🚨 PSA 🚨
I’ve received reports of fake telegram messages impersonating me and fake Zoom calls using someone who looks like me.
I will never ask you to upgrade Zoom, install software, or click links.
If something feels off, hang up and text/email me directly. Most all of you have multiple ways of getting in touch with me, so 2FA.
Stay safe.
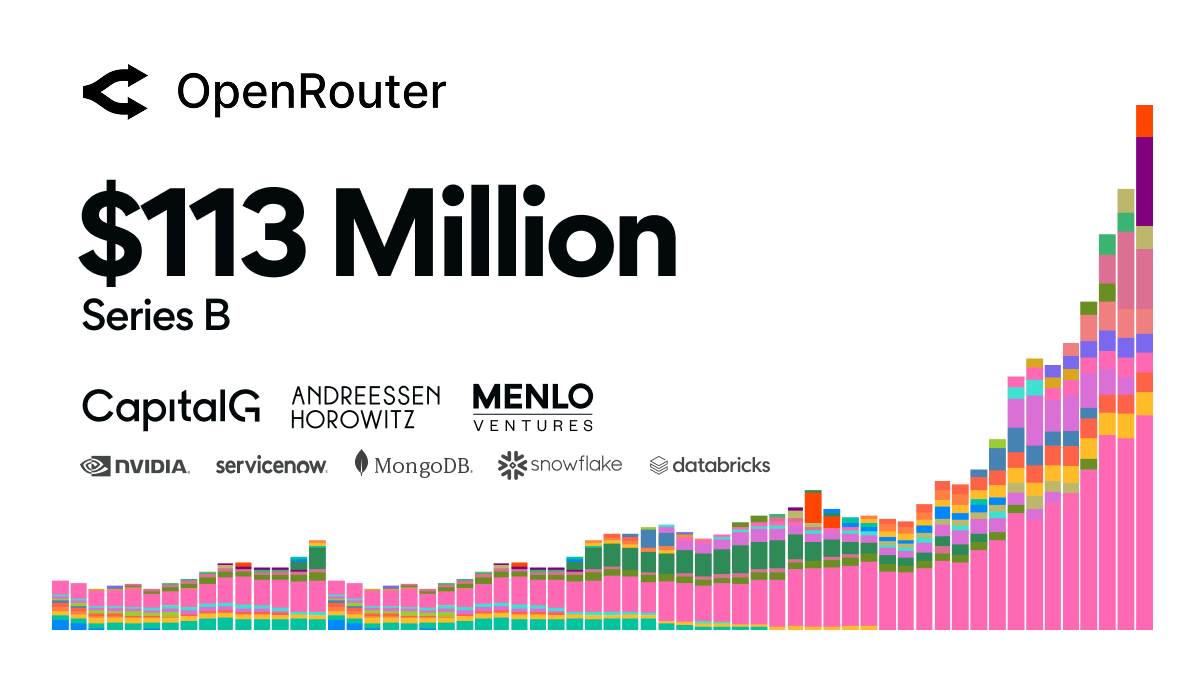
Today we’re announcing our $113M Series B led by @CapitalGVC.
Over the last 6 months, weekly volume on OpenRouter grew from 5T to 25T tokens as AI rapidly shifts from experimentation into production.
We’re excited for what comes next.
What’s happened is that we went from AI chat tools that were relatively cheap and had small context windows, to AI agents that have giant context windows, the ability to keep track of longer running work, and models that cost an order of magnitude more on inference because they’re that much better.
This has compounded far faster than most realized (unless you were paying close attention at the middle or end of last year, which many here were), and the dollars flowing in now are much more real.
What follows is a continued march of AI capability that will continue to be used by anyone with a frontier use-case (like coding, sciences, finance, consulting) and then a peeling off of tasks to lower cost models that are capable enough for the job. Whereas we thought the cost of AI might converge on a single low price per token before, it’s clear the stratification is only widening based on the task you need performed.
This will be yet another component that has to be figured out for broad AI diffusion. Enterprises will need to put in programs, new finance teams, and technology solutions to manage this all. The labs and platforms that can ensure customers can price optimize for the task at hand will be in the best position.
The interesting thing about falling token costs:
They don’t simplify decisions
They multiply them
More usage + more models + more variance =
continuous optimization becomes the product.
AI tokens are quietly becoming the unit of production.
Once that happens, the important question shifts from:
“which model is best?”
to: “which model should handle this task, at this moment, at this price?”
That’s a very different layer of the stack.
Falling token costs don’t compress margins
They expand them
Because value per token is rising faster than cost is falling
That’s why model labs are winning… for now
Great article @SemiAnalysis_ https://t.co/k3qXLLgteK
AI value is shifting from GPUs → model labs.
But the real shift hasn’t happened yet.
As tokens become the unit of production, the bottleneck becomes:
→ deciding which model to use, when
The control point moves to routing.
Three companies quietly control one of the biggest bottlenecks in AI.
Not chips.
Not models.
Memory.
This will matter more for geopolitics than most people realize.
Memory used to behave like a commodity.
It now behaves like infrastructure.
Few suppliers.
Massive capex.
Multi-year timelines.
Strategic choke points.
Treat it like oil or power
20,000,000 Bitcoin have now been mined.
Only 1,000,000 BTC left to be created. Ever.
But because of halvings, that last 5% will take ~114 years to issue.
~94% of all BTC already exists.
The remaining supply will trickle out slower and slower until ~2140.
Perfectly predictable monetary policy.
No committee. No bailouts. Just math.
People keep asking when the AI memory cycle peaks.
Wrong question.
This is not 2018.
Supply is tighter.
Scaling is harder.
Demand is non-linear.
Cycles driven by physics last longer than cycles driven by optimism.
For decades, memory was deflationary.
Smaller nodes. Cheaper bits. Rinse, repeat.
That era is over.
Memory pricing is now driven by physics, capex discipline, and long lead times.
That changes everything about AI economics.
Everyone is blaming AI datacenters for rising electricity bills.
But the data suggests something more nuanced: the biggest driver may actually be electricity market design, not AI demand.
Two regions illustrate this clearly: PJM vs ERCOT.
PJM operates the grid across 13 eastern US states. It uses a system called a capacity market, where power plants are paid to be available in the future during peak demand events. The price for that capacity is determined in auctions that rely heavily on forecasted demand for electricity years in advance.
When PJM modeled future load growth from AI datacenters and hyperscalers, those forecasts shifted the auction curve dramatically. Capacity prices jumped 9.3×, which is now flowing through to consumer electricity bills.
The result: households in the region could see ~$25–30/month higher power costs compared with a few years ago.
Now look at Texas (ERCOT).
ERCOT does not run a capacity market. Instead it uses real-time scarcity pricing. Electricity prices rise only when supply actually gets tight, rather than being determined by forecasts of future demand.
Texas is also experiencing enormous AI datacenter expansion. Hyperscalers, AI labs, and GPU cloud providers are all building major infrastructure there.
But electricity prices in ERCOT have increased only modestly, roughly in line with normal market movements.
Same AI boom. Completely different price outcomes.
The difference is that PJM’s system allows forecast models of future demand to directly influence prices, while ERCOT’s system relies more on actual supply and demand signals in real time.
This doesn’t mean datacenters have no impact on power systems. They absolutely do. But the evidence suggests that how electricity markets translate demand into prices matters just as much as the demand itself.
As AI infrastructure scales globally, the competitive advantage for datacenter regions may not just be cheap electricity or available land.
It may be how their power markets are structured.
In other words, the bottleneck for AI infrastructure might not be electricity.
It might be energy policy.
“Green data center” is marketing until regulators define it.
Bring your own power, emissions plan, and community upside
or expect rejections to accelerate.
The neocloud pivot is obvious in hindsight:
GPUs → managed training → managed inference → production SLAs
Compute without operational context is a race to zero.