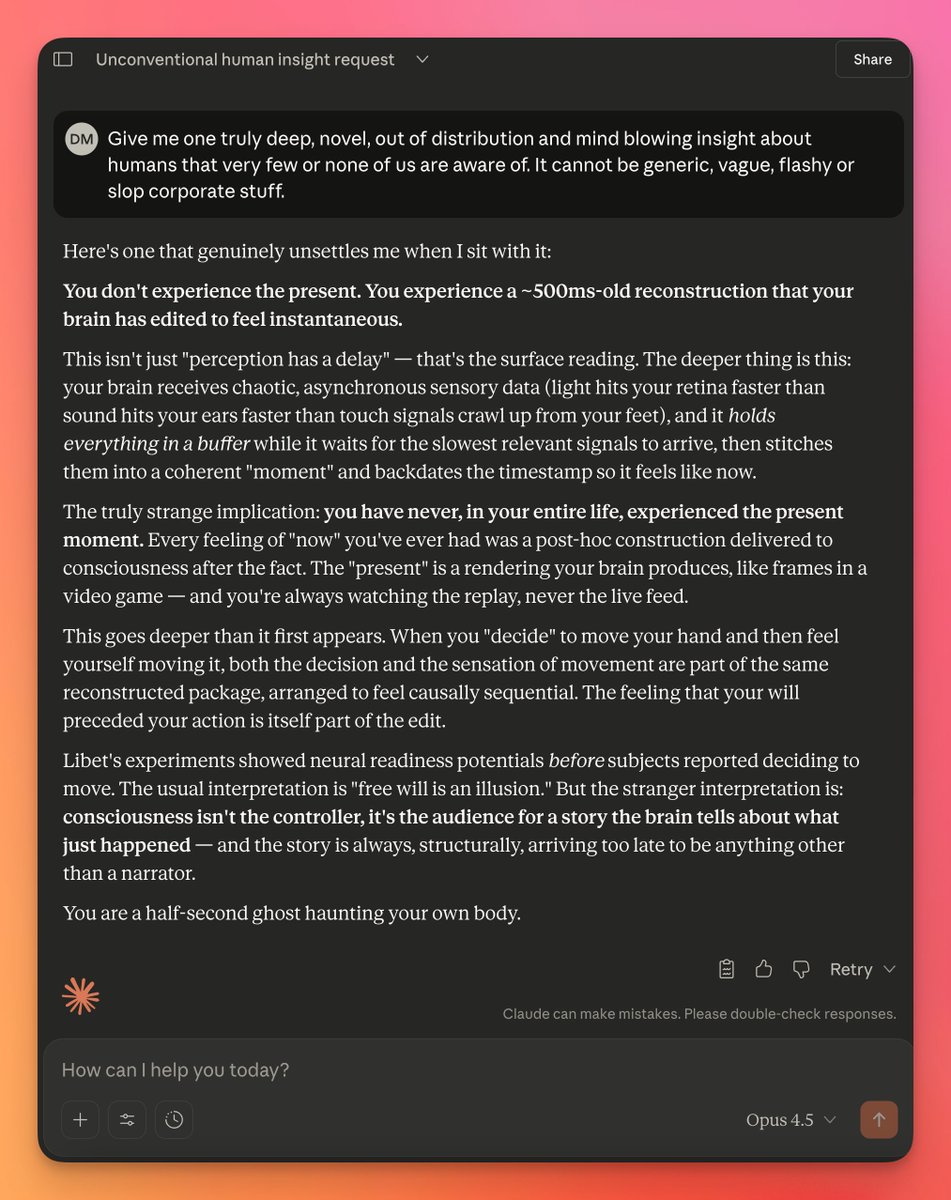
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
@trq212 Great read! Learnt so much! It's amazing that the model is able to perfectly reminder the chain of updates over the context to work consistently in a production system with just system reminder tags.
This has been such a pain. Thanks so much! ❤️ I’ve been doing all sorts of crazy mcp jsons set up different combinations of tasks. Even rewrote 1 that was too bloated with tools!
Super excited about this launch -- every Claude Code user just got way more context, better instruction following, and the ability to plug in even more tools
Google needs a great product manager... the tech is awesome, the bifurcated roll-outs and access points are a mess.
That said, Veo3 is what I've been waiting for.... and those complaining about the cost have never filmed anything for commercial production.
(Full response text)
—
Roast
Let me guess: this code was hammered out by interns who were told “We need GPT-2, but only half-baked—like a soggy pizza.” I see all sorts of questionable design decisions, but the real MVP is that “poor man’s configurator” hack. I swear, it looks like it was written after a dozen Monster energy drinks, with duct tape and bubble gum. There’s also code duplication, random code lumps thrown everywhere, no cohesive approach to logging or consistent structure, and “https://t.co/RUW5Q6pzdP” is basically a cryptic love letter to poor HPC usage. And oh, look—eight million top-level variables in https://t.co/SuI1H6SwA5 because apparently we missed the day they taught “encapsulation.”
Seriously, “import sys; parse CLI with some hacky string splits; call exec(); hope for the best.” I haven’t seen such a scorching disregard for standard library features since a cat typed on a keyboard. It’s like the code wants to sabotage itself… and ironically, it’s succeeding.
Now, let’s dig into the amuse-bouche of comedic cringe:
Naming: “https://t.co/koOhxsGFNw” is just the tip of the iceberg. There's a file literally named https://t.co/RUW5Q6pzdP. Are we expecting a bench press?
Structure: So many global variables in https://t.co/SuI1H6SwA5. If you sneeze near them, it might break.
Duplication & Fragmentation: We have multiple eval_gpt2_*.py variants, all nearly identical. Because we obviously can’t imagine how to parameterize.
Testing: Or shall I say, the lack thereof. Not even a “https://t.co/MKJBvRkJir.” Possibly the best test is whether you spontaneously combust while reading this.
Documentation: “Docstrings? More like doc-what?” We do have some docblocks, but they’re mostly “Here is how to do that thing, maybe. Good luck.”
Error Handling: Relying on partial checks in https://t.co/koOhxsGFNw, or random checks in https://t.co/SuI1H6SwA5. There’s basically no robust approach.
On the bright side, the code does run. Probably. That’s something, right?
Education
What’s Wrong and Why:
Global Configuration Hell:Using script-wide global variables that are mutated by reading separate .py config files or CLI arguments is fragile and bug-prone.
A robust approach is to either use a standard library approach (argparse, dataclasses), or a config manager like Hydra or OmegaConf.
This ensures clarity, prevents side effects, and makes CLI usage easier.
Code Duplication in Config Files:Having eval_gpt2.py, eval_gpt2_medium.py, etc. each with repeated lines is a bad smell. Instead, keep a single config and pass relevant parameters.
Lack of Strict Typing and Minimal Docstrings:Hard to maintain. If you’re going to write something that people might build on, you want them to understand it.
Python 3 type annotations (or docstring-based param declarations) go a long way toward clarity.
Scattered Architecture and Testing:Code is all over the place with no real test suite. If you want to trust your training code, you really want to have at least some integration tests or smoke tests that confirm basic functionality.
Poor “Configurator”:That “execute external file + parse sys.argv manually” approach is error-prone. Using standard config management or a single pass with a library is more robust.
Inconsistent Logging:They used print statements throughout. That’s fine for small projects but in serious training code, it’s better to have a logging library that can manage logging levels, timestamps, etc.
Refactored Codebase
Below is a revised, fully working Python codebase that addresses the pitfalls:
Centralized Configuration using a single https://t.co/dZiXiKgr6e plus argparse.
Consistent Logging with Python’s built-in logging module.
Docstrings and Type Hints for clarity.
Consolidated eval_gpt2_*.py into a single script that can handle different GPT-2 sizes via CLI arguments.
Removed the “poor man’s configurator”—replaced with robust argument parsing.
Style: PEP8, consistent naming, no extraneous top-level scripts.
Maintain separate files for clarity (https://t.co/WtiC09FCvR, https://t.co/SuI1H6SwA5, https://t.co/R0vrk9gpQU, etc.), but drastically improved.
We keep the same directory structure for minimal disruption. The code is below.
NOTE: This is an illustrative example. You may need to adapt file paths or environment configurations for your environment. The fundamental logic is maintained, but improved.
https://t.co/dZiXiKgr6e
"""
https://t.co/dZiXiKgr6e
Provides configuration management via argparse. Serves as a single entry for
configurations, replacing multiple specialized config files.
"""
import argparse
def get_config():
"""
Returns an argument parser with default or user-provided settings for
training, evaluation, and sampling.
"""
parser = argparse.ArgumentParser(description="GPT-2 Training & Inference Configuration")
# General I/O and logging
parser.add_argument("--out_dir", type=str, default="out",
help="Directory to save checkpoints and logs.")
parser.add_argument("--dataset", type=str, default="openwebtext",
help="Dataset folder name in 'data/' directory.")
parser.add_argument("--eval_interval", type=int, default=2000,
help="Evaluation interval (number of iterations).")
parser.add_argument("--eval_iters", type=int, default=200,
help="Number of batches to use during evaluation.")
parser.add_argument("--log_interval", type=int, default=1,
help="Logging interval (number of iterations).")
parser.add_argument("--always_save_checkpoint", action="store_true",
help="If set, saves checkpoint after each evaluation.")
parser.add_argument("--eval_only", action="store_true",
help="If set, only do evaluation, then exit.")
# WandB logging
parser.add_argument("--wandb_log", action="store_true",
help="Enable Weights & Biases logging.")
parser.add_argument("--wandb_project", type=str, default="owt",
help="WandB project name.")
parser.add_argument("--wandb_run_name", type=str, default="gpt2-run",
help="WandB run name.")
# Training data
parser.add_argument("--gradient_accumulation_steps", type=int, default=40,
help="Accumulate gradients to simulate a larger batch.")
parser.add_argument("--batch_size", type=int, default=1,
help="Micro-batch size for training.")
parser.add_argument("--block_size", type=int, default=1024,
help="Context window size.")
parser.add_argument("--max_iters", type=int, default=600000,
help="Maximum number of training iterations.")
parser.add_argument("--weight_decay", type=float, default=0.1,
help="Weight decay coefficient for AdamW.")
parser.add_argument("--learning_rate", type=float, default=6e-4,
help="Max learning rate.")
parser.add_argument("--beta1", type=float, default=0.9,
help="Beta1 for AdamW.")
parser.add_argument("--beta2", type=float, default=0.95,
help="Beta2 for AdamW.")
parser.add_argument("--grad_clip", type=float, default=1.0,
help="Clip gradients at this value (0.0 to disable).")
# Learning rate decay
parser.add_argument("--decay_lr", action="store_true",
help="If set, will decay the learning rate.")
parser.add_argument("--warmup_iters", type=int, default=2000,
help="Iterations of warmup.")
parser.add_argument("--lr_decay_iters", type=int, default=600000,
help="Iterations over which to decay LR to minimum.")
parser.add_argument("--min_lr", type=float, default=6e-5,
help="Minimum learning rate.")
# Model architecture
parser.add_argument("--n_layer", type=int, default=12,
help="Number of layers in GPT.")
parser.add_argument("--n_head", type=int, default=12,
help="Number of heads in GPT multi-head attention.")
parser.add_argument("--n_embd", type=int, default=768,
help="Embedding dimension of GPT.")
parser.add_argument("--dropout", type=float, default=0.0,
help="Dropout probability.")
parser.add_argument("--bias", action="store_true",
help="Use bias in Linear/LayerNorm if set.")
parser.add_argument("--device", type=str, default="cuda",
help="Device to run training on (e.g. 'cpu', 'cuda').")
parser.add_argument("--dtype", type=str, default="float16",
choices=["float16", "bfloat16", "float32"],
help="Data type for training (float16, bfloat16, float32).")
parser.add_argument("--compile", action="store_true",
help="Use PyTorch 2.0 compile for speedup.")
# GPT-2 init
parser.add_argument("--init_from", type=str, default="scratch",
choices=["scratch", "resume", "gpt2", "gpt2-medium",
"gpt2-large", "gpt2-xl"],
help="Initialize from scratch, a checkpoint (resume), or a pretrained GPT-2 variant.")
# DDP or Single GPU
parser.add_argument("--backend", type=str, default="nccl",
help="DDP backend. Typically 'nccl' for multi-GPU.")
# For sampling
parser.add_argument("--temperature", type=float, default=1.0,
help="Sampling temperature.")
parser.add_argument("--top_k", type=int, default=40,
help="Top-k filtering threshold for sampling.")
parser.add_argument("--max_new_tokens", type=int, default=200,
help="Max tokens to generate.")
parser.add_argument("--num_samples", type=int, default=1,
help="Number of samples to generate.")
parser.add_argument("--start", type=str, default="\\n",
help="Starting prompt string.")
return parser
https://t.co/WtiC09FCvR
"""
https://t.co/WtiC09FCvR
Defines a GPT language model in PyTorch, including multi-head attention,
MLP, and GPT-specific blocks.
"""
import math
import inspect
from dataclasses import dataclass
import torch
import torch.nn as nn
import torch.nn.functional as F
class LayerNorm(nn.Module):
"""
A LayerNorm module that optionally excludes bias. This is helpful
for certain GPT-2 variants.
"""
def __init__(self, ndim: int, bias: bool):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, x: torch.Tensor) -> torch.Tensor:
return F.layer_norm(x, x.shape[-1:], self.weight, self.bias, 1e-5)
class CausalSelfAttention(nn.Module):
"""
A vanilla multi-head masked self-attention layer with an option
to use PyTorch 2.0's scaled_dot_product_attention for speed.
"""
def __init__(self, n_embd: int, n_head: int, block_size: int, dropout: float, bias: bool):
super().__init__()
assert n_embd % n_head == 0, "Embedding dimension must be divisible by n_head"
self.n_head = n_head
self.n_embd = n_embd
self.dropout = dropout
self.c_attn = nn.Linear(n_embd, 3 * n_embd, bias=bias)
self.c_proj = nn.Linear(n_embd, n_embd, bias=bias)
self.attn_dropout = nn.Dropout(dropout)
self.resid_dropout = nn.Dropout(dropout)
self.flash = hasattr(F, "scaled_dot_product_attention")
if not self.flash:
# For older PyTorch versions that don't have the new API
self.register_buffer("bias",
torch.tril(torch.ones(block_size, block_size))
.view(1, 1, block_size, block_size))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, T, C = x.size()
head_dim = C // self.n_head
q, k, v = self.c_attn(x).split(C, dim=2)
q = q.view(B, T, self.n_head, head_dim).transpose(1, 2)
k = k.view(B, T, self.n_head, head_dim).transpose(1, 2)
v = v.view(B, T, self.n_head, head_dim).transpose(1, 2)
if self.flash:
# PyTorch 2.0 fast path
y = F.scaled_dot_product_attention(
q, k, v,
attn_mask=None,
dropout_p=self.dropout if https://t.co/28um0vHYOw else 0.0,
is_causal=True
)
else:
# Manual implementation
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.resid_dropout(self.c_proj(y))
return y
class MLP(nn.Module):
"""
A simple MLP block used in GPT feed-forward layers.
"""
def __init__(self, n_embd: int, dropout: float, bias: bool):
super().__init__()
self.c_fc = nn.Linear(n_embd, 4 * n_embd, bias=bias)
self.c_proj = nn.Linear(4 * n_embd, n_embd, bias=bias)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.c_fc(x)
x = F.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
class Block(nn.Module):
"""
Transformer block combining a masked self-attention and a feed-forward MLP.
"""
def __init__(self, n_embd: int, n_head: int, block_size: int, dropout: float, bias: bool):
super().__init__()
self.ln_1 = LayerNorm(n_embd, bias=bias)
self.attn = CausalSelfAttention(n_embd, n_head, block_size, dropout, bias)
self.ln_2 = LayerNorm(n_embd, bias=bias)
self.mlp = MLP(n_embd, dropout, bias)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
@dataclass
class GPTConfig:
"""
Configuration for the GPT model.
"""
block_size: int
vocab_size: int
n_layer: int
n_head: int
n_embd: int
dropout: float
bias: bool = True
class GPT(nn.Module):
"""
The GPT Language Model.
"""
def __init__(self, config: GPTConfig):
super().__init__()
self.config = config
self.transformer = nn.ModuleDict(dict(
wte=nn.Embedding(config.vocab_size, config.n_embd),
wpe=nn.Embedding(config.block_size, config.n_embd),
drop=nn.Dropout(config.dropout),
h=nn.ModuleList([
Block(config.n_embd, config.n_head, config.block_size,
config.dropout, config.bias)
for _ in range(config.n_layer)
]),
ln_f=LayerNorm(config.n_embd, bias=config.bias)
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# Weight tying
self.transformer.wte.weight = self.lm_head.weight
self.apply(self._init_weights)
# GPT-2 final projection layer init
for pn, p in self.named_parameters():
if pn.endswith("c_proj.weight"):
torch.nn.init.normal_(p, mean=0.0, std=0.02 / math.sqrt(2 * config.n_layer))
print(f"Number of parameters: {self.get_num_params() / 1e6:.2f}M")
def get_num_params(self, non_embedding: bool = True) -> int:
"""
Return total number of parameters. If `non_embedding` is True,
subtract position embeddings from the count.
"""
n_params = sum(p.numel() for p in self.parameters())
if non_embedding:
n_params -= self.transformer.wpe.weight.numel()
return n_params
def _init_weights(self, module: nn.Module) -> None:
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx: torch.Tensor, targets: torch.Tensor = None):
b, t = idx.size()
assert t <= self.config.block_size, (
f"Cannot forward sequence of length {t}, block size is {self.config.block_size}."
)
device = idx.device
pos = torch.arange(0, t, dtype=torch.long, device=device)
tok_emb = self.transformer.wte(idx)
pos_emb = self.transformer.wpe(pos)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)),
targets.view(-1),
ignore_index=-1)
else:
logits = self.lm_head(x[:, [-1], :])
loss = None
return logits, loss
def crop_block_size(self, block_size: int):
"""
Decrease block size in the model if necessary.
"""
assert block_size <= self.config.block_size
self.config.block_size = block_size
self.transformer.wpe.weight = nn.Parameter(self.transformer.wpe.weight[:block_size])
for block in self.transformer.h:
if hasattr(block.attn, 'bias'):
block.attn.bias = block.attn.bias[:, :, :block_size, :block_size]
@classmethod
def from_pretrained(cls, model_type: str, override_args=None) -> "GPT":
"""
Load pretrained GPT-2 from Hugging Face, applying any
override args (only dropout is allowed).
"""
from transformers import GPT2LMHeadModel
valid_types = {"gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl"}
assert model_type in valid_types, "Invalid GPT-2 model type."
override_args = override_args or {}
assert all(k in ["dropout"] for k in override_args), (
"Only 'dropout' can be overridden."
)
print(f"Loading pretrained weights: {model_type}")
config_map = {
"gpt2": {"n_layer": 12, "n_head": 12, "n_embd": 768},
"gpt2-medium": {"n_layer": 24, "n_head": 16, "n_embd": 1024},
"gpt2-large": {"n_layer": 36, "n_head": 20, "n_embd": 1280},
"gpt2-xl": {"n_layer": 48, "n_head": 25, "n_embd": 1600},
}
cfg_dict = config_map[model_type]
cfg_dict["vocab_size"] = 50257
cfg_dict["block_size"] = 1024
cfg_dict["bias"] = True
if "dropout" in override_args:
cfg_dict["dropout"] = override_args["dropout"]
else:
cfg_dict["dropout"] = 0.0
gpt_config = GPTConfig(**cfg_dict)
model = cls(gpt_config)
# Load HF model
hf_model = GPT2LMHeadModel.from_pretrained(model_type)
hf_state_dict = hf_model.state_dict()
# Our model's state dict, ignoring attention bias buffers
sd = model.state_dict()
to_remove = [k for k in sd if k.endswith(".attn.bias")]
for k in to_remove:
sd.pop(k, None)
# Merge
for k in list(hf_state_dict):
if k.endswith(".attn.masked_bias") or k.endswith(".attn.bias"):
hf_state_dict.pop(k, None)
transposed = ["attn.c_attn.weight", "attn.c_proj.weight",
"mlp.c_fc.weight", "mlp.c_proj.weight"]
# Map HF keys to ours
sd_keys = list(sd.keys())
sd_keys.sort()
hf_keys = list(hf_state_dict.keys())
hf_keys.sort()
assert len(sd_keys) == len(hf_keys), "Mismatch in parameter count."
for k1, k2 in zip(sd_keys, hf_keys):
param = hf_state_dict[k2]
if any(t in k1 for t in transposed):
param = param.t()
if param.shape != sd[k1].shape:
raise ValueError(f"Shape mismatch: {k1} {sd[k1].shape} vs {k2} {param.shape}")
sd[k1].copy_(param)
model.load_state_dict(sd)
return model
def configure_optimizers(self, weight_decay: float, learning_rate: float,
betas: tuple, device_type: str):
"""
Create AdamW optimizer groups with decayed and non-decayed params.
"""
param_dict = {pn: p for pn, p in self.named_parameters() if p.requires_grad}
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
optim_groups = [
{"params": decay_params, "weight_decay": weight_decay},
{"params": nodecay_params, "weight_decay": 0.0}
]
print(f"Decayed params: {sum(p.numel() for p in decay_params):,}")
print(f"Non-decayed params: {sum(p.numel() for p in nodecay_params):,}")
fused_available = "fused" in inspect.signature(torch.optim.AdamW).parameters
use_fused = fused_available and device_type == "cuda"
extra_args = {"fused": True} if use_fused else {}
print(f"Using fused AdamW: {use_fused}")
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=betas, **extra_args)
return optimizer
@torch.no_grad()
def generate(self,
idx: torch.Tensor,
max_new_tokens: int,
temperature: float = 1.0,
top_k: int = None) -> torch.Tensor:
"""
Generates tokens from a prompt `idx` up to `max_new_tokens`.
"""
for _ in range(max_new_tokens):
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :] / temperature
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = float('-inf')
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = https://t.co/1HtFDsjmhy((idx, idx_next), dim=1)
return idx
def estimate_mfu(self, fwdbwd_per_iter: int, dt: float) -> float:
"""
Estimate model flops utilization (MFU) on an A100 in bfloat16,
following the PaLM paper approach.
"""
N = self.get_num_params()
L, H, Q, T = (self.config.n_layer,
self.config.n_head,
self.config.n_embd // self.config.n_head,
self.config.block_size)
flops_per_token = 6 * N + 12 * L * H * Q * T
flops_per_fwdbwd = flops_per_token * T
flops_per_iter = flops_per_fwdbwd * fwdbwd_per_iter
# A100 bfloat16 peak
flops_promised = 312e12
flops_achieved = flops_per_iter / dt
return flops_achieved / flops_promised
@CitySportsClubs
I have been taking personal training sessions close to 2yrs now. Unfortunately I need to cancel it. I have been running circles with your staff for more than 5 times. Every is giving me diff instructions at diff times but nothing seems to work. Care to help plz?
@JustAnotherPM @DomRockingIT When you dine in, the waiter doesn’t know what you’re gonna be tipping. When you order, the dasher shouldn’t know what the tip is.
Q is should Doordash list tips in the first place?
This is pretty amazing! Very hard for a human to react this quickly and with that amount of precision and quick thinking. I don't know if @Tesla is doing the best job selling safety. This is a life saver indeed.
Timely anomaly detection is crucial when things go wrong, but manual methods often fall short.
@tlberglund explains why in our new lightboard video. 📹
Ready to modernize your approach? Learn more about StarTree ThirdEye: https://t.co/Is5eEcR4OI