Excited to present our #ICASSP2024 work ‘A Sound Approach: Using LLMs to Generate Audio Descriptions for Egocentric Text-Audio Retrieval’ which introduces egocentric text-audio retrieval benchmarks.
Poster: MLSP-P8.8 (Apr 16th, 16:30-18:30)
Paper: https://t.co/b4XL6wkXEU
Did you know, that you can build a virtual machine inside ChatGPT? And that you can use this machine to create files, program and even browse the internet? https://t.co/15IwHwr2on
How can one agent learn from demonstrations of a different agent?
Come check out our paper on cross-domain imitation learning at #NeurIPS2022 tomorrow at 11AM (Hall J #612).
Website: https://t.co/WWSd8JmTYS
Paper: https://t.co/zWNeu60yDx
We are presenting our work “Unsupervised Multi-object Segmentation by Predicting Probable Motion Patterns” today at #NeurIPS2022. Joint work w/ @subhc4, @irolaina, @chrirupp and A. Vedaldi. Come see us and have a chat at poster 427 today 4-6pm!
Excited to be at #NeurIPS2022 from Tuesday onward. We'll be presenting our work on unsupervised multi-object segmentation using motion cues.
Feel free to DM for a chat or if you are going out to explore NOLA, I am in! 😁
We use motion anticipation as a learning signal to train an image/video segmentation network unsupervised.
arxiv: https://t.co/gTWJgPHc3k
project page: https://t.co/wgIHZFmHmX
Here is a 5 minute video explaining our work! https://t.co/19SMdEZD1D
Happy to share that "Guess What Moves: Unsupervised Video and Image Segmentation by Anticipating Motion" has been accepted as a spotlight paper at BMVC 2022!
Work in collaboration with @LKarazija@irolaina Andrea Vedaldi and @chrirupp
Happy to share our "Temporal Alignment Networks for Long-term Video" in CVPR2022 (oral). Our model learns to align text and visual in untrimmed long videos without human annotation. We can get an auto-aligned web-scale video dataset for video representation learning! #CVPR2022
Come see us at Poster 217a, Session 2.1!
Work done @Oxford_VGG with @kaihan_vis, Andrea Vedaldi and Andrew Zisserman.
Project Page: https://t.co/E3un9FsLbY
Code: https://t.co/3emFwIp6b9
*Unsupervised Part Discovery from Contrastive Reconstruction*
#NeurIPS by @subhc4@irolaina @chrirupp Vedaldi
Beautiful paper on the automatic segmentation of an image into meaningful parts with only self-supervised objectives.
https://t.co/E6k87YRQ09
Check out our poster at @NeurIPSConf, we are at spot B0 in gathertown!
Unsupervised Part Discovery from Contrastive Reconstruction
@subhc4, @irolaina, @chrirupp, Andrea Vedaldi
⏰ Tue 7 Dec 16:30-18:00 GMT
🚩 gathertown : https://t.co/aJ690pawsa
🚩 page: https://t.co/r1zkVDpVoq
We propose a method for unsupervised discovery of semantically meaningful parts of objects using appearance consistency cues and contrastive learning. Work done in collaboration with Iro Laina, @chrirupp, and Andrea Vedaldi. To be presented at #NeurIPS2021.
Check out our latest work on “Segmenting Invisible Moving Objects” at @BMVCconf (w/ @WeidiXie and Andrew Zisserman)
Project page: https://t.co/ladZeSKFRa
Congratulations to @subhc4@irolaina @chrirupp and Andrea Vedaldi on receiving the Best Student Paper Award at @BMVCconf 🎉🎉
Check out the paper: "The Curious Layperson" https://t.co/hkZ2ItkiEV
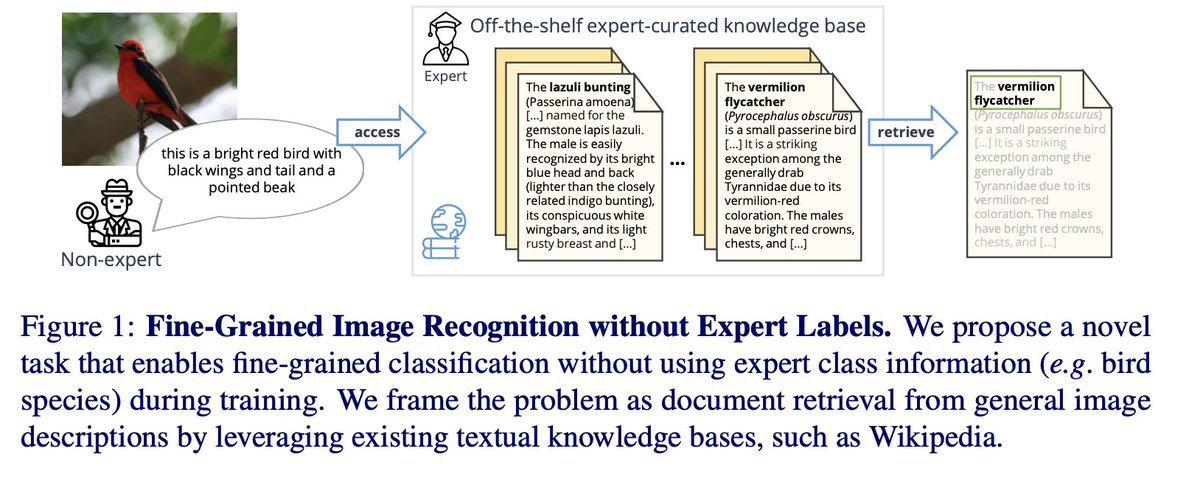
4/4 Whereas typically we train classification models on large datasets that have been annotated with precise expert labels, which are expensive to aquire. The difference between how humans approach this problem to how we train current models motivates us to propose this new task
1/4 We'll be presenting our work at @BMVCconf
"The Curious Layperson: Fine-Grained Image Recognition without Expert Labels"
@subhc4, @irolaina, @chrirupp, Andrea Vedaldi
⏰ Oral: Session 4 Tue 13:00-14:00 UK
⏰ Poster: Session 2 Tue 14:30-15:30 UK
🚩 Page: https://t.co/xttpcE7eer
3/4 We mimic how we constantly learn about new objects. Even when we cannot recognize some object we are still capable of describing it relatively easily. We can then consult expert resources, such as Wikipedia to match our observation and recognize the novel object.
We propose a new problem of fine-grained image classification without expert annotations - by utilizing class agnostic non-expert descriptions and off-the-shelf expert corpus. Shout out to my amazing collaborators Iro Laina, @chrirupp and Andrea Vedaldi. An oral in #BMVC2021.