I've permanently moved over to Mastodon & the Fediverse. It's got more of the things I want to see and contribute to and less noise to distract me.
https://t.co/gNk47VddW6
This is my last post here on Twitter. Hope to see you on the other side!
Before he steps down I’d just like to thank Elon Musk for shattering the myth that billionaires are smarter, more hard working, or simply any better than anyone else in the most public way imaginable.
@wordsandbuttons For the reader it's an individual pref. For the writers, it'd depend on their target audience / potential audience.
For ex, there's a reason why this thread is happening Twitter in the first place rather than via email
@wordsandbuttons Agree with the sentiment but IMO a huge factor = things that are colocated in the medium with posts one's interested in. ATM email for me is mostly a collection of receipts and system messages for other web things I use vs a place where to find / read content.
All done. Tcl is easy and a great DSL. Binary templates make it easy to apply RE findings to data of the same format. It can also highlight errors if the data doesn't match the format.
You can think of it as a schema for binary files: very useful.
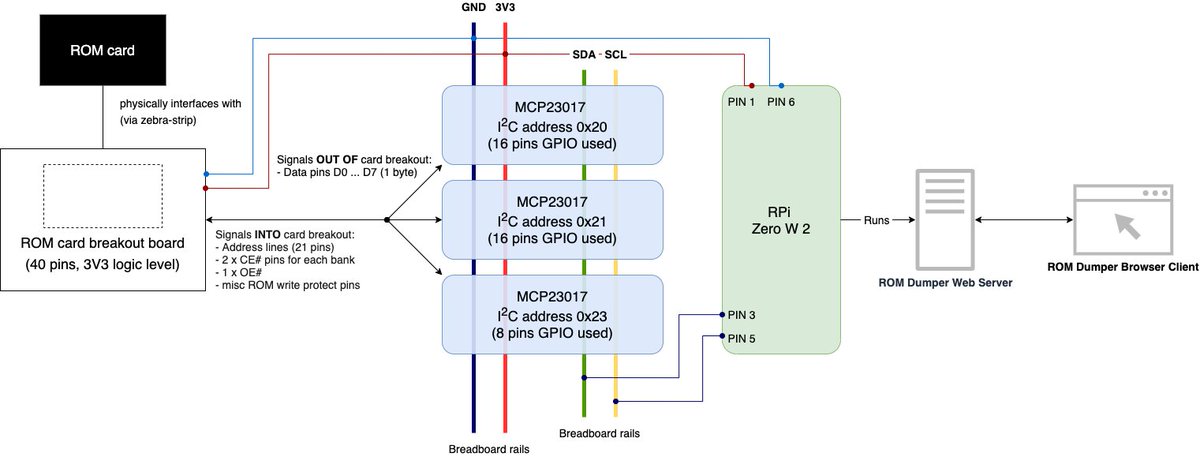
Have now resorted to using an unplugged 3D printer's z-rail as the physical compression method for the ROM dumper's card slot. It works and is more stable than a can of beans! #smallwins
Managed to figure out how to consistently extract Card Icons from the ROM files. Works 90% of the time, still have to catch some edge cases for a few ROMs. Pretty happy with the headway that's been made!
We’ll come full hilarious circle when people use LLMs both to 1) expand a simple message like “execute faster” into email and 2) summarize an email back into the original simple message. It’s like compression/decompression into formalese
Franklin Bookman ROM dumper tool V1 is now documented and open source. Some analysis notes included. You will need some hardware built to fully replicate results!
https://t.co/RQ4tSALZVH
There's a better vision of science where each paper is a living repository, where comments and critiques arrive as pull requests, and where the output in most cases is in the form of libraries of up-to-date, maintained code and data that can be built on by other scientists.