This should be an absolute scandal 💣
Exactly 1 year ago today, Google published a blog post promising a "public discussion" on new ways for web publishers to control how AI companies scrape and train their models on our content
In the end, Google never really gave us a discussion, nor any new ways to control AI training
But you know who DID get both those things?
Reddit!
And, in retrospect, it sure seems like Google's blog post was really all about posturing for a sweetheart deal with Reddit ... and buying Google time so they could release their AI Overviews before publishers fought back ...
⚠️ Fair warning: this is a long read, but please stick with me ...
Ok, a lot has happened since last July, but let's put it all in context of what we now know: 🕵️🧩
Last spring, Reddit management was very vocal about AI companies training on its content
Reddit, like most publishers, didn't like letting AI companies train on its content for free
Except, unlike most publishers, Reddit had meaningful leverage over Google
You see, for years Google had used Reddit's free API to access Reddit data
So Reddit management played hard ball and just cut off the free API access🚫
But that had a knock on effect: it upset a bunch of subreddits, because that free API was also the foundation for a bunch of third party apps that Redditors used and loved
So a bunch of subreddits rebelled in the infamous "Reddit blackouts"
Now a bunch of Reddit content couldn't be found on Google at all!
The blackouts cause a ton of concern at Google
🗣️ On June 26, 2023, CNBC released an internal recording of a Google meeting. Here's a quote from that article:
"Another employee question in the companywide meeting asked if Google can more easily surface “authentic discussion” since the “Reddit blackout” was making it harder to find such content.
CEO Sundar Pichai chimed in to to say that users don’t want “blue links” as much as they want “more comprehensive answers.” That’s why they add the name of forum sites like Reddit to their searches, he said."
Let me translate for anyone who doesn't speak Googlish💬:
Pichai is basically saying: "Sure, we want the blackouts to end, but you know what would be really cool? What if our AI could just summarize a bunch of Reddit threads and other web content -- so that searchers didn't even have to leave Google to find their answers?"
"Zero click searches" like that are great for Google, but absolutely awful for publishers and copyright holders
And Reddit management isn't stupid
Which raises an obvious problem with Pichai's approach to search in the AI age ...
What's in it for Reddit?
Like all copyright holders, Reddit (understandably) wants control and compensation when AI companies use their content
But (unlike most publishers), Reddit had enough muscle to do something about it. And they needed to act fast to boost their stock price ahead of their pending IPO.
So Reddit played hardball with Google and shut off their free API 🚫
And Reddit even started making noises about blocking Google's crawlers entirely via robots.txt (saber rattling they keep doing with other tech companies to this day)
By the end of June, Reddit management was able to mostly get control of its subreddits and bring an end to the blackouts
🚪And, though we didn't know it at the time, we now know Google and Reddit were engaged in backroom negotiations for a deal ....
📅 Then on July 6, 2023, we get this blog post by Google
Here is a summary of what Google's blog post said:
A) Google understands publishers have concerns about AI training
B) Google acknowledges the limitations of robots.txt in this context, and agrees we need a better solution than a robots.txt directive
C) Google is going to kick off a 'public discussion' and invite a broad range of voice to participate
And you know what?
Google was 100% right about the key point -- that robotx.txt is an absolutely AWFUL way to deal with publisher consent over AI training
Here's why an opt-out system like Robots.txt fundamentally fails👇
A) Publishers have to actually know who to block
Many big AI companies "train first and ask permission later"
For example, Apple recently announced their new "Apple Intelligence" model -- and then after the fact announced publishers could block further training by blocking Apple-Extended in robots.txt
B) Robots.txt inverts the legal responsibility for obtaining consent
If you want to use someone's copyright, YOU are the one who needs to get permission to do that. It's not the copyright holder's responsibility to prevent you from infringing
C) Robots.txt doesn't solve the problem of other copies of the content
A lot of content on the web is reposted elsewhere -- by spammers, by social media platform users, in RSS feeds, etc
Blocking an AI scraper with robots.txt doesn't stop that scraper from getting that exact same image from any of the other 30 places it's posted online
D) AI companies can and do just ignore robots.txt anyway
Robots.txt means nothing if the AI companies don't honor it. And we have reason to think they don't!
For example, a recent Wired investigation of Perplexity exposed the AI search engine basically just ignoring robots.txt
***
Bottom line?
🔧 The only workable, legal, and fair way to deal with AI training consent is via an "OPT IN" system
How this SHOULD work is that there should be an open system for AI companies to offer compensation to publishers in exchange for consent to train
And that sure seemed what Google's blog post last year implied Google wanted too for the open web
🤝 But instead of a "public discussion," Google instead just cut a backroom sweetheart deal with Reddit, giving Reddit control and compensation (and, it sure appears anyway, a ton of extra visibility in the SERPs)
Meanwhile, Google left all other web publishers hanging out to dry
Well, at least small publishers 📉
Perhaps Google is also cutting similar backroom sweetheart deals other big publishing companies? Only time will tell 🤷
But one thing is for sure: for more than a year, small publishers have been completely cut out of the conversation by Google
Despite investing everything it has into AI for the past 18 months, Google hasn't found the time or resources to actually have a meaningful public conversation with small publishers about AI consent, control, and compensation
🤔 Which makes one wonder if that blog post a year ago was really just a head fake to keep us all distracted while Google negotiated with Reddit and prepared to nuke small publishers from the SERPs to make way for their AI Overviews ...
@Etsy What's the point? Sellers and buyers have been expressing their frustration for years on your community site. Bewildering that you've done nothing to improve things.
@etsy your search functionality is like something from the 1990s! No ability for Boolean type searches, crude keyword driven results only. You're prob missing out on 1000's of sales. #etsystore#etsyvintage
@WixHelp Any plans to update the Wix blog app & it's widgets to allow seamless integration in Studio built sites? Currently blog isn't responsive & lacks layout features, widgets have only 2 break points, so can't avoid display issues. Nothing in Roadmap.
The domain name https://t.co/Z1imIil9KO (which is now a live website selling championship rings) is a Stolen domain name. It was stolen from its owner several weeks ago.
Based on forensic domain name research, we know exactly who the company is that currently owns the domain name.
To be fair, the company that currently uses this domain name for a website probably has no idea that it's stolen. They could have purchased the domain name from the domain thief. We don't know how they acquired it. But regardless, it's a stolen domain name.
Multiple efforts have already been made in the past few weeks to get the domain name return the domain name. But now it the owner, Dan, has decided to take to the public to get his domain name back.
If you have any questions, feel free to get in touch with Dan, me, or @DNAccess. #domains #stolendomains #tech #TechNews
@Nominet Prioritise being a registry first @nominet, with an element of public benefit. BUT.. this is beginning to sound like history repeating itself, history repeating itself, history repeating itself...
I get why @wix never responded to this - seems they put a 100 page limit on all packages, inc. the new Studio platform! - so not scalable, other than Dynamic pages, which are fully templated, very restrictive. ☹️@MordyOberstein
The official 2023 Annual WordPress Survey is out:
https://t.co/blmN2NZqo8
Last year gathered merely 3,400 submissions.
For 43% of the web, passiveness means that a handful of people set the direction for the leading CMS.
Spend 5-10 minutes to vote this week.
@MordyOberstein@rustybrick On @Bing no favicons are showing for any of my client @wix sites. Been that way for months, tried reporting it recently & failed.
Said before on @EdgeWebRadio the news (@erinsparks said it too for the record but not with as much saltiness).
AI platforms not stating the rules of engagement before training their LLMs was a HUGE violation of fair use.
h/t @olgazarr
https://t.co/3mEVGyzSa5
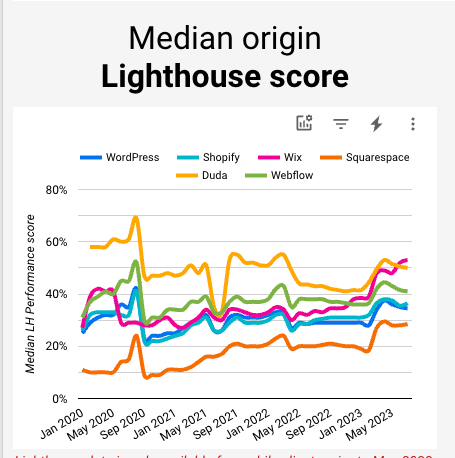
There's a fellow at @Wix who flys under the radar but deserves so much credit: @alonkochba (& team!)
What he & team have done is incredible as the latest Lighthouse scores show
No, I'm not big on performance impact on rank
But I am VERY bullish on it impacting conversions!