At CVPR this week for a talk on neural geometry of large vision models. If you’re interested in interpretability or joining @GoodfireAI, come say hi. 🤠
Very excited to have this paper out! We show by having more parameters, larger models see reduced interference between updates. This allows them to retain memories of rarely observed samples of a task, eventually allowing them to learn even the tail-end of the distribution. (1/3)
We take for granted that larger models are better than smaller ones, but why is this so? Our new paper, led by Jing Huang and @EkdeepL, traces this to a data-induced competition for resources (neurons), using formal analysis, idealized tasks, and real pretraining.
Submit your work! The 2nd Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at COLM 2026 in San Francisco!
Submission Deadline: June 21, 2026
@ActInterp
What is the role of text tokens in diffusion? Do they carry anything beyond the text prompt? We study this in FLUX.2 @bfl_ml for the task of reference-guided generation, and found that text tokens hold visual information from the reference image!
FLUX.2's @bfl_ml text tokens aren't just holding your prompt.
During image editing, they absorb reference image content, and some of that absorbed content, like color and style, causally drives the output appearance.
New paper 🧵👇
Submit your work! The 2nd Workshop on 𝐀𝐜𝐭𝐢𝐨𝐧𝐚𝐛𝐥𝐞 𝐈𝐧𝐭𝐞𝐫𝐩𝐫𝐞𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲 will be held at COLM 2026 in San Francisco!
Submission Deadline: June 21, 2026
@ActInterp
SAEs remain useful, as long as we’re aware of their limitations.
And we have new techniques in the works that recover manifolds more directly, allowing us to understand models better and control them more effectively!
Read the full post here: https://t.co/KIDlJl19mW
This helps explain why SAEs can feel both illuminating and unsatisfying!
Looking at SAE features one-by-one is like trying to understand the proverbial elephant by talking with each of the blind men: each label may be locally accurate, but the global structure is missing. (5/7)
This would provide a great explanation for why there is so much redundancy in SAE features at any given layer (observation made by @Sauers_ ).
For example, if you search through the Qwen3-4b transcoder feature labels provided by Neuronpedia, there are 139 features generically related to the concept of 'color' in just layer 14. There are even more if you consider specific colors such as 'blue' or 'green', and this redundancy is repeated across layers... making it very annoying to interpret raw circuit graphs without performing some form of clustering.
Consider the parable of the blind men encountering an elephant for the first time. Each touches a different part—the trunk, the tusk, the leg—and comes to a different conclusion about the elephant: one says it's like a tree, another says it’s like a rope, and so on. (2/7)
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
Super excited to have this paper finally out! So many nuggets here, but a critical highlight: you should *not* interpret SAE features in isolation. The population geometry is where it's all at! Similar to this image of us @GoodfireAI folks playing out the elephant parable. :P
How do SAEs capture concept manifolds? 🍩
I think this is important work.
we study how SAEs handle the geometric structures we've identified and find they tile/shatter them in a particular way we characterize, letting us recast unsupervised manifold discovery as inverse Ising
The most popular way to interpret AI is missing the bigger picture.
Models think in curved shapes. But sparse autoencoders (SAEs) work with straight lines.
Can they still capture models’ curved neural geometry? Yes, but not how you might think! (1/7)
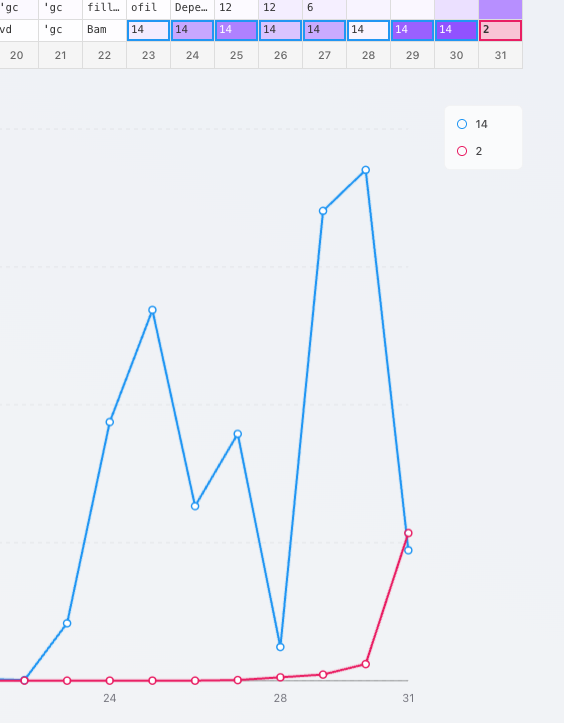
When @sheridan_feucht first told me about these results I was kind of skeptical, until they mentioned I can trace the modulo base-10 addition in Llama 8B just using Logit Lens. 🔍
So I opened https://t.co/h9fWNZMGY4 to check it out myself, and this is what I saw: