This is one of the papers I'm quite excited about in the past few weeks. It's a very simple but practical modification to the DINOv3 training framework.
Let me explain how it works.
🛰️ Introducing UniverSat: one transformer backbone for Earth Observation that handles ANY sensor, ANY spatial, spectral & temporal resolution, ANY scale — with a single set of weights. 🌍
🎰 Welcome to the FID Lottery.
We pulled the lever 25 times on the same machine. Identical diffusion model, identical ImageNet class-cond recipe, only the seed changed. The house paid out anywhere from 33.59 to 35.69 FID.
A 2.1-point spread, pure luck. Step onto the floor 👇🧵
We explored the impact of variability sources in generative modeling.
Turns out, we've been neglecting the error bars associated with training variability all along!
We should aim to report results that we are sure of their scientific validity, instead of seed engineering!
Check out our latest work! 🚀
We learn a global state and decode the point cloud pointwise, allowing to decode as many points as you want.
Plus, we introduce some clever guidance tricks to ensure global consistency, yielding high-quality meshes from just a few views! 👇
What if you could turn any number of photos (3, 8, 15, or even 60) into one clean 3D surface (pts & mesh) with Flow Matching?
Check out our new work, Surflo: Consistent 3D Surface Flow Model with Global State. 🧵
1/n
🔗https://t.co/lBcJRgpfdg
Very excited to share our new paper, accepted at ICDAR 2026: "Leveraging Morphology for Historical Script Metrological Analysis"! 📜We present a method to automatically extract high-quality character prototypes and compute stable paleographic measurements:
https://t.co/fXPF4SFjT8
@LiangZheng_06@DavidSHolz Nice to see reproducible t2i research! From a somewhat biased view, I feel we actually don't need to move away from imagenet, (if repr. is the goal: 10 years of research have proved it leads to better models) we just need to caption it! Check our paper: https://t.co/QV6RXoQIXR
I think this is my favorite paper this CVPR: Magician.
before they explore in active view selection, they imagine how gaussians and occupancy map would look like and then compute a coverage metric based on that.
during planning, they try 10 views like that in 10 steps in a tree search with pruning and get planning for free.
they even have real-world experiments with a drone and a toy car.
how are they not an award candidate, it blows my mind.
📢 New preprint! We introduce R3DPA - a LiDAR scene generator that:
• Transfers RGB-pretrained generative priors to 3D
• Aligns with self-supervised LiDAR features
• Enables object inpainting & scene mixing at inference
• Sets SOTA on KITTI-360
Come see our poster tomorrow afternoon at #ICRA2026 to talk about 3D representation alignment of diffusion models for LiDAR generation.
📍196, Hall C
🗓️ Wednesday, 3:00-4:30 PM
Presenting "PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer" tomorrow at #CVPR2026!
⏰ 7:00 AM (Perfect if you're jetlagged & awake early!)
📍 Poster #246
We propose a linear-complexity alternative to attention—come see how it performs across tasks!
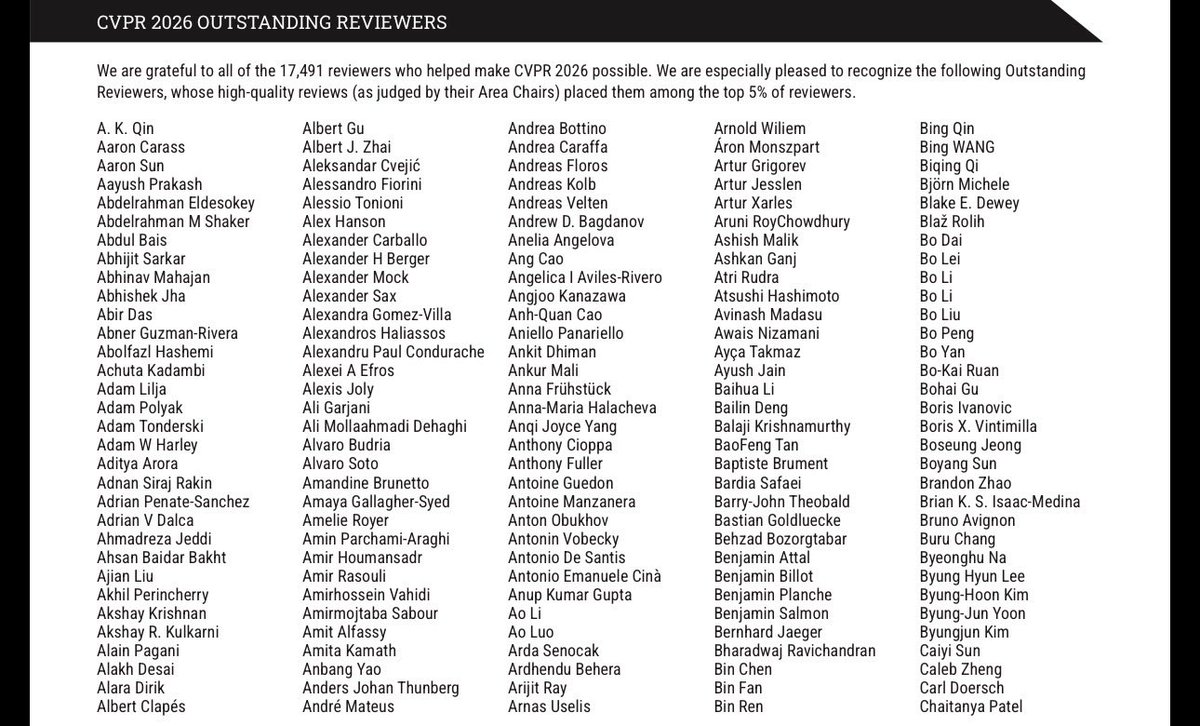
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
1/ Introducing GPIC: a Giant Permissive Image Corpus and benchmark for visual generation!
🚀100M VLM-captioned image-text pairs for training
📊1M image-text pairs for benchmarking
🖼️~28 trillion pixels
🤗Centrally Hosted
✅Fully permissive for research + commercial use
Dataset, benchmark and models🧵👇
Co-led with @KyleSargentAI
CVPR@Paris 2026 🇫🇷 — June 1st, co-organised by ELLIS Unit Paris. A one-day local event ahead of CVPR, open to all. Oral & poster sessions for CVPR 2026, CVPR workshops & ICLR 2026 papers.
🔗 https://t.co/kZvllw2GGM
🎉 Our work MIRO is accepted to #ICML2026@icmlconf
We integrate human preferences directly during pretraining with multi-reward conditioning.
⚡MIRO is 19x faster than baselines and 370x cheaper at inference!
🤗 Try out the models: https://t.co/njNjtpG6Up
See you in Seoul!