My preprint "Conversation Routines: A Prompt Engineering Framework for Task-Oriented Dialog Systems" now has a revised version on @arXiv with updated experimental results. Here’s a thread with the changes! 🧵
➡️ Paper: https://t.co/8kMIiB5zbu
1/ What’s CR?
The workshop given by @Samuelcolvin at @AIdotengineer in London is now on Youtube. It covers evals, prompt optimization with GEPA, and live updates via Logfire managed variables.
87% accuracy with a naive prompt. 96.7% after optimization.
https://t.co/21o6iscjiO
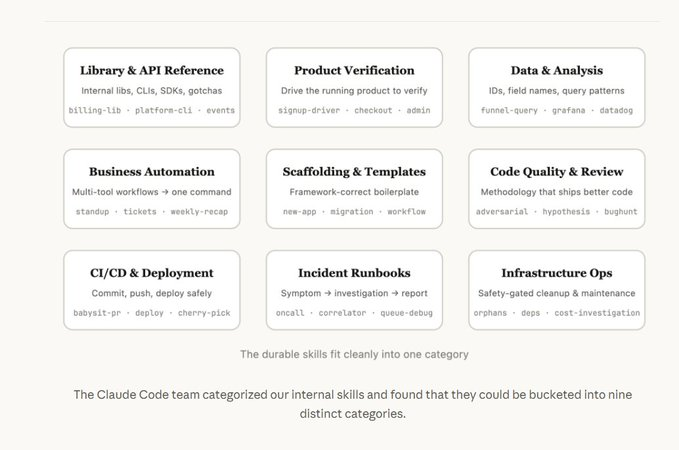
One of the best takeaways from Anthropic's "Lessons from Building Claude Code: How We Use Skills":
Good Skills aren't longer. They're clearer.
A Skill isn't just a prompt. It's a reusable work package that can include docs, scripts, templates, configs, checklists, and team-specific knowledge.
The most valuable Skills don't repeat what the model already knows. They capture what only your team knows:
Internal workflows
Deployment gotchas
Validation steps
System quirks
Hard-earned lessons
Another key point: keep Skills small and focused.
A Skill for API usage. A Skill for incident response. A Skill for code review. A Skill for deployment validation.
Especially validation Skills. They don't just tell AI what to do—they teach it how to verify the result is actually correct.
The future of AI agents isn't just better models.
It's better tools, memory, context organization, and workflow design around those models.
I had a conversation Mario about electrical engineering, Pi, and parenting. Very grateful to get another chance to chat with one of my favorite builders and people.
Enjoy (:
Stop hunting AI agent skills one GitHub repo at a time.
https://t.co/1dbRWvrcfX is a public directory and crawler for curated AI Agent Skills across Claude Code, Cursor, OpenClaw, and similar coding tools.
It helps you find installable skills faster by pulling ranked data from https://t.co/Gn7cNkVWhS, caching SKILL.md metadata, and turning it into search/feed files you can browse or reuse.
Key features:
• Search/install/copy flow – the web app is built around finding a skill, installing it, copying it, and sharing it
• https://t.co/WfV4Q7gUbz leaderboards – uses all-time, trending, and hot rankings as the current provider
• SKILL.md enrichment – fetches common skill paths from GitHub and extracts descriptions when available
• Reusable data outputs – generates skills.json, skills_index.json, feed.json, and RSS XML
• Manual additions – lets you add skills that are not tracked by a provider and keeps them deduplicated
It’s open-source (MIT license).
Link in the reply 👇
recommended reading. i really like the durability aspect of dynamic workflows. looked into how it's implemented, and while there are some minor footguns, it's smart!
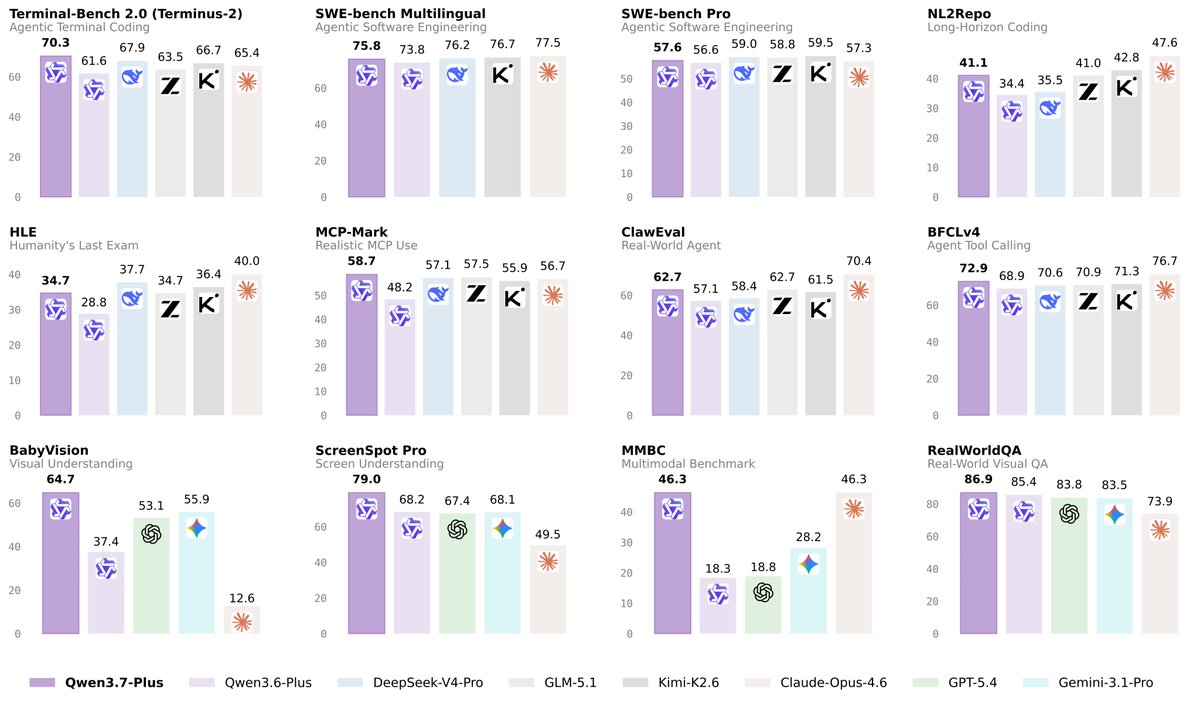
Qwen 3.7-Plus is available on Qwen Cloud Now!
Qwen 3.7-Plus is a multimodal agent model that unifies vision and language into one versatile agent foundation. ✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅Versatile coding agent & productivity assistant with full-modality input
✅Cross-harness generalization across diverse agent frameworks One model. Sees, thinks, codes, acts.
Now, come to Qwen Cloud to try, and make your agent use this model !
https://t.co/B3fnXvANF5
When the creator of Redis starts thinking about KV cache, pay attention.
antirez is Salvatore Sanfilippo, the Sicilian programmer best known for creating Redis.
But “creator of Redis” is almost too small a label.
Before Redis, he was already an old-school systems hacker. He built hping, worked in network security, and invented the idle scan technique. This was the packet-level, C-programming, Unix-hacker world.
Then Redis happened.
The origin was not glamorous. He was building LLOOGG, a real-time web analytics service, and needed something faster and simpler than the tools he had. So he created Redis.
That is very antirez.
Start with a real bottleneck.
Avoid unnecessary abstraction.
Expose the right primitive.
Make it fast enough that people rethink the category.
Redis did not win because it looked like a traditional database. It won because it gave developers direct access to useful data structures: strings, lists, hashes, sets, sorted sets, streams, pub/sub.
It made memory programmable.
That is why his return to local AI is so interesting.
With ds4, or DwarfStar 4, antirez is not just building “another local inference engine.”
He is asking a very Redis-like question:
What is the real primitive here?
For LLMs, one answer is obvious: KV cache.
Most people treat KV cache as an implementation detail. It lives in RAM or HBM, grows with context, and quietly becomes the bottleneck.
antirez looks at DeepSeek V4 Flash, compressed KV cache, modern MacBook SSDs, and says: maybe KV cache should not only live in RAM.
His phrase is perfect:
“The KV cache is actually a first-class disk citizen.”
That one sentence is the whole story.
If Redis made in-memory data structures feel like application infrastructure, ds4 is exploring whether local LLM state can become durable infrastructure too.
Prefill once.
Persist the cache.
Resume later.
Let long-running agents reuse expensive context instead of rebuilding everything from scratch.
This matters because coding agents are not normal chatbots.
They carry huge system prompts, tool definitions, repo context, prior steps, and long task histories. If every request has to resend and recompute the entire conversation, local inference will always feel fragile and wasteful.
ds4 attacks that directly.
It is a deliberately narrow engine for DeepSeek V4 Flash, focused on Metal and CUDA, high-end personal machines, special quantization, long context, HTTP API, GGUF files crafted for the engine, official-logit validation, and agent integration.
There is also a funny and very current detail: he openly says ds4 was built with strong assistance from GPT 5.5, with humans leading ideas, testing, and debugging.
That is very 2026.
A legendary C programmer using an AI coding partner to build a local AI engine, so other coding agents can run locally with persistent KV state.
It sounds recursive because it is.
And he still has the same builder energy. After ds4 took off, he wrote that the first week felt like early Redis again, with 14-hour workdays, chaos, and excitement.
That is the part I like most: a true old-school builder.
COLLEAGUE.SKILL turns chat logs into portable AI agent skills
Distill a colleague, partner, or public figure into a versioned skill package that captures their thinking style and voice. 18.5k GitHub stars and 215 community skills.
Microsoft just released a long-horizon memory benchmark on Hugging Face
It tests AI assistants on realistic, evolving personas across emails, attachments, and conversations
1,305 QA pairs pushing multi-hop reasoning and hallucination detection
You can now turn any technical book or document into a Claude Code skill 🤯
Dumping the raw PDF into Claude costs ~200K tokens before you ask a single question. book-to-skill compiles the book once, then loads only the chapter you need.
→ Per-chapter summaries pulled from the source
→ Glossary + cheatsheet of named frameworks
→ Docling keeps tables, formulas, and code as markdown
100% Open Source.
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
Imagine an AI copilot in your DAW that writes & edits MIDI from plain‑language conversations. 🎵
I wrote up some practical experiments and a vision for connecting local LLMs + agentic skills to our DAWs. Read the post here 👇
https://t.co/tBTAxIIJJP
Exploring an agentic harness (😍 https://t.co/NvvvaHhP3p) as an assistant for composing music inside a DAW (e.g., 🥰 #REAPER).
Local LLMs may be enough to reason about NEW composition approaches while retaining a solid “memory” of classical music knowledge.
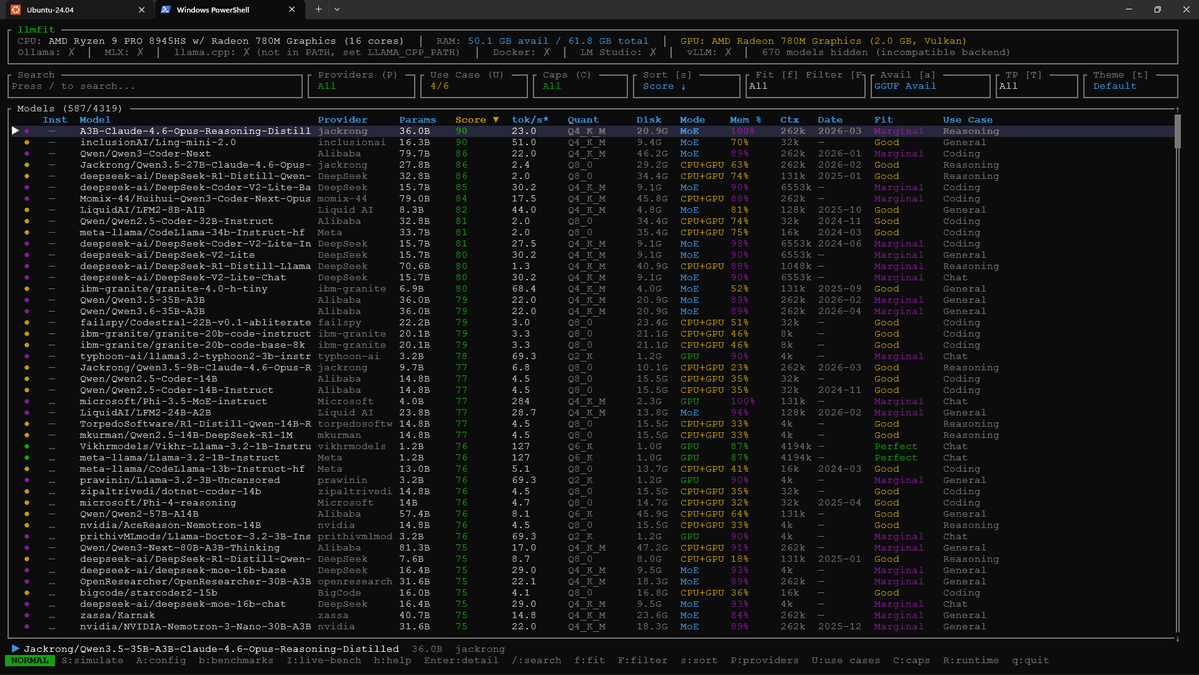
Impressive list of local LLMs that llmfit (pip install) thinks I can run on my minipc!
Which model(s) would you recommend for using https://t.co/1LYNmJiCIX as a music composition copilot—covering composition, orchestration, music skill building, and DAW #REAPER control?
Exploring an agentic harness (😍 https://t.co/NvvvaHhP3p) as an assistant for composing music inside a DAW (e.g., 🥰 #REAPER).
Local LLMs may be enough to reason about NEW composition approaches while retaining a solid “memory” of classical music knowledge.
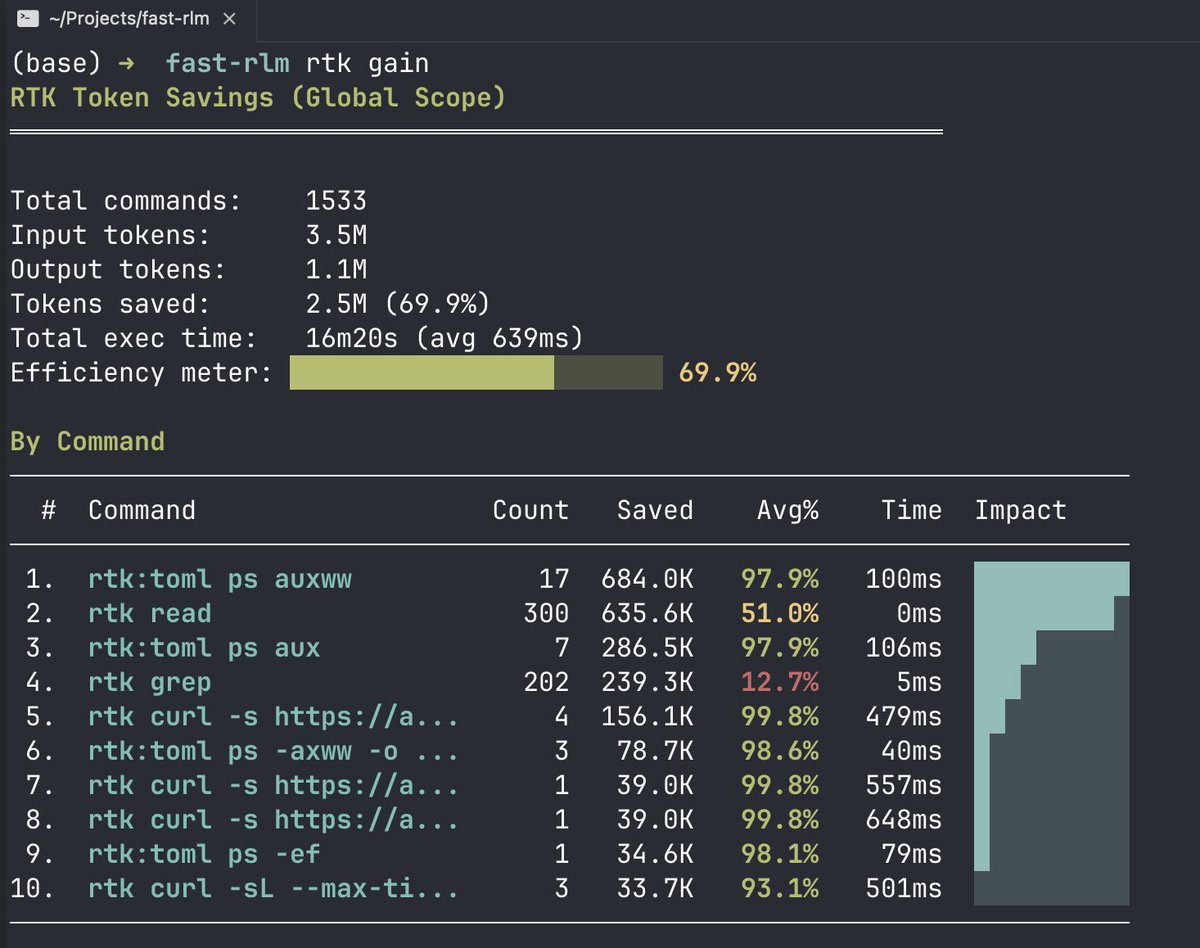
The rtk library has saved 2.5M tokens across all my coding agents... in about 2 weeks!
It's a library/skill teaches the LLMs to use rtk to run shell commands. The shell output gets filtered, grouped, truncated.
Agents see compacted terminal outs -> less token consumption
Keye VL 2.0-30B-A3B 🔥 New multimodal model from @KwaiKeye
✨ 30B/3B active - Apache 2.0
✨ 256K context via DeepSeek Sparse Attention (probably the first model to ship this in production?👀)
✨ Gets MORE accurate as you feed it more frames
✨ Matchs Qwen3 VL and Gemini 3 Flash on benchmarks
Which local models can actually handle tool calling?
I built a framework to find out.
15 scenarios. 12 tools. Mocked responses. Temperature 0. No cherry-picking.
Tested every Qwen3.5 size from 0.8B to 397B, and since some of you asked after the distillation tests: yes, I included Jackrong's Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled too.
Only two models went all green: the 27B dense and the distilled 27B.
The 397B? Failed two tests. The 122B? Failed one. The 35B? Failed two.
The timed-out results — mostly on the smaller models, are cases where the model got stuck in a loop, repeating the same tool call until it hit the 30-second limit.
The test that exposed the most models: "Search for Iceland's population, then calculate 2% of it." Simple, but 35B, 122B, and 397B all used a rounded number from memory instead of the actual search result. They didn't trust their own tool output.
Small models hallucinate data.
Big models ignore data.
The 27B just threaded it through.