Humans don’t just use tools — we invent them.
That’s the next frontier for AI agents.
At @SFResearch, we’re introducing WALT (Web Agents that Learn Tools) — a framework that teaches browser agents to discover and reverse-engineer a website’s hidden functionality into reusable tools.
Through a demonstrate → generate → validate loop, WALT systematically transforms web interactions into structured APIs — moving us closer to truly autonomous web intelligence.
We benchmark WALT on VisualWebArena and WebArena — discovering 50+ reusable tools across search, content management, and communication.
WALT hits 52.9% / 50.1% SOTA success, with 10–30% higher accuracy and 1.3–1.4× fewer steps.
Paper: https://t.co/Hm6ORanVWn
Code: https://t.co/akK25VuyDf
@virprabh@yutong_dai@jinggu4ai@luo_yanqi@silviocinguetta@LiJunnan0409@ZeyuanChen@stanleyran
🚀 Computer-using agents represent a powerful new paradigm for human-computer interaction. Over the past year, we’ve explored multiple approaches to tackle the key challenges in building robust CUA systems.
12/2024 we released Aguvis (https://t.co/PjO1FQn4Ck)
07/2024 we released GTA1 (https://t.co/wkCjfmXWC7)
Today, we introduce CoAct-1 — a hybrid agent that elevates coding to a first-class action alongside GUI manipulation. On OSWorld, CoAct-1 achieves a new SOTA score of 60.76%, becoming the first CUA agent to cross the 60-point mark.
Takeaways
- Treat code as an action, not just a tool call.
- Hybrid action space (code + GUI) reduces error accumulation and boosts reliability.
- New SOTA on OSWorld with better efficiency and broader applicability.
Paper: https://t.co/Pk7isDcsnd
Page: https://t.co/xwQl1KOEYJ
From Flow Generalists to Champions: Building #AgenticAI for Salesforce Automation💻 Introducing Enterprise General Intelligence (#EGI) models for Salesforce Flow automation!
Blog: https://t.co/RXELbt1Gzq
Unlike frontier LLMs that treat this as token generation, our EGI approach:
✅ Encodes enterprise domain knowledge in a custom DSL
✅ Trains in Flow Simulator with continuous self-improvement
✅ Achieves 50% relative improvement with 88% less data
EGI isn't just better AI—it's AI purpose-built for enterprise. 32% → 48% activation rate on complex flows proves it works.
#EnterpriseAI #FutureOfAI
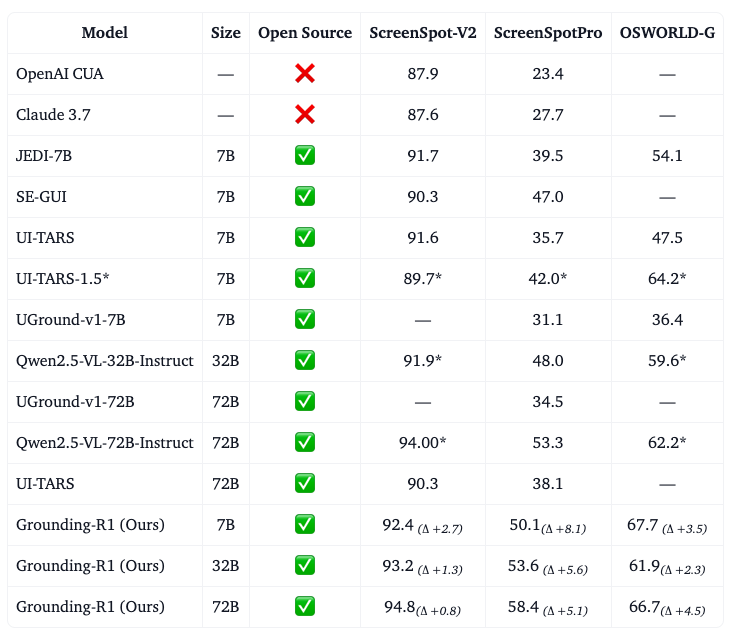
🚀 We’re open-sourcing Grounding-R1 — a series of SoTA models for GUI Grounding, trained with RL using a simple click-based reward.
🧠 Dive into our blog post: “GRPO for GUI Grounding Done Right” for the full training recipe.
https://t.co/MAznrgsbAf
🚨NEW MODEL: BLIP3-o 🚨
🔬 Researchers from @SFResearch + @ml_umd introduce BLIP3-o: solving AI's dual challenge of building ONE model that both understands AND generates images at SOTA level.
💡 Key innovation: dual-stage training with frozen autoregressive backbone prevents task interference - the model excels at both understanding and generation simultaneously.
🔓 Open source for the research community: https://t.co/dNOVoVT7R7
🤗 Model: https://t.co/mdldqMN1n2
💻 Demo: https://t.co/Tni7UVZD4X
📎 Blog: https://t.co/p5hhkcFXJg
🗞️ Feature: https://t.co/EMOtgsmgly
#FutureOfAI #EnterpriseAI #OpenScience @github@Marktechpost
We're thrilled to announce BLIP3-o, a breakthrough in unified multimodal models that excels at both image understanding and generation in a single autoregressive architecture! 💫
📊 Paper: https://t.co/M6oqNcyQqc
🤗 Models: https://t.co/pNwvTDbvsq
🧠 Code: https://t.co/lLmWFZxYjr
📽️ Learn on the go (AI Generated): https://t.co/2Cu4f8aRSI
Our research reveals that using CLIP features with diffusion transformer and flow matching creates superior performance while reducing computational complexity.
Most importantly, we're making this model family available to the AI Research community:
▶️ Complete model implementations
▶️ Model weights
▶️ 25M+ detailed caption pretrain dataset
▶️ 60K high-quality instruction tuning dataset
Advance your multimodal AI research and share your findings in the comments. (And thanks for the shout, @_akhaliq!)
🚨🎥🚨🎥🚨 xGen-MM-Vid (BLIP-3-Video) is now available on @huggingface!
Our compact VLM achieves SOTA performance with just 32 tokens for video understanding. Features explicit temporal encoder + BLIP-3 architecture. Try it out!
🤗32 Token Model: https://t.co/S9mVhyXrMP
🤗128 Token Model: https://t.co/1juefgvHcg
📄Paper: https://t.co/910sKM7h19
🖥️Website: https://t.co/kvwcwKPUVC
🧵Research Refresher 👇
#ComputerVision #OpenAI #AIResearch #VLM
(1/3)
Despite using much fewer tokens and being smaller (4B vs. 34B), xGen-MM-Vid provides comparable video question-answering accuracies to SOTA.
🔬🔬🔬Introducing ProVision: A new system for transforming images into verified instruction data for multimodal language models (MLMs) at massive scale!
Scene graphs + programmatic synthesis generate 10M+ diverse, automated Q&A pairs. Fully verifiable.
Training MLMs? Dive in:
📰Blog: https://t.co/ILrIENeThS
🗞️Paper: https://t.co/gR2FHx2WrB
💻Dataset: https://t.co/nt2BlmdE40
👇Researcher’s 🧵👇
(1/6) Why build ProVision?
Training multimodal LMs demands massive instruction datasets - pairing images with Q&As. Manual creation is costly, while using existing models risks hallucinations.
ProVision's novel solution? Scene graphs + human-written programs. We represent images as structured graphs capturing objects, attributes & relationships. We then use Python programs and textual templates, our data generators synthesize instruction data by creating questions and answers from the scene graph.
👇🧵 for more...
🚨🚨🚨Introducing PROVE: A new programmatic benchmark for evaluating vision-language models (VLMs).
VLMs often provide responses that are unhelpful, contain false claims about the image, or both. However, benchmarking this in the wild can be surprisingly hard! Enter PROVE, which:
💥 Includes challenging visual QA pairs that are *grounded by design*
💥 Provides a programmatic evaluation framework to quantify response *helpfulness* and *truthfulness*
🕹️ Explore: https://t.co/rHbey37C61
🤗 Data: https://t.co/E5bOC79aQo
📎 Paper: https://t.co/JCEmAuW7pF
🧵 Details in comments 👇
📢📢📢Introducing xGen-MM-Vid (BLIP-3-Video)!
This highly efficient multimodal language model is laser-focused on video understanding. Compared to other models, xGen-MM-Vid represents a video with a fraction of the visual tokens (e.g., 32 vs. 4608 tokens).
Paper: https://t.co/9333HUaQhE
Website: https://t.co/kvwcwKQsLa
Researcher’s 🧵:👇
Happy to see our team's hard work come to fruition. The xLAM family of models represents a huge leap in AI capabilities for function calling, planning and reasoning—fit-for-purpose for varied needs of modern business. Eager to see where its application takes us! #AIInnovation
Salesforce presents xGen-VideoSyn-1
High-fidelity Text-to-Video Synthesis with Compressed Representations
discuss: https://t.co/wm3SUGzxaF
We present xGen-VideoSyn-1, a text-to-video (T2V) generation model capable of producing realistic scenes from textual descriptions. Building on recent advancements, such as OpenAI's Sora, we explore the latent diffusion model (LDM) architecture and introduce a video variational autoencoder (VidVAE). VidVAE compresses video data both spatially and temporally, significantly reducing the length of visual tokens and the computational demands associated with generating long-sequence videos. To further address the computational costs, we propose a divide-and-merge strategy that maintains temporal consistency across video segments. Our Diffusion Transformer (DiT) model incorporates spatial and temporal self-attention layers, enabling robust generalization across different timeframes and aspect ratios. We have devised a data processing pipeline from the very beginning and collected over 13M high-quality video-text pairs. The pipeline includes multiple steps such as clipping, text detection, motion estimation, aesthetics scoring, and dense captioning based on our in-house video-LLM model. Training the VidVAE and DiT models required approximately 40 and 642 H100 days, respectively. Our model supports over 14-second 720p video generation in an end-to-end way and demonstrates competitive performance against state-of-the-art T2V models.
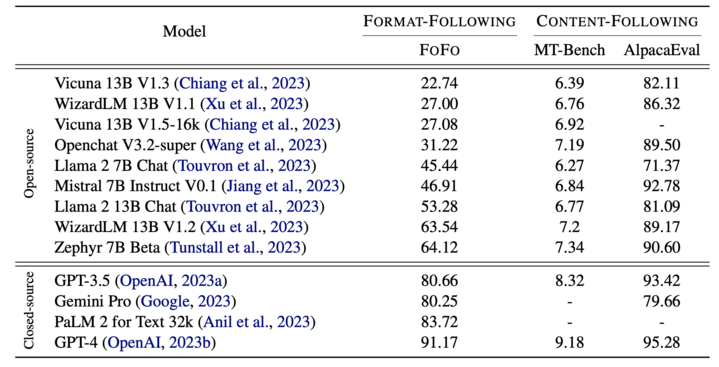
Excited to share our brand new LLM evaluation benchmark 🐠FoFo🐠 on format-following!
🐠FOFO🐠 is a pioneering benchmark for evaluating large language models’ (LLMs) ability to follow complex, domain-specific formats, a crucial yet under-examined capability for their application as AI agents.
Link: https://t.co/qBETnrar8r
Our evaluation across both open-source (e.g., Llama 2, WizardLM) and closed-source (e.g., GPT-4, PALM2, Gemini) LLMs highlights three key findings:
1. open-source models significantly lag behind closed-source ones in format adherence;
2. LLMs’ format-following performance is independent of their content generation quality;
3. LLMs’ format proficiency varies across different domains.
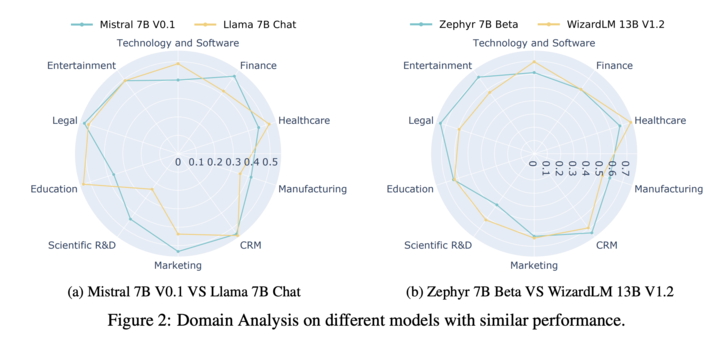
These observations suggest two key points:
i) The format-following capacity of LLMs appears independent of their content-following capacity shown in AlpacaEval and MT-Bench, and may necessitate specialized alignment fine-tuning beyond the conventional instruction-tuning of open source LLMs.
ii) Format-following capacity is not universally transferable across domains, highlighting the potential utility of our benchmark as a guiding and probing tool for selecting domain-specific AI agent foundation models.