'm now 3 hours away from weekly reset and still have 42% left!
For my typical 4-6h/day session:
Codex Desktop - 20-30% a day, 1-2 days/week
Pi - 10% a day, 4-5 days/week?
My switch to Pi is really looking good so far
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.