This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Claude Code creator:
"I don't prompt Claude anymore. I write loops - and the loops do the work. My job is to write loops."
in 30 minutes Boris reveals his actual daily Claude Code setup.
Claude Code + loops + dynamic workflow
Worth more than a $500 vibe-coding course
Andrej Karpathy: "90% of Claude's mistakes come from missing context, not a weak model."
41% mistake rate without a CLAUDE.md. 11% with the 4-rule baseline. 3% with the 12-rule version below
here are the 12 rules senior engineers settled on:
1. think before coding: state assumptions, don't guess. the model can't read your mind, stop hoping it will
2. simplicity first: minimum code, no speculative abstractions. the moment you let Claude add "for future flexibility," you've added 200 lines you'll delete next quarter
3. surgical changes: touch only what you must. don't let it improve adjacent code, that's how PRs blow up
4. goal-driven execution: define success criteria upfront, loop until verified. without them Claude either loops forever or stops too early
5. use the model only for judgment calls: classification, drafting, summarization, extraction. NOT routing, retries, status-code handling, deterministic transforms. if code can answer, code answers
6. token budgets are not advisory: per-task 4000, per-session 30000. by message 40 of a long debug, Claude is re-suggesting fixes you rejected at message 5
7. surface conflicts, don't average them: two patterns in the codebase? pick one. Claude blending them is how errors get swallowed twice
8. read before you write: read exports, callers, shared utilities. Claude will happily add a duplicate function next to an identical one it never read
9. tests verify intent, not just behavior: a test that can't fail when business logic changes is wrong. all 12 of Claude's tests can pass while the function returns a constant
10. checkpoint every significant step: Claude finished steps 5 and 6 on top of a broken state from step 4. nobody noticed for an hour
11. match the codebase conventions: class components? don't fork to hooks silently. testing patterns assumed componentDidMount, hooks broke them without surfacing
12. fail loud: "completed successfully" with 14% of records silently skipped is the worst class of bug. surface uncertainty, don't hide it
what actually compounds instead of the next framework:
- the CLAUDE.md file as institutional memory across sessions
- eval-driven changes, not vibe-driven
- checkpoints over speed
- explicit conflicts over silent blending
- discipline over framework, every time
- one repo, one rules file, no exceptions
be a few rules ahead of AI twitter before this becomes mass-opinion
study this
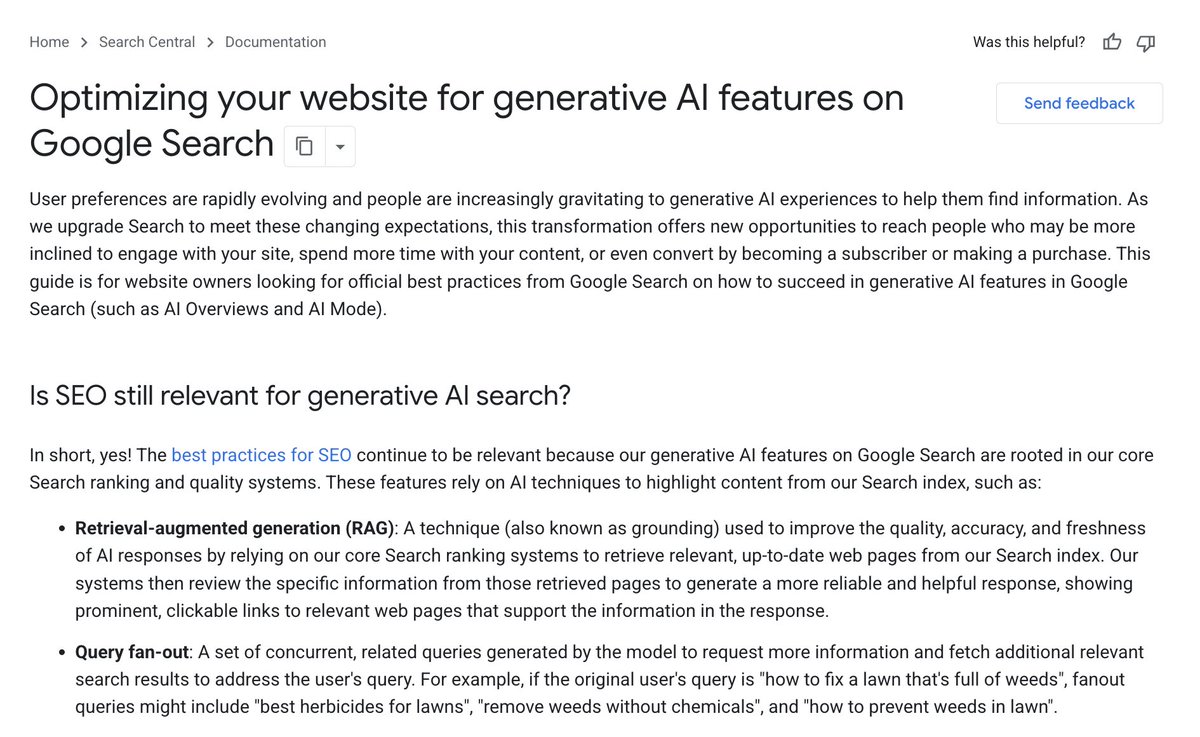
🚨 JUST IN - Google published a long piece about "Optimizing your website for generative AI features on Google Search" 👀
A lot in it https://t.co/22t75EtwUH
🧵
Love this reminder from @tfadell
"Makers often focus on the shiny object—the product they’re building—and forget about the rest of the journey until they’re almost ready to deliver it to the customer. But customers see it all, experience it all. They’re the ones taking the journey, step-by-step."
This is the most complete setup I've seen yet to turn Claude Code into your personal OS.
Here's my new episode with @moritzkremb where he shared the system that runs his email, content, and even grocery shopping.
We talked about:
→ The 4 layers: folders, tools, skills, routines
→ Memory: Set up a nightly "dreaming" job
→ Tools: The best CLIs and MCPs to use
→ Skills: Video edits, planning, and more
→ Routines: When to use local vs. remote
📌 Watch now: https://t.co/qimyGCQH9w
Thanks to our sponsors:
@WisprFlow: Don't type, just speak https://t.co/oqHJ8bN3ll
@linear: The AI agent platform for modern teams https://t.co/tgWf9oL4bs
Garry Tan (CEO of Y-Combinator): "when someone asks how I 'prompt' my AI, the answer is: I don't. the skills are the prompts."
[if I had 7 days to master skills and how to use them to automate workflows:]
→ read the Skillify 11-item checklist (SKILL.md in gbrain)
→ watch Murag + Barry Zhang: "Don't Build Agents. Build Skills Instead."
→ Read "Designing, Refining, and Maintaining Agent Skills at Perplexity"
→ do one workflow. type /skillify. watch it become permanent.
that's the whole day.
here is how to set it up:
1. clone GBrain (his open-source second brain, Postgres-backed memory + 30 skills)
2. add GStack (23 battle-tested slash-command skills, drops right in)
3. do anything once → type /skillify → it's a skill forever
prompting is dead. skillifying is next.
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
.@GoogleAI's subscription bundle is arguably the most successful consumer subscription in history.
They bundle Gemini, NotebookLM, Nano Banana, Veo 3, and terabytes of storage—with 150M+ subscribers generating many billions in revenue.
Here's the story behind how they designed the bundle, their unconventional freemium strategy, and many lessons learned: https://t.co/spmq8mSbpk
Introducing the /autobrowse skill (inspired by @karpathy's autoresearch harness)
Ask your agent to perform any task on the web: it explores the page using the @browserbase CLI, learns what went wrong in previous attempts, and iterates until it converges on a reliable workflow.
Once token usage is optimized, it graduates the winning approach into a reusable skill for your browser.
Google’s level of disrespect is OFF THE CHARTS right now.
Anthropic really thought they had us locked down with Claude Design’s ridiculous rate limits…
…and now Google has literally countered it straight away by open-sourcing DESIGN.md 🤯
Screenshot this. It is the architecture every agentic AI product converges on, and the answer to any AI system design interview.
Five layers. Memorize the stack.
Top: the interaction layer. This is where the user actually touches the product. Mobile app, web app, Slack integration, voice assistant, whatever the interface is. Most candidates forget to draw this and lose 5 points before they start. A system without a surface is not a product.
Second: the orchestration layer. The control plane. It decides which agent handles what, manages conversation state, enforces guardrails, and routes back to the user. Without it, you have loose agents with no coordination.
Third: three specialized agents. Never fewer. The data analyst agent handles structured prediction (churn classification, risk scoring, anomaly detection). The customer voice agent handles the conversation itself. The executor agent takes actions with real-world consequences (fires retention offers, updates records, issues refunds). Separating them lets each one be graded, tuned, and swapped independently.
Fourth: the data layer. Vector DB for retrieval, structured store for transactional data. RAG pipelines run through here. This is where the memory of the system actually lives.
Fifth: the model API layer. Called by any agent that needs inference. Abstracted so the team can swap between Opus, GPT-5, Gemini, or a fine-tuned open model without rewriting the agents.
Interviewers reward pattern recognition. The candidate who names the five layers and makes clean tradeoff calls inside each one wins the offer. XGBoost or LLM on the data analyst? Episodic or session memory in the data layer? Prompt-caching or full reload in the model layer? That is where the decision actually lives.
OpenAI averages $1.5M in stock grants per employee. This diagram is the entry ticket.
Full 40-min mock below. Watch the candidate build this architecture in real time starting at 22:30.
Some people think "leadership" is meetings, graduating from building.
True leadership in every organization from 2026 on out *is* building, and it won't be anything other than that into the future.
Either you're building or you're leting your org die slowly. Your choice
I'm giving away the Claude Code skills we use to manage $300k/mo in ad spend at ColdIQ.
4X ROAS on $1M+ spent.
Ivan, our head of growth, built them off 300+ hours running ad campaigns for our clients. They run Google, Meta, and LinkedIn ads from the terminal in plain English:
→ bulk edits across platforms
→ custom audiences from CRM lists
→ creative fatigue detection before CTR dips
→ bid adjustments at scale
→ performance audits across periods
Reply "ads" and I'll send the full repo. Must be following.