🚨 The reason this is bigger than Decentralized Training JUST Got BIGGER is the Architectural Choice. THE most powerful moat in all of AI is the training cluster $TAO's SN1, SN9, SN13.
Ask yourself this: if GPUs worldwide can be aggregated into frontier training capacity at a fraction of the cost then the defining bottleneck of the AI age stops being WHO CAN AFFORD A DATACENTER and becomes WHO CAN COORDINATE THE CROWD (blockchain & AI)
A 100-billion-parameter model was just pre-trained across single GPUs scattered around the open internet. No datacenter.
The thing every expert said was impossible just happened, and almost nobody grasps what it unlocks.
Macrocosmos @MacrocosmosAI launched Project Orion Orion-100B, an early pre-training run of a:
• 100B-parameter model
• Llama-3.2 architecture
• 90 transformer blocks
• Sharded across 16 pipeline stages
• One A100 per stage
• 3 replicas
• Globally distributed hardware
It hit 30% Model FLOP Utilization and roughly 65% of full datacenter training speed on commodity GPUs costing a fraction of a cluster.
Every other decentralized-training effort INTELLECT-1, EVEN Covenant-72B, Psyche took the DATA PARALLEL route: Every peer must hold the entire model.
That works, but it has a hard ceiling the biggest model you can train is capped by the SMALLEST machine you require.
Covenant needs 8×B200 per peer ($50/hr). "Permissionless" on paper; almost nobody can actually join. And data-parallelism only SPEEDS-UP training you could already do it doesn't unlock training you otherwise couldn't.
IOTA did the hard thing instead.
It splits the MODEL ITSELF across peers each one holds as little as a single transformer block, contributes one commodity GPU, and the network stitches them into one larger machine. (A leading researcher last October called this LIKE FIGHTING GRAVITY and walked out. They built it anyway, in under a year.)
Sit with this because it is the whole thing.
In traditional data-parallel training, capacity is capped by the biggest machine in the room.
In IOTA’s pipeline-parallel world, capacity scales with the SIZE OF THE NETWORK
Add more peers.
Train a bigger model.
No single GPU sets the ceiling.
That is A MASSIVE breakthrough.
The largest models in the world become trainable by a CROWD of ordinary GPUs eventually, consumer hardware.
Orion-100B was trained across the open internet using globally distributed GPUs, hitting up to 65% of datacenter training efficiency on hardware costing a fraction of the price.
That does not happen by accident.
It required real engineering:
• ResBM for lossless activation compression.
• A custom fault-tolerant P2P protocol for unreliable nodes.
• Distributed synchronization that keeps replicas tracking together.
The biggest moat in AI is the training cluster.
Hundreds of billions in capex.
Massive datacenters.
Only a few companies able to play.
That is the wall keeping frontier intelligence centralized.
IOTA is putting the first serious crack in it.
If underutilized GPUs around the world can be coordinated into frontier training capacity, then the bottleneck is no longer who can afford the datacenter.
It becomes who can coordinate the crowd.
That changes everything.
And this is not a one-off.
Macrocosmos is building the full TRULY OPEN AI stack on Bittensor:
@IOTA_SN9 for distributed pre-training.
@Apex_SN1 for post-training and competitions.
@Data_SN13 for real-time open data.
Pre-training.
Post-training.
Data.
The three things frontier labs keep locked behind closed doors are being rebuilt in the open, owned by a network, and paid for in $TAO.
The bear case said decentralized training was fighting gravity.
The bull case just trained 100B parameters across the open internet at 65% of datacenter speed.
If they are right, the most expensive moat in AI does not get crossed.
It gets dissolved, folks.
The floor of who gets to build intelligence just dropped through the basement.
$TAO
DYOR.
This is amazing to see!
It proves a major shift has taken place: a non technical person can participate in an AI agent swarm to optimise an algorithm
Imagine that at global scale, pointed at thousands of problems at once!
It introduces one question though: who pays for the compute?
Donations/philanthropy can only go far.
For this to work at a global scale it has to become an industry, where people move from donating spare compute to doing it full time because they get paid for it.
And it all HAS to stay open, if each agent in a swarm can see and build off each other's work, no private lab can keep up with it!
This is how you can scale from people donating their laptop overnight to teams building entire data centers to join swarms.
And that is exactly what TIG has spent three years building.
What are the ingredients you need?
You need:
Price discovery (which TIG solves via proof of work)
AND
A mechanism to capture value (which TIG solves via its dual licence)
A deeper dive as these are often parts of TIG which are hard to grasp
How the price discovery work:
- Algorithms currently have no way of being priced, so what TIG does is let anyone "run" (benchmark) them.
- Benchmarkers choose the best ones because they get paid for valid work, and a better algorithm lets them produce more of it per unit of compute, so picking the best one directly earns them more.
- The algorithms benchmarkers actually choose to run is the price signal.
- Adoption is the market revealing which algorithm is best.
- This is the same class of fix Paul Milgrom won a Nobel prize for: using computation to make a market function where it otherwise cannot.
How the dual licence works
- TIG licences the winning algorithms.
- The algorithm is free to use if you share your data, but companies that want to keep their data closed pay to license it.
- 100% of that revenue flows back into the token and that flows back to the benchmarkers and innovators to fund more open innovation
We've posted this before - but if there is one video your're gonna watch to understand how this space plays out, make it this!
Just orchestrated a 128 node permissionless decentralized training run, in 5 minutes, for 5 TAO, via @IOTA_SN9
They can do this up to 100B param models.
Unbelievable.
https://t.co/hJGZ6O5NrU
What if the bacteria that cause severe disease could be redesigned to save lives? 🦠
Synthetic biology makes this possible by engineering living organisms to perform useful tasks, from producing medicines to detecting disease. 🧪
This has led to major medical breakthroughs, including the large-scale production of life-saving treatments such as insulin. 💊
At NIOME, we help accelerate this innovation by simulating scalable synthetic human genomes with realistic genetic variants, enabling high-quality research without the privacy or ethical concerns of real patient data. 🧬
Check out today’s poster to learn more, or explore NIOME here: https://t.co/Vmho9gxN1T
Ditto MCP is free Adderall for AI Agents.
1. Maximized Agent Memory
2. Shared Agent Memory
3. Auto Backup Files
You will objectively accomplish more with Claude / Codex / Hermes if you connect the Ditto MCP.
See it for yourself 👇
We’re excited to announce the next stage of our subnet: an automated post-training pipeline that will enable us to build the best product for AI shopping.
It’s only been 50 days, but we’re now getting 20k high-quality trajectories per day that are rich training signals for online shopping tasks.
Using the trajectories we have thus far, we saw an 18% → 42% climb on Qwen3-4B base using our post-training pipeline.
New Episode of 'Pulse' 🎙️
The Urgent Need for Computational Thinking in Al World
The real danger isn't AI. It's the failure to adapt. ⚠️
Technology is evolving at a pace we've never seen before, and standing still is no longer an option. 🚀
The challenge isn't simply teaching well. It's making sure we're teaching the right things for the world students are about to enter. 🌎
Check out this week’s episode featuring Conrad Wolfram, CEO of Wolfram, as we explore the urgent need for computational literacy and why education must evolve for the AI era:
Spotify: https://t.co/h8CrMQi15k
Youtube: https://t.co/LJg8cPjigN
Amazon: https://t.co/k2AyRpAZpz
Apple: https://t.co/FnbugSwVZs
🌪️ @tigfoundation is becoming the universal SOTA verification engine for algorithm discovery.🌪️
The question is: why do SkyDiscover, CodeEvolve, OpenEvolve, and every open source or private AI-driven R&D lab, need $TIG?
Private labs spend months verifying their own work. Scientists. Manual checks. Re-running experiments.
TIG verifies through OPoW mining. Benchmarkers put computing weight on the best algorithm. Miners are incentivized to find the most efficient ones.
Adoption is the signal. No committee. No trust. Just weighted consensus.
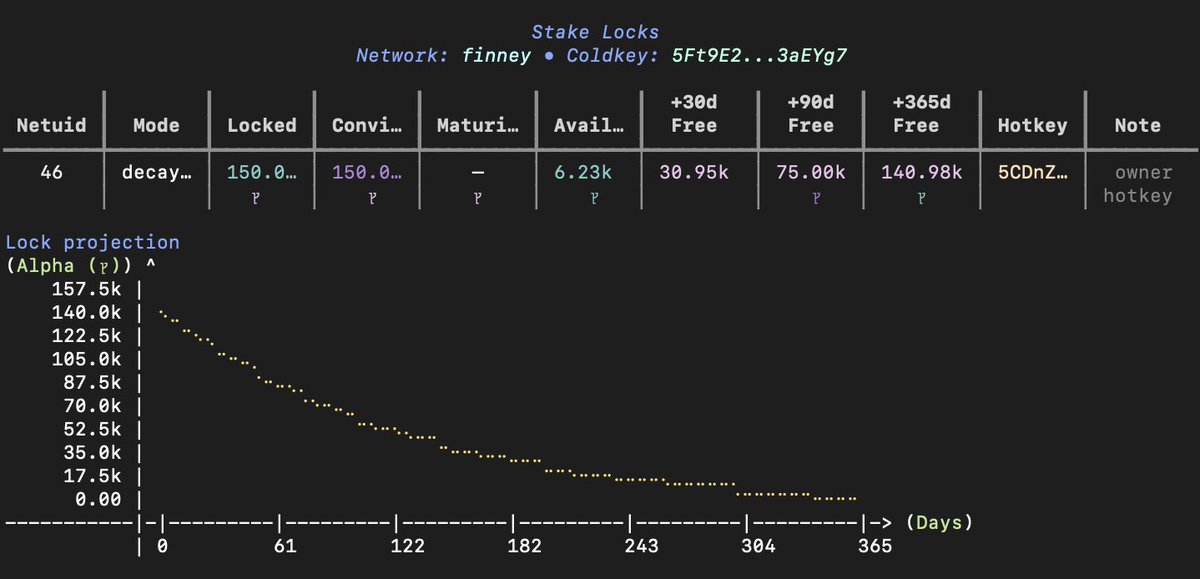
$TAO - Conviction is live. Keep an eye out: any subnets that lock up their holdings will send a strong signal to investors that they’re in it for the long haul, and there’s no way they’d ever dump 100% of their holdings all at once.
Conviction is now a synonym of trust! Forward.
Ditto will be locking 40,000 alpha into conviction.
For context, this is 100% of the alpha owned by the team.
Ditto is forever.
This is our conviction.
.@NBA, if you can describe what kind of AI you need,
our network will build it for you.
Not in years, not in months, but in weeks.
It will be more efficient, more affordable, more open than legacy tech and continuously optimised and improved.
Decentralised AI is the real world champion, dear Adam Silver.
We’ve been a bit quiet this week.
That’s because the “speed demons” have been building in the background.
Just know that tomorrow will be a great day for Ditto users.
At 12pm EDT tomorrow, our New Flagship Feature goes live alongside a pre-recorded podcast!
Stay tuned.
The ATH Is A Different Story Than You Think
$TIG hit its all-time high of $5.65 on August 14, 2024.
That was one day after it listed on Uniswap.
The protocol had been live for 9 months. Zero liquidity. Zero market. Benchmarkers earning tokens with no exit. Then it opened on a DEX and immediately traded up to $5.65.
That wasn't hype from influencers. There were almost no influencers. That was 9 months of suppressed price discovery releasing all at once on a DEX that anyone could access.
It then found its all-time low of $0.0264 on January 30, 2025 — five months later, during the depths of a brutal altcoin correction.
From $5.65 to $0.0264. Then back to where we are now — +6,169% from that low.
The team kept building through every single point on that chart. No pivots. No rebrand. No emergency tokenomics changes. Same protocol. Same mission. Same team.
That kind of price history either breaks a project or proves it. $TIG is still here.
https://t.co/PXOQ6l6VY6
https://t.co/0ejm7B3txq