Introducing Sweep Next-Edit, an open-weights 1.5B model trained to predict your next edit.
Sweep Next-Edit outperforms models 4x its size while being small enough to run locally.
We're open-sourcing the weights so the community can build fast, privacy-preserving autocomplete for every IDE.
New edit prediction providers just dropped in Zed: @_inception_ai, @sweepai, @ollama, and @GitHub Copilot NES.
We also simplified adding new providers. If there's a model you want to use in Zed, open a PR.
https://t.co/nxqQ79k9NA
🚀 We just shipped v0.222!
Edit prediction now supports multiple providers: @github Copilot's Next Edit Suggestions, @ollama, @mistralai's Codestral, @sweepai, and @_inception_ai's Mercury Coder.
https://t.co/nxqQ79k9NA
Results after implementing in Sweep Agent:
- 90% reduction in token usage for files >2,000 lines
- Faster response times (fewer tokens = lower latency)
- Reduced context rot
Try it in our JetBrains plugin: https://t.co/7ZK0kiDANr
And read the full blog here: https://t.co/PwEZjwXSub
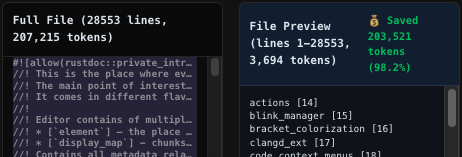
We decreased token usage for ultra-large files by 90%.
When navigating large files, coding agents use start and end line numbers, which either misses context or wastes tokens.
We used the JetBrains project structure to return structural outlines for large files, letting agents navigate precisely.
We optimized the outline format for token efficiency, which
Our initial format looked like this (15 tokens):
[...5 nested items, read lines 298-558 for details]
We found this format to be 30% more token efficient across the entire outline (9 tokens):
(5 children) [298:558]
For Zed's https://t.co/sIlxRhtA4J (207k tokens), our outline is only 3.7k tokens - a 98.2% reduction.
Introducing Sweep Next-Edit, an open-weights 1.5B model trained to predict your next edit.
Sweep Next-Edit outperforms models 4x its size while being small enough to run locally.
We're open-sourcing the weights so the community can build fast, privacy-preserving autocomplete for every IDE.
Download the model here: https://t.co/GGVU1Sbi6J
JetBrains users can try it now in the Sweep plugin:
https://t.co/pqDvcrECZV
Building for VSCode, Neovim, or your own editor? We'd love to see what you build.
Training pipeline:
1. SFT on ~100k examples from popular permissively-licensed repos (4hrs on 8xH100)
2. RL for 2000 steps with tree-sitter parse checking + size regularization
RL fixed edge cases SFT couldn't, like when the model generates code that doesn't parse or produces overly verbose outputs.